





超详细的 Stable Diffusion ComfyUI 基础教程(四):图生图流程

扫一扫 
扫一扫 
扫一扫 
扫一扫
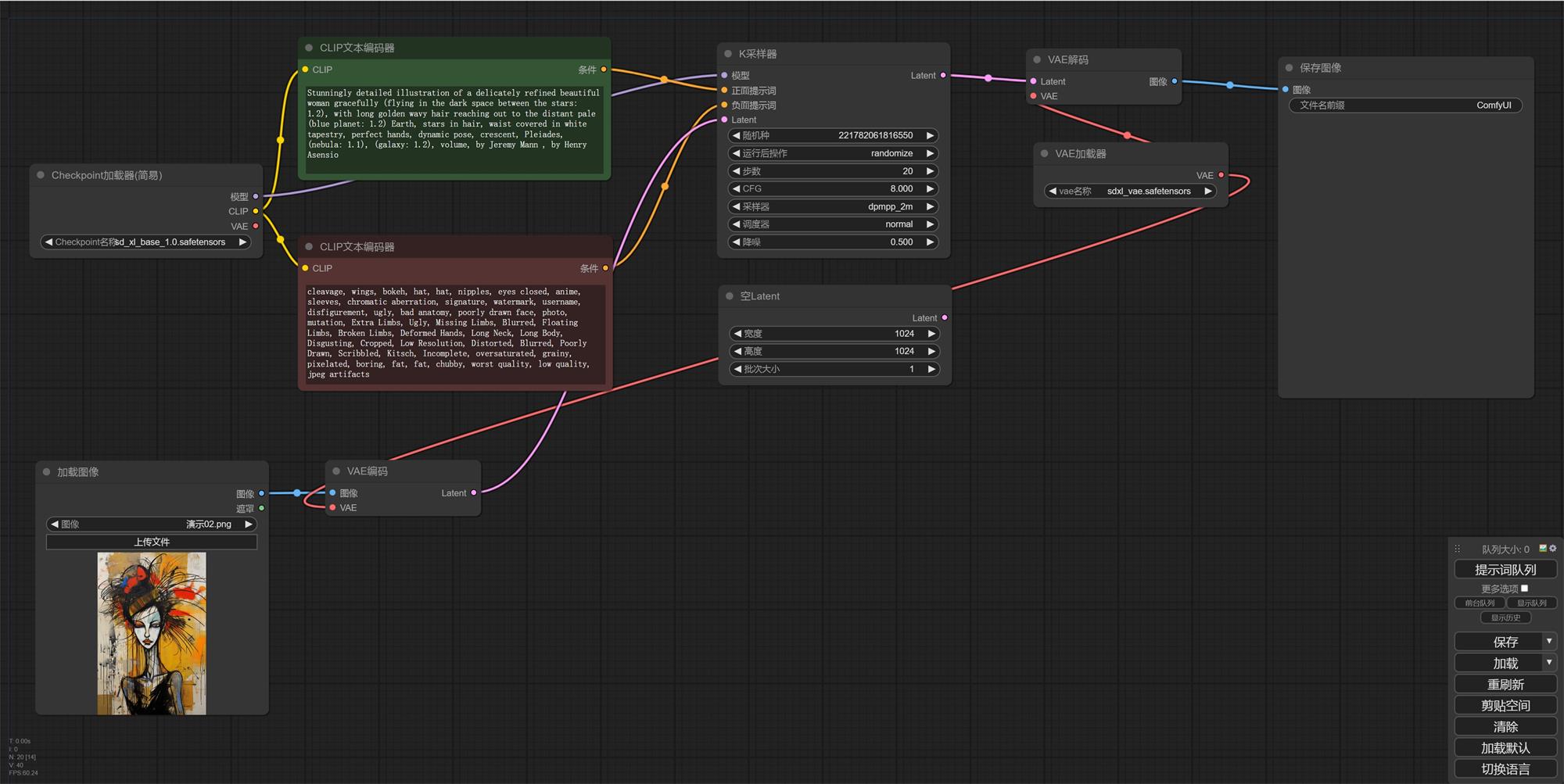
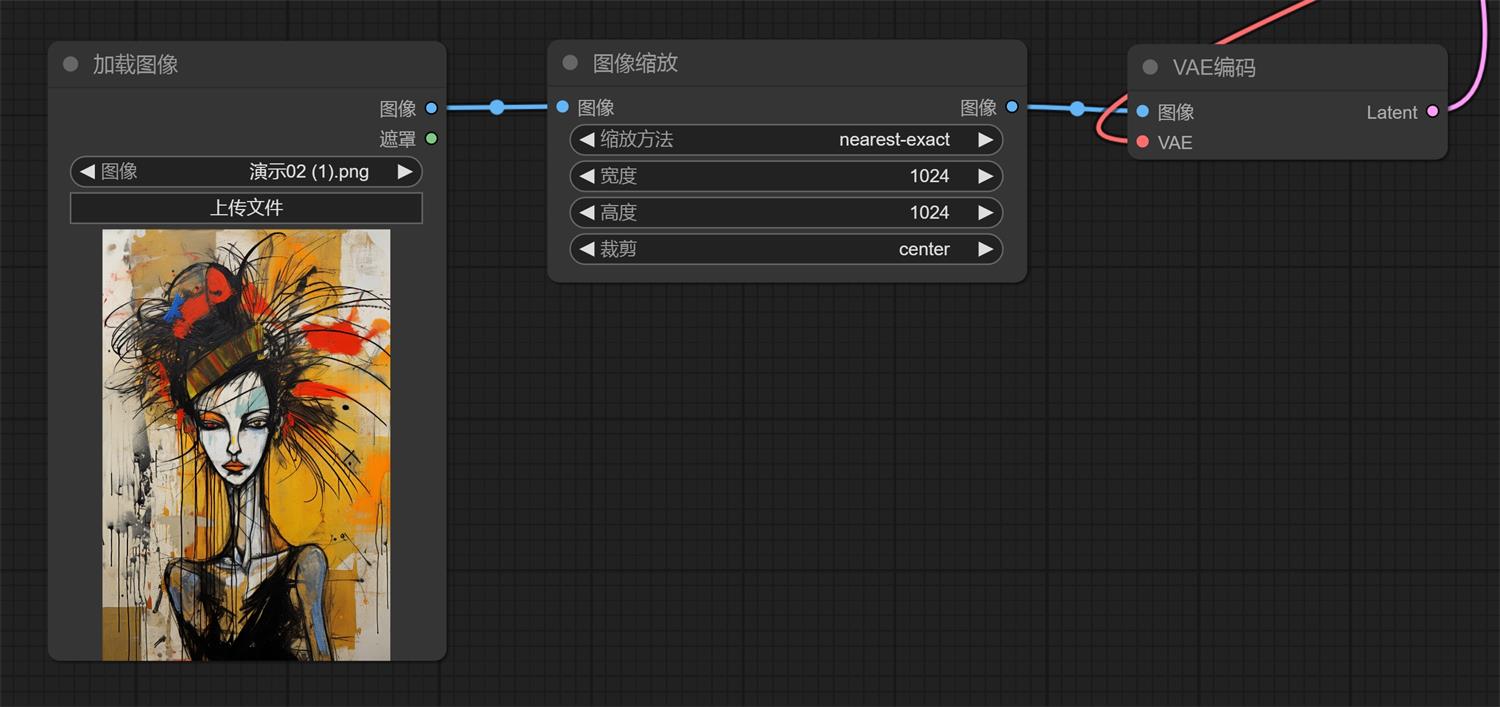
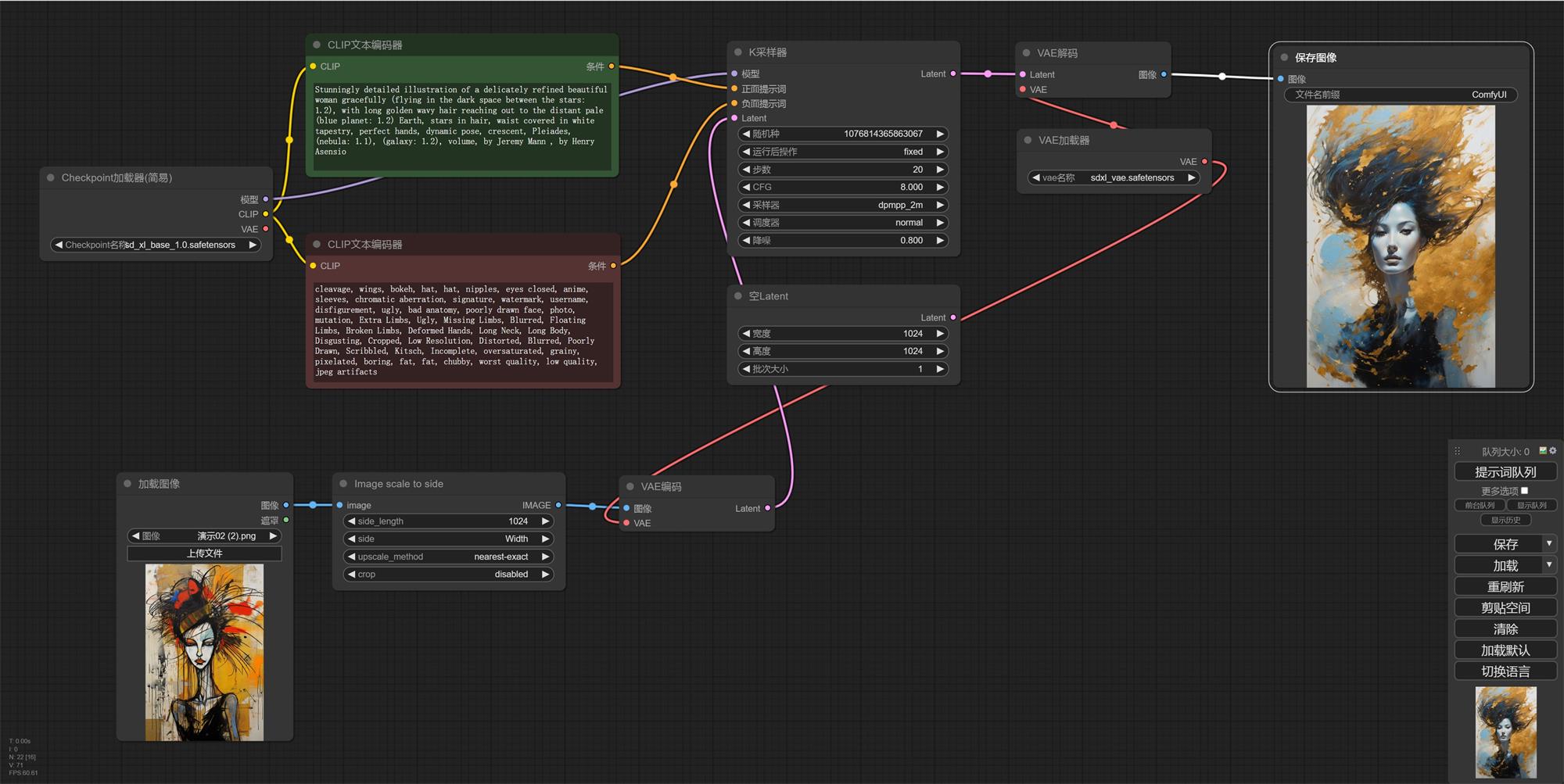
想一下,在我们使用 web UI 图生图的时候,他比文生图多了什么,是不是多了个加载图像的位置。 我们怎么才能把图片转成可以被识别的信息呢,我们需要把图片解码成可以被识别的信息。 上期回顾: 超详细的 Stable Diffusion ComfyUI 基础教程(三):Refiner 细化流程前言: 上节课我们学习了文生图的基础流程,接下来我们玩个复杂的,把 refiner 模型串联进去。 阅读文章 >一、创建流程1. 同样,我们先打开文生图基础流程,我们这个基础上把图生图流程加进去; 2. 我们“右键——新建节点——图像——加载图像”,然后把图片传上去; 3. 我们在加载图像上鼠标点击住“图像”往外拉,松开然后选择“VAE 解码”; 4. 我们再把“VAE 解码的 Latent”和“采样器的 Latent”链接,“VAE”连接到“VAE 加载器”;
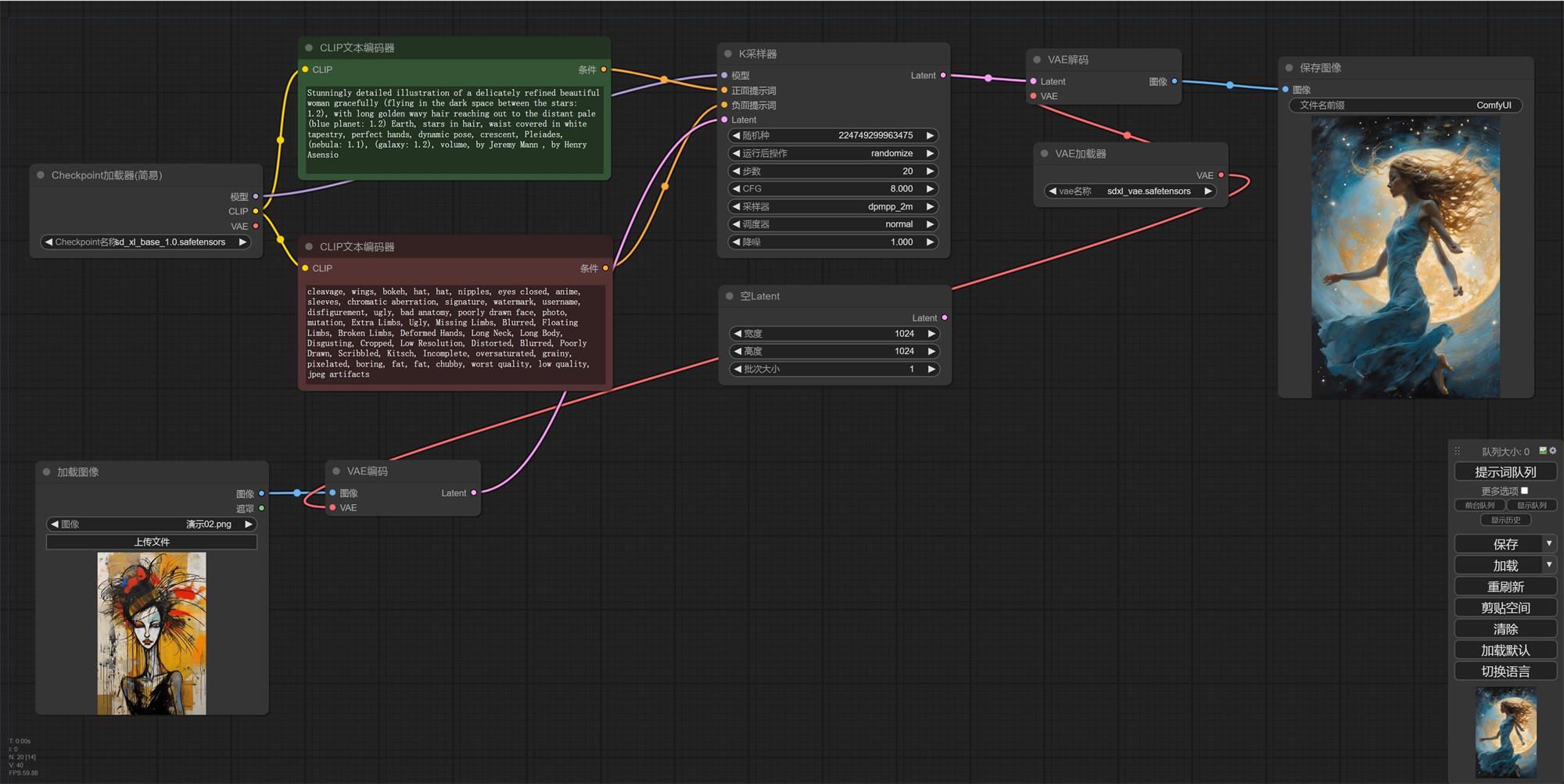
5. 这时候我们会发现两个问题,“加载图像的遮罩”没有连接任何节点,这个没关系,我们在使用局部重绘的时候才使用这个功能,图生图用不到。还有个就是原本的“空 Latent”断开了,是的,我们不能设置尺寸了,这个情况下会按照你上传的图片尺寸为基础。我们先出图看一下吧。
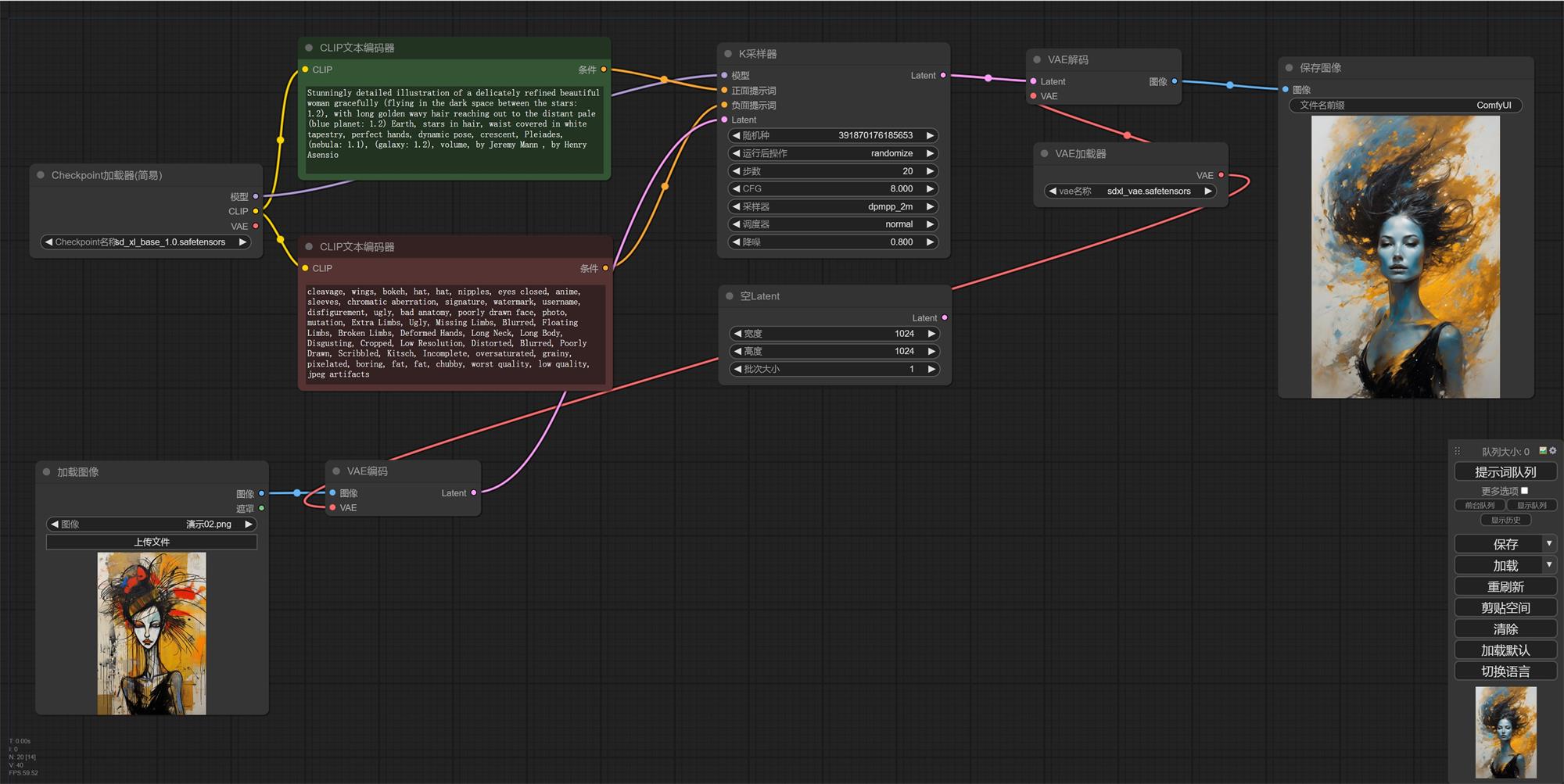
6. 有没有发现,我们出的图只是引用了图片尺寸,出图内容和上传的图片没有任何关系。大家还记得我们之前讲过的采样器里面的降噪吗,我们现在的数值是 1,他会 100%按照我们的文字描述出图。降噪数值越低和原图越接近,越高权重越偏向文字描述(我们一般会使用 0.5-0.8)。 7. 他的原理就是把已有的图像特征放进去再去做去燥迭代,0.8 就是我们跳过 20%的步数,用其余 80%的步数在原有图像噪点上进行文生图。
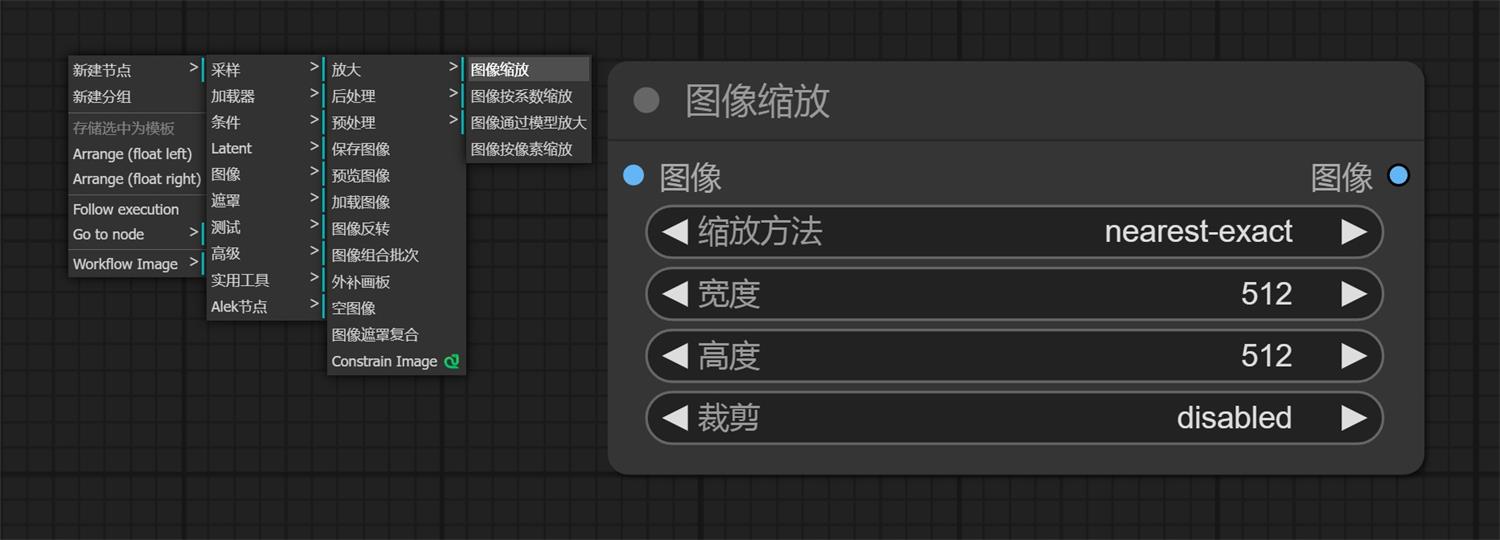
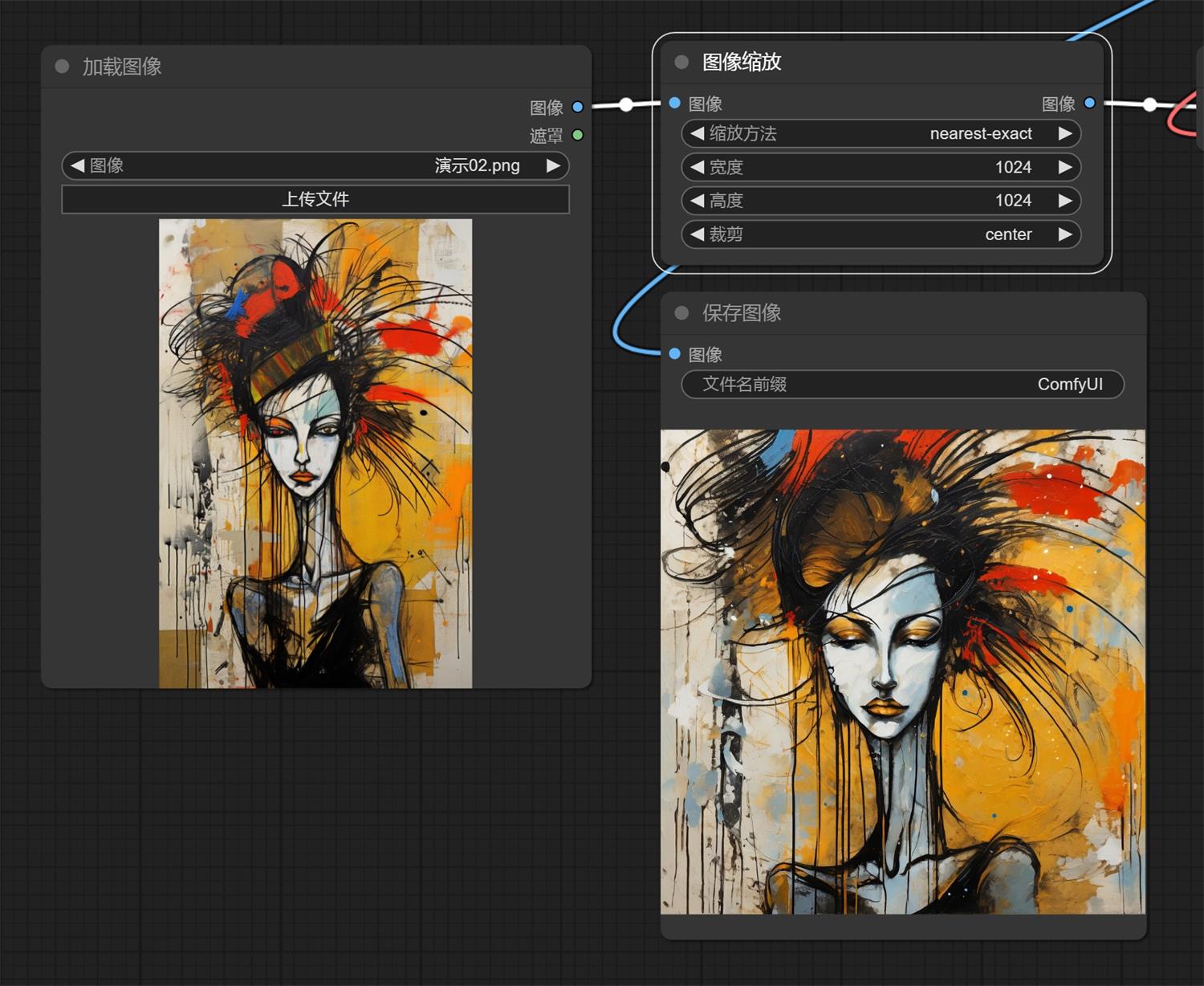
二、调整尺寸1. 我们前面说没有连接“空 Latent”,不能设置尺寸了,这个情况下图片特别大或者特别小都会出问题; 2. 我们“右键——新建节点——图像——放大——图像缩放”,并把他连接在“加载图像”和“VAE解码”中间。
3. 我们看到有四个可以设置的参数,除了缩放方法外(三种缩放方法,区别不是太大,我们使用时默认不修改即可),中间两个是宽高。最后一个是裁剪,但是有两种裁剪方式: a. disabled:直接拉伸(我们以一张 1024*1536 变成 1024*1024 为例)
4. center:根据中心进行裁剪(我们以一张 1024*1536 变成 1024*1024 为例)
5. 这两种裁剪方式都有个问题:
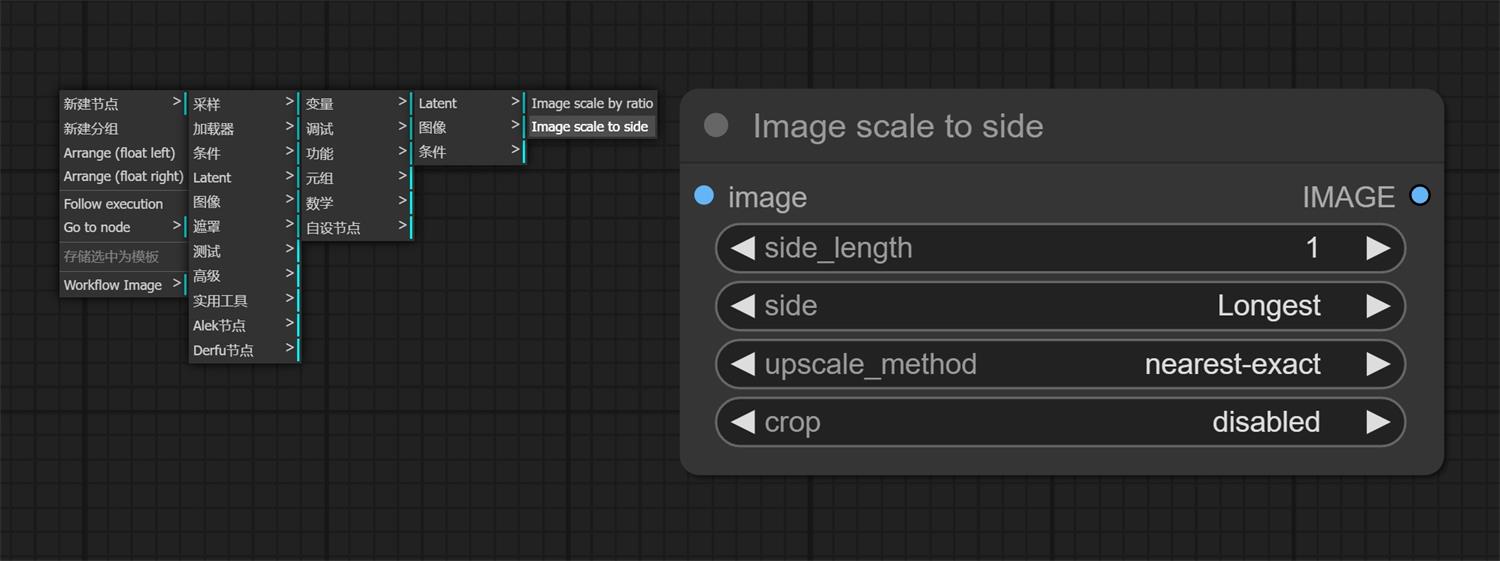
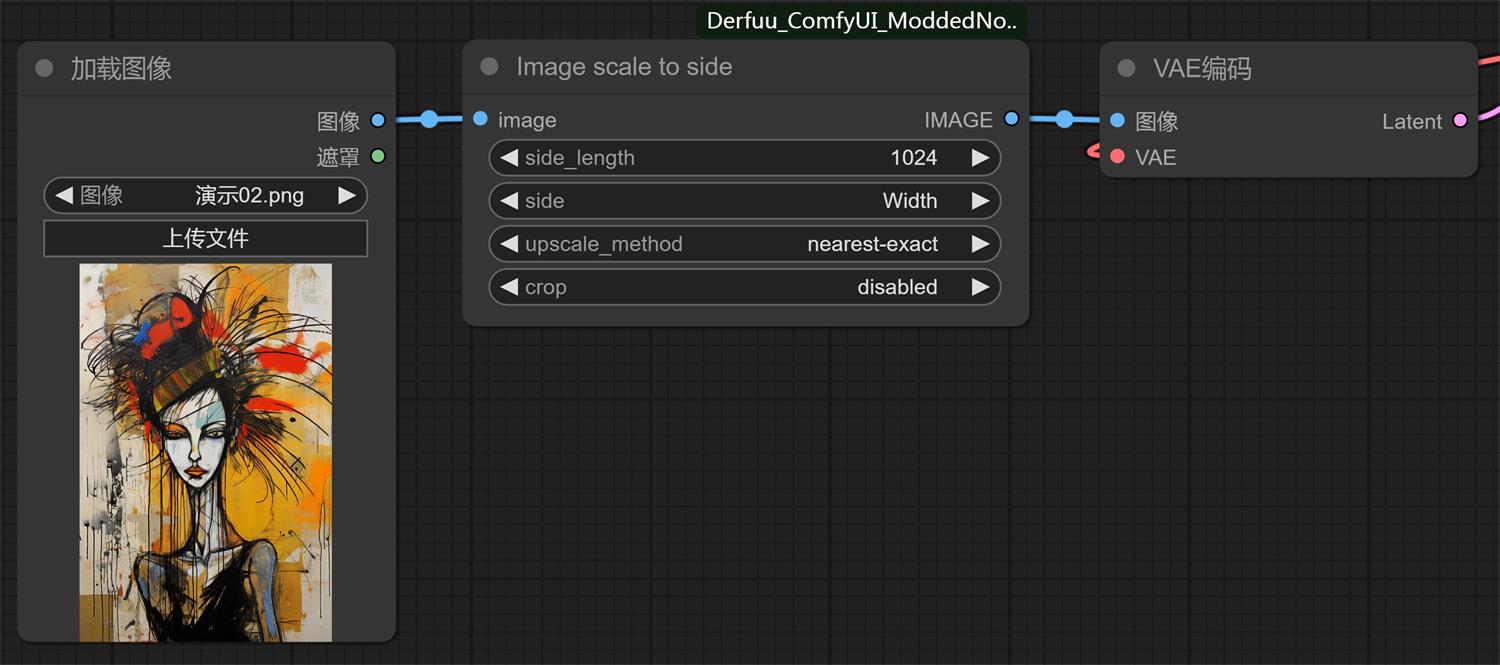
derfuu 插件: ①这时候我们可以通过 derfuu 插件去帮我们解决需要计算的问题,他可以根据图片比例自动计算成你想要的尺寸; ② derfuu 插件地址: https://github.com/Derfuu/Derfuu_ComfyUI_ModdedNodes.git (网盘也有我下载好的,不会安装的看我 ComfyUI 系列教程一); ③我们“新建节点——Derfu节点(Derfu_Nodes)——自设节点——图像——Image scale to side”,这时候我们就可以删掉“图片缩放”换成“Image scale to side”了;
④我们在“Image scale to side”会看到有四个可调节的参数(upscale_method、crop 不用修改,默认的就可以):
5. 我们可以跑图了,快去玩耍吧。
三、知识点扩展还记得我们上节课讲的 refiner 细化流程吗,我们图生图的时候是不是也可以使用 refiner 模型细化呢? 我们先复制一下图生图最主要的几个节点(加载图像、Image scale to side、VAE 编码),然后打开文生图 - refiner 细化流程并粘贴进去。 那我们把“VAE 编码的 Latent”连接到 “base 模型的采样器”上面(空 Latent 就不需要了,可以删掉了); 这时候还有个问题,我们是通过“降噪”来控制出图相似度的,但是“采样器(高级)”没有“降噪”可以输入。我们可以想一下“降噪”的作用和“采样器(高级)”里面哪个功能相似呢? 当然是“开始降噪步数”了,同样是用来跳过迭代步数的,但是相反的是,“开始降噪步数”数值越高和原图越接近,越低越偏向文字描述; 注意(1):开始降噪步数的数值不要超过“总步数-结束降噪步数”; 注意(2):我们所连接和修改的地方仅在 base 模型所连接的采样器。 手机扫一扫,阅读下载更方便˃ʍ˂ |

@版权声明
1、本网站文章、帖子等仅代表作者本人的观点,与本站立场无关。
2、转载或引用本网版权所有之内容须注明“转自(或引自)网”字样,并标明本网网址。
3、本站所有图片和资源来源于用户上传和网络,仅用作展示,如有侵权请联系站长!QQ: 13671295。





最新评论







