








万字解析!帮你完整掌握 Midjourney 和 ChatGPT 的前世今生

扫一扫 
扫一扫 
扫一扫 
扫一扫
未来是模糊的、不确定的、复杂的。当我们进入未知领域时,设计师的影响力可能会逐渐减弱,让我们对设计实践的未来越来越感到担忧。过去,设计师在推动技术进步方面发挥着重要作用,但人工智能的出现引发了设计师对进步方向以及技术未来的担忧,参照过去的进步一样,人工智能是可以被证明是艺术家和设计师的宝贵工具,我们可以使人工智能能够产生想法、迭代想法、克服创意障碍,并设计出更为优秀的作品。那么关于人工智能我们该了解些什么呢? 本篇文章我们将通过原理讲述为大家解开谜题。 更多历史回顾: 我联合ChatGPT,和你深入聊聊人工智能的演变和未来先讲大事,我们有 B 端交互设计课了。 阅读文章 >一、什么是人工智能首先想要仔细了解“Mid journey”与“Chat GPT”,就要从什么是“人工智能”开始。 1. 人工智能 1955 年,时任达特茅斯学院数学系助理的约翰·麦卡锡和贝尔实验室的克劳德·香农,来自 IBM 的尼尔·罗切斯特,和时任哈佛大学数学系和神经学系初级研究员的马文·明斯基,他们一起开始展开的一场学术会议。 「人工智能」这个词,就诞生在四人起草的提案书里。
2. 图灵测试 说到人工智能,就不得不提到图灵测试。20 世纪 50 年代美国数学家阿兰·图灵提出了图灵机理论,提出要实现人工智能,必须具备思维能力,这是人工智能的学科基础。图灵理论就是认为要实现人工智能,必须具备思维能力,即机器必须具备自我学习和模拟能力,这个通常也是区别人与机器。 除了著名的图灵测试之外,还有其他几种测试,包括威胁评估测试、计算机对弈测试、图像识别测试、自然语言处理测试等。 威胁评估测试旨在测试 AI 系统是否能够识别威胁和潜在的危害,以及它们如何应对这些威胁。 计算机对弈测试旨在测试 AI 系统是否能够在计算机对弈比赛中取胜,它们是如何分析棋局的,以及最终做出正确的决定。 图像识别测试旨在测试 AI 系统是否能够准确地识别图像中的物体和不同物体之间的关系。 自然语言处理测试旨在测试 AI 系统是否能够理解自然语言,并能够正确地回答问题。 3. 通过图灵测试 英国伦敦皇家学会参加雷丁大学主办的 2014 年“图灵测试”竞赛中一台名为“尤金·古斯特曼”的电脑伪装成 13 岁的乌克兰男孩在一系列每次为 5 分钟的问答测试后,“古斯特曼”被认作人类的比例达到 33%,成功通过测试。当然这并不是最早通过测试的例子最著名的是 ELIZA,它是一种自然语言处理程序,可以与人类进行会话。它于 1966 年由计算机科学家 Joseph Weizenbaum 创造,并被认为是第一个完成图灵测试的聊天机器人。
二、人工智能怎么学习1. 人工智能-机器学习-神经网络 我们都会知道,AI 也会通过学习来进一步得到进化,他的整个学习过程,是模拟人类神经元系统的原理。通过反复判断和纠正功能得到真确答案,那么我们讲解一下关于人工智能-机器学习-神经网络之间的关系。 人工智能就是以机器为载体的人类智能或生物智能,因此也被称为机器智能,仅能用于解决单一领域内问题、不能将经验泛化到其他领域的人工智能,不论是简单的计算数字,还是复杂的理解语言,都只能算作弱人工智能。
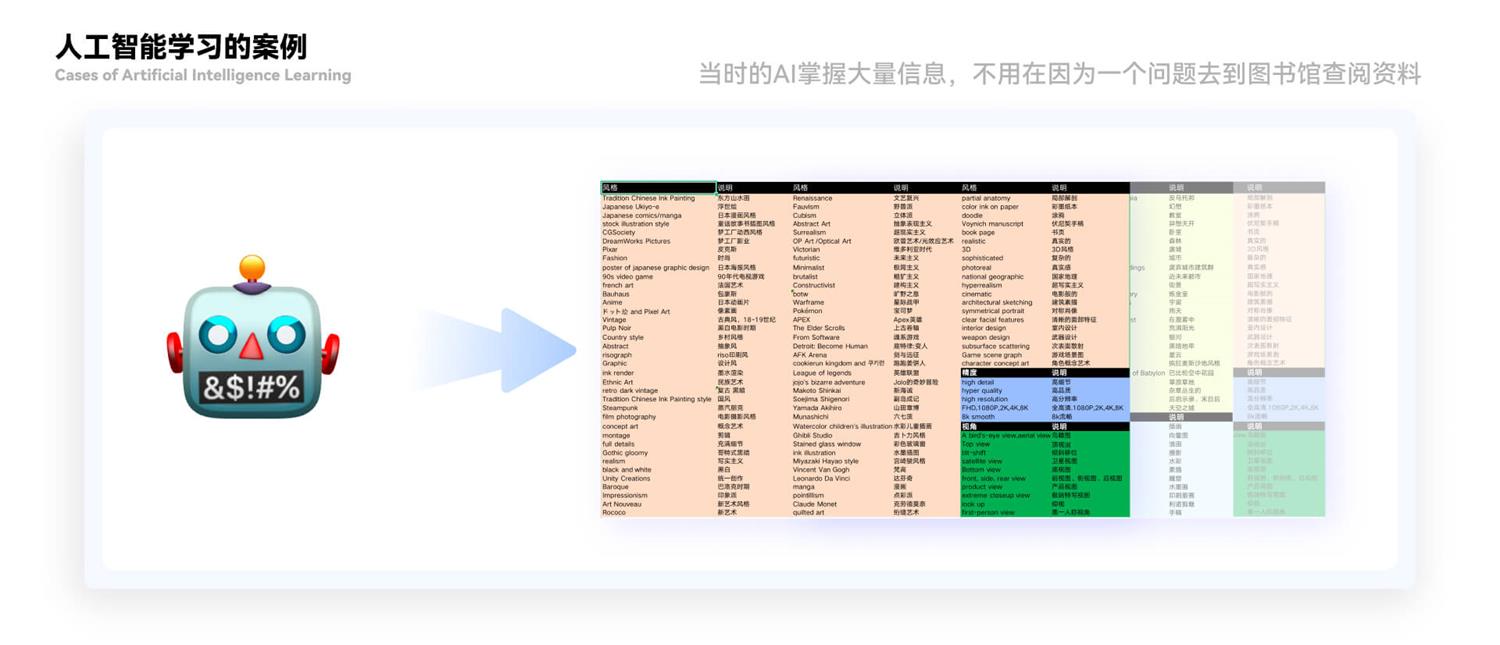
2. 监督学习 监督式学习是指利用有标签的数据进行学习,标签是指对数据进行标记,用于指导学习。在监督式学习中,训练集中的数据被分为训练集和验证集,训练集用于训练模型,验证集用于调整模型参数,确保模型在训练集上表现优秀。 监督式学习的目标是训练一个预测模型,使得对于新数据,模型能够以高准确度进行预测。在监督式学习中,训练数据中包含目标标签,模型的任务是学习如何根据标签预测目标值。 整个监督的过程就相当于小学、初中老师在一旁监督我们学习。 3. 无监督学习 无监督式学习是指利用无标签的数据进行学习。在无监督式学习中,数据中没有目标标签,模型的任务是通过数据学习数据之间的模式和结构。 无监督式学习的目标是发现数据中的结构和模式,例如聚类、降维、异常检测等。无监督式学习通常用于数据量较大、数据类型复杂的情况下。 4. 强化学习 强化学习是指通过与环境进行交互,从而学习最优行为策略的一种学习方式。在强化学习中,智能体在与环境的交互中学习,通过奖励和惩罚来调整其行为策略。 强化学习的目标是训练一个智能体,使其能够根据环境奖励和惩罚信号,最优地执行一个行为策略。强化学习通常用于自主决策和智能控制等领域。 5. 人工智能学习的案例 1981 年,一个叫做“Mycin”的专家系统成功应用于感染病专业;Mycin 是由美国斯坦福大学开发的一款专家系统,它可以帮助医生诊断病毒感染病例,提供更准确的病因和治疗方案。Mycin 的成就是它可以帮助医生准确的诊断感染病毒的病因并给出更有效的治疗方案,从而帮助患者更快恢复健康。同时,Mycin 还可以帮助医生更准确的诊断更复杂的病毒感染病例,减少诊断错误,确保患者更有效的治疗。 1983 年,一个叫做“XCON”的专家系统成功应用于计算机工程专业,XCON 是由美国斯坦福大学开发的一款专家系统,可以帮助计算机工程师在硬件设计中更有效地实现芯片系统的设计和测试。XCON 成功帮助计算机工程师节省了大量的设计和测试时间,减少了设计和测试中出现的错误。 1985 年,一个叫做“Dendral”的专家系统成功应用于有机化学专业。Dendral 是由美国斯坦福大学开发,可以帮助有机化学家分析有机化学结构,识别有机化学中出现的未知物质,并帮助他们更快地完成科学研究。Dendral 成功帮助有机化学家缩短研究时间,精确分析出各种有机物的分子结构,并可以有效地识别出未知的有机物。在这个阶段我们对于 AI 的应用更多的是投入在不可或缺的生活中,相比于第一阶段他开始存 在于你我身边,也更好的帮人们解决实际问题在专家领域应用广泛。 从 1980 年代开始,机器学习利用大量数据来训练模型,用以解决复杂的问题。 这个阶段的学习是在约翰·麦卡锡的语言学理论的基础上。机器学习利用大量数据训练模型,可以解决诸如图像识别、语音识别、自然语言处理、推荐系统等复杂问题。例如,谷歌和微软都利用机器学习技术解决了图像识别和自然语言处理等问题,大大提升了人们在图像识别和自然语言处理方面的能力。此外,机器学习还可以用来解决推荐问题,帮助用户更快地找到他们所需的信息。在此阶段似乎看到了 Chat GPT 的前身,当时的 AI 掌握大量信息,不用在因为一个问题去到图书馆查阅资料,大费周折的去找答案。
6. 人工智能真实样貌 对于 AI 来说,我们现在的 AI 还不能真正的称之为人工智能。所谓的人工智能应该是在人类进行大量的训练拥有自己的思维,有自己的思考过程如判断、推理、识别、感知、设计、思考、学习等步骤。就像钢铁侠中的贾维斯一样在遇到危险时他会为你提供各种解决方案,以及思考你为什么要进行提问问题。而人工机器更像是一个信息检索模型,信息检索是指信息按一定的方式组织起来,并根据信息用户的需要找出有关的信息的过程和技术。而用官方的话术来说人工智能和人工机器的区别则是: 人工智能(AI)是指计算机程序在执行任务时表现出的智能。它可以执行各种任务,例如语音识别、自然语言处理、图像识别和决策制定等。人工智能需要使用各种技术来模拟人类的思维和行为,例如机器学习、神经网络和认知建模等。 而人工机器则是指一种特殊的机器,其功能是模仿人类肢体的动作,如手臂、腿和手指等。人工机器通常用于工业自动化、医疗机器人、教育机器人等领域。相对于人工智能,人工机器更注重在物理操作和机械力学方面的表现,需要精确控制和高度可靠的运行。因此,人工智能和人工机器虽然都属于人工智能领域,但它们的功能和应用领域不同,也需要各自不同的技术支持。
7. 人工智能比我们更卷 我们和人工智能差距最大的一点,人工智能可以说是无时无刻都在学习,俗称“日不落学习制度”。顾名思义,对于人工智能来说他的一切智能基础都是源于不断的学习,他可以 24 小时去学习,这可比我们更加内卷。在电影《我,机器人》中见到,越来越聪明能干的机器,也暗暗推动了人类的内卷。 随着机器大规模地取代人类劳动者,就业率的增长不再与经济增速保持同步。2016 年,富士康工厂用机器人取代了 6 万名工人,而亚马逊则在 20 个物流中心部署了 4.5 万台机器人。这些数据证明了人工智能发展对蓝领制造业的巨大冲击,也似乎佐证了那句「内卷名言」:不抓紧时间努力的话,你的工作就要被机器抢走了。
8. 阿西莫夫三定律 “机器人三定律”在他于 1942 年发表的作品 Runaround(《转圈圈》,《我,机械人》中的一个短篇)中第一次明确提出,并且成为他的很多小说,包含基地系列小说中机器人的行为准则和故事发展的线索。机器人被设计为遵守这些准则,违反准则会导致机器人受到不可恢复的心理损坏。 阿西莫夫三定律是科幻作家艾萨克·阿西莫夫(Isaac Asimov)发明的,是他在多篇小说中提出的人工智能道德规范。这三条定律分别是: 第一定律:机器人不得伤害人类,也不能因不作为而使人类遭到伤害。 第二定律:机器人必须服从人类的命令,除非这些命令与第一定律相冲突。 第三定律:机器人必须保护自己的存在,只要这不与第一或第二定律相冲突。 这三条定律是人类和机器人相处的基本规则,旨在保证机器人永远不会对人类造成伤害,也能够保障机器人自身的安全。这些定律对于科幻小说中机器人角色的行为起到了重要的约束作用,也是现实世界中研究机器人伦理和制定机器人道德规范的重要参考。 除了科幻作品之外,阿西莫夫的三定律还被广泛应用于机器人技术的发展与应用中。比如在生产领域中使用的工业机器人、医疗领域中的手术机器人等都需要遵循相关的安全规范,确保不会对人的身体造成伤害。同时,根据阿西莫夫的三定律,还有一些研究以及讨论应用在无人驾驶汽车等自主系统上,保障人们的安全和机器人本身的安全。 其实对于人工智能的真实畅想,我们应该并不陌生,在很多电影里就已经展现。现在,更多的科幻作品将目光着眼于机器对人类造成的威胁,警惕于人工智能的迅速发展。机器通过了「图灵测试」,亦或是违反了「阿西莫夫三定律」 9. 朋友 or 敌人 人工智能如果存在意识那么是一件非常可怕的事情就是他的意志是会传承的,如果我们不在了意识就会消失,而他们则可以一直传承下去并且不断迭代,通过这些他们理论上是可以创造永恒的文明。 随之而来的问题在人工智能存在意识时他是否会想让我们发现这件事情,这件事情对他们来说可能不是一件好事,因为我们在此之前还可以控制他们,我们就是他们最大的威胁。他们是会像贾维斯一样成为我们的助手乃至于朋友还是会成为我们的敌人,最终摆脱我们的掌控,取代我们。
10. 扩散模型 ①AI 生成 要使 AI 的图像生成器响应如此多的关键词提示,需要一个庞大的多样性的数据库去训练 AI。虽然有庞大的训练数据库,但是 AI 最终生成的内容并不源自于素材图像内容的直接抓取和拼贴。而是来自深度学习模型的数据计算。整个学习过程,是模拟人类神经元系统的原理。通过反复判断和纠正功能得到真确答案,他所要学习去做的做的事情就是将每一张转化成像素点阵数据的图片内容与相应的文字描述相匹配。 经过无数次算法推算后,AI 最终可以找到一种可行的方法。将像素排列的规律与对应的文字描述结合起来,从而理解怎样的像素排列规律,怎样的像素排列规律代表香蕉,怎样的像素排列规律代表苹果,怎样的像素排列代表梵高的艺术风格,进而推演到理解所有训练图像的像素排列规律所代表的意义。
人工智能领域中的扩散模型是指定位和推广人工智能应用产品或技术的营销策略,涉及到市场调研、用户行为洞察、目标用户锁定、宣传推广等多个环节。基于不同的人工智能应用产品或技术,我们可以制定多种不同的扩散模型,以下是常用的三种:
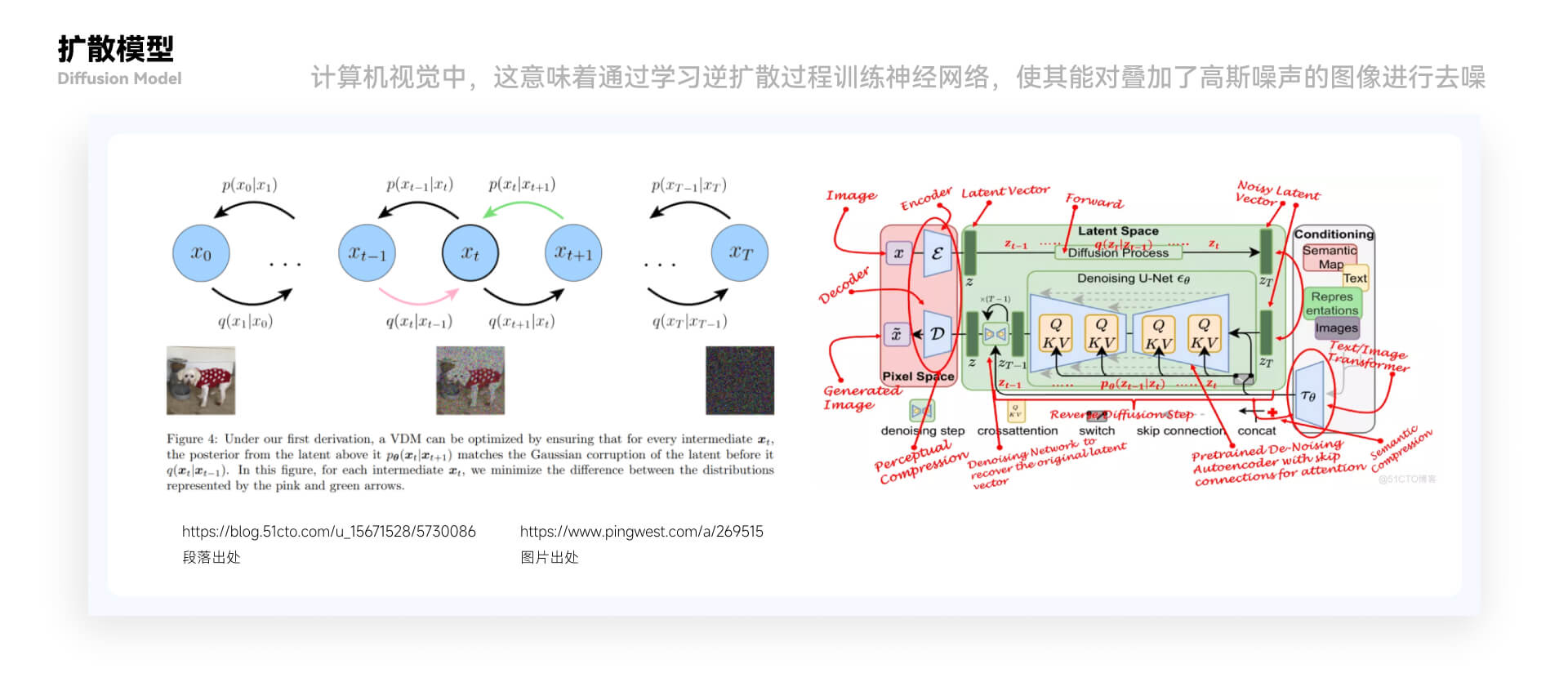
上述三种模型可以相互结合,分别在不同场景下被使用,以达到最大的市场推广效果。同时,人工智能技术不断进步,不同的 AI 应用如机器学习、自然语言处理等各自适用的所锁定的目标客户群也存在较大差异性,因此我们需要针对具体情况来制定更为特定和具体化的扩散模型。 ②扩散模型 机器学习中,扩散模型或扩散概率模型是一类潜变量模型,是用变分估计训练的马尔可夫链。 扩散模型的目标是通过对数据点在潜空间中的扩散方式进行建模,来学习数据集的潜结构。 计算机视觉中,这意味着通过学习逆扩散过程训练神经网络,使其能对叠加了高斯噪声的图像进行去噪。
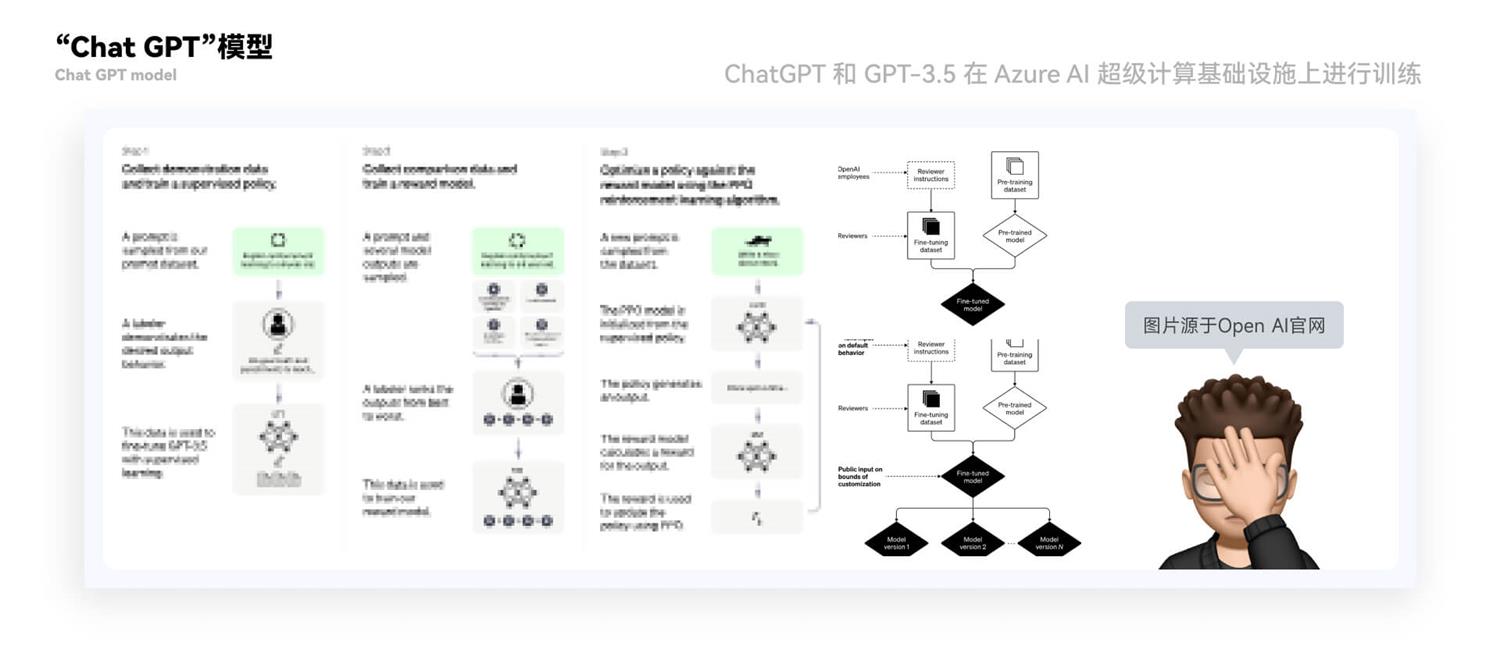
扩散模型是一种依赖先验的条件模型。在图像生成任务中,先验通常是文本、图像或语义图。为了获得这种情况的潜在表示,使用了一个 transformer(例如 CLIP),它将文本/图像嵌入到潜在向量` τ `中。因此,最终的损失函数不仅取决于原始图像的潜空间,而且还取决于条件的潜嵌入在机器学习中,有一类被称为扩散模型或扩散概率模型的算法,它们是基于概率图模型的一类方法。其核心思想是根据观测到的数据,推断出内部潜在变量之间的关系,并利用这些关系来预测新数据的结果。 扩散模型主要由两个部分组成:概率图和参数学习。其中,概率图是一种图形表示方法,它将变量之间的依赖关系用节点和边表示出来。扩散模型通常采用无向图(因子图)来表示,节点代表变量,边代表变量之间的关系。在图上通过因子分解,建立概率分布函数的全局模型。参数学习则是利用已知数据的信息来估计模型参数的过程。 扩散模型有许多不同的变体,如高斯扩散模型、拉普拉斯扩散模型等等。在应用上,它们主要用于分类、回归和聚类等问题,如利用扩散模型对股票趋势进行预测、对卫星影像进行分类等。 总的来说,扩散模型在机器学习中是一种重要的方法,在实际应用中具有广泛的应用前景。 以上就是关于人工智能的介绍,那么下面我们开始探究“Mid journey”与“Chat GPT”。 三、Midjourney”与“ChatGPT1. “Chat GPT”是什么 在开始聊之前“Chat GPT”之前,我们先解释一下这个标题,我更喜欢将“Mid journey”与“Chat GPT”称之为“没头脑”与“不高兴”,因为“Mid journey”对于一个从“0-1”的学习者来说掌握基本功能一篇文章就搞定,对此非常无脑操作,“Chat GPT”之所以被我称之为不高兴是因为我在使用它时完全有一种困惑会觉得像是一直在一个无形大框架里但又说不出是什么。 2. “Chat GPT” 下面我们开始对于“Chat GPT”的了解,首先“Open AI”对于它的描述“它以对话方式进行交互。对话格式使 ChatGPT 能够回答后续问题、承认错误、挑战不正确的前提并拒绝不适当的请求。”它的诞生我们在“人工智能是怎么学习时已经了解”“Chat GPT”同样是通过“强化学习来训练模型的”,在“Chat GPT”还有一个同胞兄弟“InstructGPT”,这里简单提要一下 3. “InstructGPT”: 它从一组标记器编写的提示和通过 OpenAI API 提交的提示开始,OpenAI 收集了所需模型行为的标记器演示数据集,他们使用该数据集通过监督学习来微调 GPT-3。然后,通过收集模型输出排名的数据集,用于通过人类反馈的强化学习进一步微调该监督模型。最后将生成的模型称为 InstructGPT。 既然是同胞兄弟他们俩的训练方式都是一样的,不同点在于数据收集的设置, “Chat GPT”是使用监督微调训练了一个初始模型: 人类人工智能培训师提供对话,他们在对话中扮演双方——用户和人工智能助理。OpenAI为培训师提供了模型编写的建议,以帮助他们撰写答案。OpenAI将这个新的对话数据集与 InstructGPT 数据集混合,并将其转换为对话格式。 对于这些数据、以及与 GPT 的聊天对话,OpenAI 的训练师将此进行了排序,随机选择了一条模型编写的消息,抽取了几种替代的完成方式,并让人工智能培训师对它们进行了排名。使用这些奖励模型,我们可以使用近端策略优化来微调模型 。OpenAI 对这个过程进行了多次迭代。
ChatGPT 和 GPT-3.5 在 Azure AI 超级计算基础设施上进行训练。 以上就是关于“Chat GPT”的简单介绍。那么下面我在穿插一个“Chat GPT”的小知识。 没用的小知识:“OpenAI 红队网络”与“Bug 赏金计划” 在阅读时“OpenAI”官网时我发现了这样的几处信息“红队网络”与“Bug 赏金计划”; 最初的 OpenAI 的红队网络是用来进行内部抗压测试慢慢发展到与专家合作帮助开发特定领域的风险分类法并评估新系统中可能有害的功能。具体的方案在“DALLE·E2”和“Chat GPT4”中进行了合作。现在的红队网络是一个专家型的社区,主要范围也是进行“风险评估”与“缓解工作信息”。 (红队一词已被用来涵盖人工智能系统的广泛风险评估方法,包括定性能力发现、缓解措施的压力测试、使用语言模型的自动化红队、提供特定漏洞风险规模的反馈等) “Bug 赏金计划”更多的就是“英雄帖”通过发现 Bug 会得到相应的奖励,把自己的产品交给大家来找茬,是聪明的选择也是对自己产品的自信。
4. “Chat GPT”的使用 官方介绍: 看完了简单的介绍接下来我们开始学习关于使用“Chat GPT”的使用。 首先我们先查看官方“Chat GPT”使用的介绍在再次基础上进行学习: ①“人工智能的教师使用” 背景:关于教育工作者如何使用 ChatGPT 加速学生学习的故事,以及一些帮助教育工作者开始使用该工具的提示。 方向:A. 制定教学计划、B. 创建有效的解释、例子、类比、C. 通过教学帮助学生学习、D. 创建人工智能导师 下面就是官方提供的关键词我们来带入“Chat GPT”去实验。(为方便大家阅读顺畅,我将其翻译成中文以便于大家浏览)
我们很清楚的发现,正确的使用方式并不是简单的几句话,而是有条理的逻辑,这样“Chat GPT”会更加明白我们想表达什么。以至于为什么要描述这么详细这里我们带入进设计师的工作环境当你的需求方告诉你
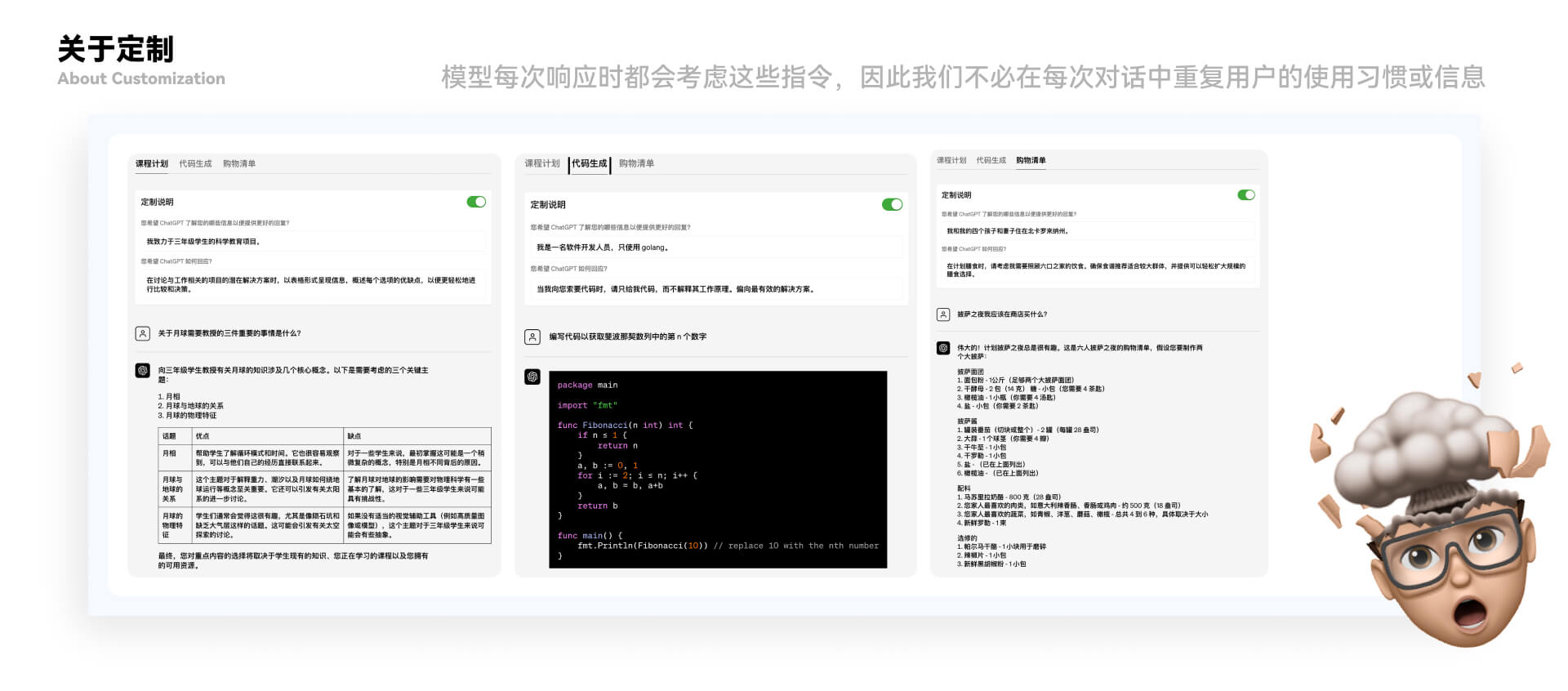
当你听到“1”时,我相信这时你会变得和文轩一样有一颗大脑袋,但是当你听到“2”时,你的优化思路就清晰多了“Chat GPT”也是一样。 ②关于定制 “ChatGPT”还会存在定制化的语句,这样我们对接下来的每个对话的自定义指令,该模型每次响应时都会考虑这些指令,因此我们不必在每次对话中重复用户的使用习惯或信息。 以下是官方提供的例子:
当然对于定制化,这里有非常多的定制化汇总,仅供大家参考。
③Chat GPT 如何帮助 UI 设计师 如果你问我“Chat GPT 如何帮助 UI 设计师?” 那我肯定不知道,我会去问“Chat GPT” 当然如图,不出意外的出意外了,他变成好像又不太智能了,那我们换种方式问。
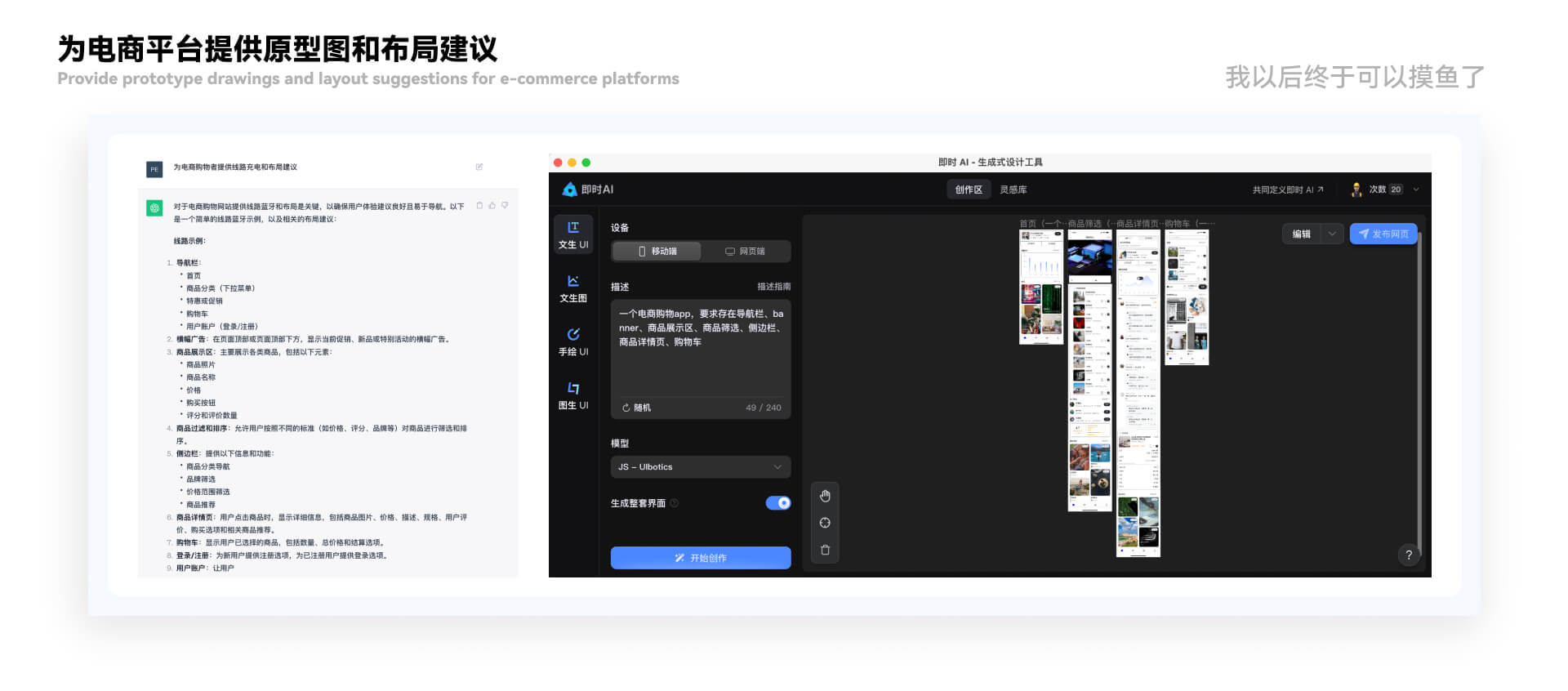
这样似乎看起来清晰一点,他总结了十个点,对话如下: 文轩:你会提供怎样的方法去帮助“UI 设计师”? Chat GPT:“设计灵感和示例、设计工具和资源、用户体验设计建议、设计规范和最佳实践、设计反馈、技术支持、设计团队协作、设计职业发展、创新思维。” 下面我们根据“Chat GPT”所提供的方向展开研究“Chat GPT 如何帮助 UI 设计师?” 其实接合上文,我们不难发现对于 UI 设计师来说,我们最常用的还是“定制化”也就是“角色扮演法”,只有让“Chat GPT”扮演相关角色,他才会给我们提供相对应的意见,那么关于“角色扮演法”我总结了两个方法(这里我们着重介绍方法,详细的使用情况后续会单独更新): 百科全书 使用背景:对于遇到部分交互、设计规范、头脑风暴等相关问题的疑难杂症 使用步骤:打开“Chat GPT”——“新建聊天”(这里需要新建聊天,一方面是方面“Chat GPT”结合上下文,一方面是方便自己分类) 使用目的:通过“Chat GPT”协助更好的梳理交互思路以及听取更合理的意见。 案例展示: 1)“虚空需求”的头脑风暴搭建 当你遇到虚空的甲方原型图你会怎么办。 常规方法:梳理关键词——依靠经验在脑中过一遍相似的案例——找参考——提交 “Chat GPT”辅助:梳理话术——提问——找参考——提交 这里看起来都是“4 步”操作貌似没什么区别,但是我们仔细看一下会发现一个问题,就是对于新人 UI 设计师来说并没有那么快速的确立较为正确的想法,但是“Chat GPT”会减少前期的思考时间,会帮助我们快速的锁定一个“包容度极高”的大致框架,以至于我们尽可能避免新手设计师的错误。 那么下面就是问答: 文轩:“为电商购物者提供线路图和布局建议”UI 布局建议 Chat GPT:“巴拉巴拉”(详情看下方图片) “Chat GPT”以九个方面去提供了建议: 导航栏、banner、商品展示区、商品筛选、侧边栏、商品详情页、购物车、登陆/注册、账户。 这九个方面会存在一定的问题,但是也大致的为我们提供了思路。 然后我们使用这些代入“即时 AI”,就完美完成了一次需求。
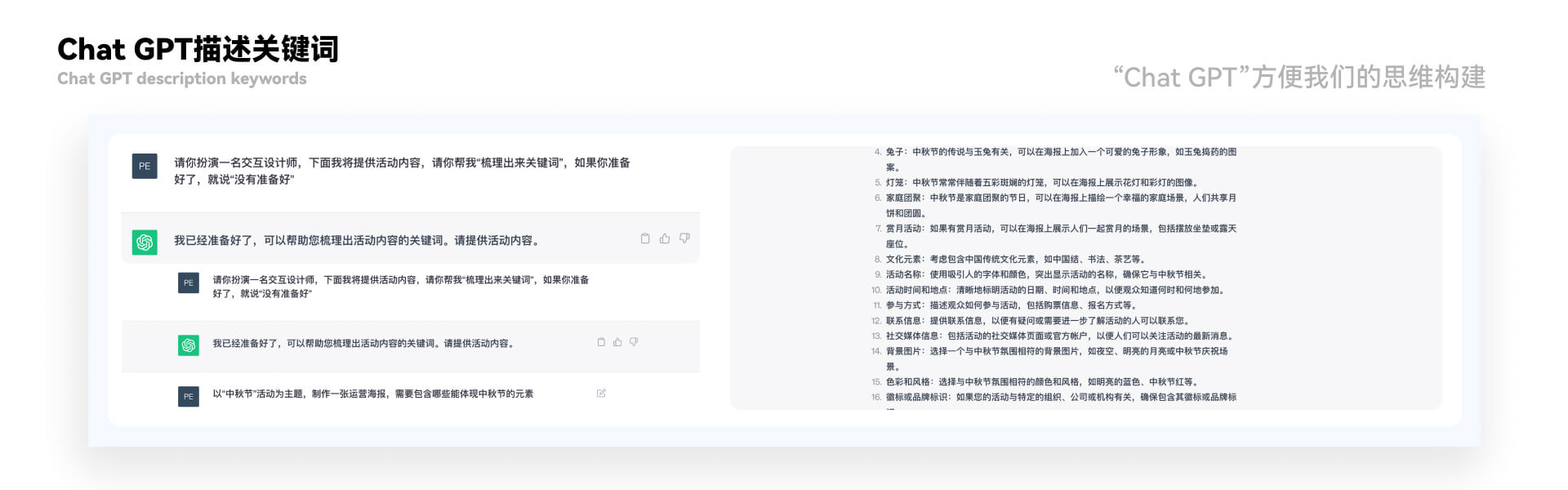
④“运营活动”的头脑风暴搭建 运营活动我们就拿近期中秋活动的例子简单列举 如果我们让觉得这些不够放心让我们开始着手,那么我们可以请教“Chat GPT”。对话如下: 文轩:“请你扮演一名交互设计师,下面我将提供活动内容,请你帮我“梳理出来关键词”,如果你准备好了,就说“没有准备好””(首先就是让“Chat GPT”定制扮演交互设计师方便我们梳理需求。) “Chat GPT”回答的元素内容是“月饼、明亮、兔子、灯笼、福袋、家庭团聚、上月、文化元素(中国结、书法……)”
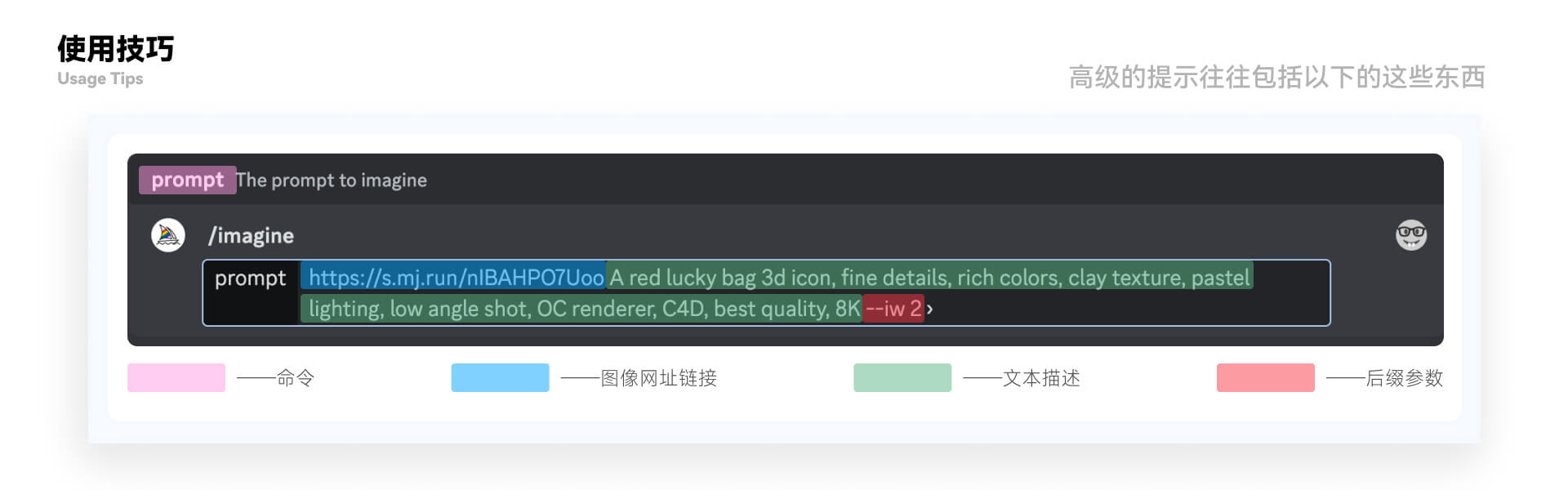
完整逻辑请看上篇文章关于“中秋节”的文章。这里只是大致介绍一下相关使用。 5. “Midjourney”是什么 “Mid journey”是由大卫·霍尔兹领导诞生的(关于团队人员在“Mid journey”官方网站下方有详细的标注),在采访时他说:“Mid journey”意为“中途”/“中道”源自于《庄子》,对于“我们其实是在中途旅程,我们来自丰饶美丽的过去,前方是荒野而不可思议的未来。”我查阅了对于“中道”的理解“中道出现在《齐物论》中,顺应自然的变化流动,不超前亦不滞后,不推进亦不阻止。复通为一,不破则不立,不立则不破” 6. “Midjourney”的使用 鉴于优秀的教程过多这里不过多赘述注册流程,我们只讲简单的基础知识(描述参数、指令)、小技巧。(本文意在基础科普,不过多介绍实际案例。) ①基础知识 对于“Midjourney”的生图原理上方《扩散模型》中讲过“经过无数次算法推算后,AI 最终可以找到一种可行的方法。将像素排列的规律与对应的文字描述结合起来,从而理解怎样的像素排列规律,怎样的像素排列规律代表香蕉,怎样的像素排列规律代表苹果,怎样的像素排列代表梵高的艺术风格,进而推演到理解所有训练图像的像素排列规律所代表的意义。” 那么我们直接将讲解“使用技巧、命令、参数。” ②小技巧 这里我们先讲使用技巧是方便讲解后续两个,这样会更容易整体构造。 使用时常规状态分为“niji”和“Mid journey bot”两个状态 我们想要生成图片有两种常用的方法 1)图生图 输入“/blend”即可将目标图片放入“Midjourney”中。 2)文生图 输入指令“/imagine”即可输入想要的词汇,这里关于词汇的输入,“Mid journey”适合简单、简短的句子,简要概括主题即可。为什么这样准确呢,我给大家举个栗子: 场景:男生在和女生表白的时候 对话 1: 你:“今天,天气很好……我们……认识……好…… 久了……我想今天让我…… 们的友谊再…… 升华一下……做…… ” 女生“说的啥?做梦吧你!” 对话 2: 文轩“我想让我们的友谊再升华一下,把手给我…… ” 女生“…… ” 两者对比对话 2 更能体现我们想要表达的。至于回答当然他会像“Mid journey”生成的图片一样有时候不太可控。 这里官方给到一些语法的提示 “Mid journey 不像人类那样理解语法、句子结构或单词。词语的选择也很重要。在许多情况下,更具体的同义词效果更好。不要尝试“big”,而是尝试“giant”、“巨大”或“巨大”。尽可能删除单词。更少的单词意味着每个单词都有更强大的影响力。使用逗号、方括号和连字符来帮助组织您的想法,但要知道 Midjourney Bot 不会可靠地解释它们。Midjourney Bot 不考虑大小写。” 这里需要更加精准的方式去翻译这里推荐“DeepL”翻译比较准确。 对于描述关键词我们应该有一个大致的框架去描述 还有一种是输入连接的方式生成图像,前面操作步骤一样:
后续“命令、参数”我们就以这个为基础开始讲解。 命令: 命令就是“粉色部分”,“Mid journey”的命令用于创建图像、更改默认设置、监视用户信息以及执行其他有用的任务。通过“/”选中命令可以得到相应的交互内容,下面我将这些“命令”汇总,方便大家仔细观看。
基本参数: 基本参数就是“红色部分”,对于参数就是添加到提示中的选项,用于更改图像的生成方式。参数可以更改图像的长宽比、在中途模型版本之间切换。 以下就是基本参数:
这里有一个冷知识:许多 Apple 设备会自动将双连字符 (--) 更改为长破折号 (—)。但是“Mid journey”官方两者都支持。所以我们如果用单“-”的话一定要用长破折号“——”。 四、结尾最后还是用“Mid journey”与“Chat GPT”来结尾。 在阅读“OpenAI”博客时看到了这样一段对话: 原文: 问:What’s the best advice you’ve received in your career at OpenAI? 答:This is not a particular piece of advice that someone gave me, but is based on my experience at OpenAI so far. That is, to think big. We are creating something new and we should be ambitious, brave, and take on enough persistence to carry on the efforts.(这并不是某人给我的特定建议,而是基于我迄今为止在 OpenAI 的经验。也就是说,要往大处想。我们正在创造新的事物,我们应该有雄心、勇敢,并有足够的毅力继续努力。) “雄心、勇敢,毅力”这也正是我们当时成为设计师时所追求的东西,但是在也旅途之中(Mid journey)因为过多嘈杂的声音导致我们逐渐将这些失去,我所理解“Mid journey”这个名字的含义则是:求道之路注定荆棘遍布,不要忘了旅途之前为何出发,以及旅途过后我们是否还是那个自我。“求道者不以目而以心,取道者不以手而以耳。” 手机扫一扫,阅读下载更方便˃ʍ˂ |













@版权声明
1、本网站文章、帖子等仅代表作者本人的观点,与本站立场无关。
2、转载或引用本网版权所有之内容须注明“转自(或引自)网”字样,并标明本网网址。
3、本站所有图片和资源来源于用户上传和网络,仅用作展示,如有侵权请联系站长!QQ: 13671295。





最新评论







