








Midjourney v6 终于更新了!一文详解新版本 3 大要点

扫一扫 
扫一扫 
扫一扫 
扫一扫
大家好,这里是和你们一起探索 AI 绘画的花生~ Midjourney 的 v6 模型终于在 2023 年结束之前更新出来了,这是一个完全重新训练的模型,所以图像生成效果与之前的 v5.2 相比有很大的不同,那么此次更新主要有哪些特点?我们又应该如何正确地用 v6 模型出图呢?今天就带大家一起了解一下~ 上期回顾: Midjourney 重大更新!一文详解风格调谐器 Style Tuner大家好,这里是和你们一起探索 AI 绘画的花生~上周 Midjourney 上线了新功能 Style Tuner 风格调谐器,可以进行风格混合和复制迁移。 阅读文章 >首先是 V6 的图像生成质量相比之前的模型来说又提升了不少,在画面质感以及细节刻画上有了更精致的表现,图像的光影处理也比 v 5.2 更真实自然。下面是分别用 v5.2 和 v6 生成的特写图像,通过对比可以看出 v6 的细节更锐利明确,不像 v5.2 那样有种灰蒙蒙的感觉。
另一个更重要的改进是 v6 模型对文本提示词的理解。一方面是 v6 模型可以理解更长的文本提示了,提示词容量达到了 350-500 个词,而 v5.2 中超过三十个词后,提示词就不起作用了;另一方面是 v6 对语义的理解也更准确,它可以正确呈现提示词内提到所有元素,以及元素的颜色、位置以及互相之间关系。v6 还支持自然语言描述,所以提示词不要需要全部都用短语,这都让我们可以更轻松准确地生成自己想要的内容。 我们来看几组提示词,感受一下 V6 在语义理解上的进步。 首先是有关“双重曝光”主题的图像,提示词比较简单“Side view of a woman, giant flower, double exposure, surreal photography 女人侧影、巨型花朵、双重曝光、超现实摄影”,通过对比可以看出 v6 对双重曝光的理解更准确,而 v5.2 的图像只是一个摄影作品,没有体现出双重曝光的特效。
之前我尝试在 Midjourney 中生成“一个男孩飘在空中,一只手向前伸出”这样的指定动作,尝试了很多次效果都不太好,这次用 v6 试了一下,生成指定动作的成功率要比 v5.2 高不少,同时人物整体的姿态也更自然了。
然后是对于复杂提示词的理解。我特意在提示词写了很多物体,包括木头桌子,白色的花瓶、黄色的玫瑰、红色的碗,还有多种水果,并描述了它们之间的位置关系。从生成结果来看,v5.2 没有准确呈现碗的颜色,在提示词中位置靠后的苹果、蓝莓这些元素也都丢失了;而 v6 则准确地生成了不同颜色的物体,位置关系正确,也没有出现元素丢失的情况。 A photo-realistic photo of a wooden table with a white vase with yellow roses. Next to it is a red bowl with lemons and apples, with some blueberries scattered around the side of the bowl. Next to the table is a white window. --ar 2:3 这是一张木桌的写实照片,桌上放着一个白色花瓶,里面插着黄玫瑰。旁边是一个红色的碗,碗里有柠檬和苹果,碗边散落着一些蓝莓。桌子旁边是一扇白色的窗户。--ar 2:3
V6 模型还有一个重大进步——支持生成准确的英文文本内容,操作方法是在写提示词的时候,用英文的双引号将文字内容括起来,比如「a neon sign with text “UISDC”」。生成文字内容时,最好选择 style raw 模式,或者设置较低的 stylize 值,因为 stylize 过高会导致文本内容扭曲。
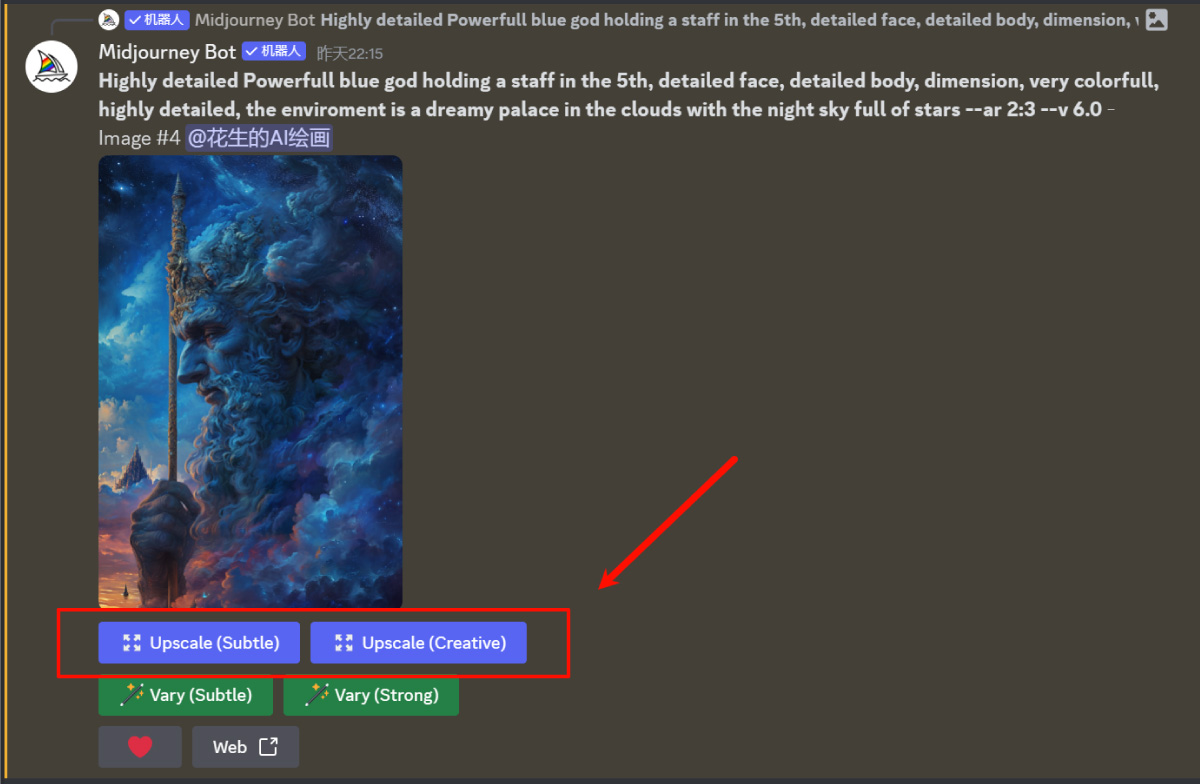
除了新的 v6 模型,Midjourney 其他的参数和命令功能也有对应的调整。 首先是对于 v6 模型来说,--ar、--chaos、--weird、--tile、--stylize、--style raw、Vary(subtle/strong)、Remix、/blend 这些参数和命令是可以正常使用的,但是 pan、zoom out、vary region、/tune 等功能则要晚一点才上线,并且性能上也会进行优化。 /describe 目前也可以使用,但之后会有一个 v6 的新版本推出。 V6 版本的图像放大选项则是变成了 Upscale(Subtle) 和 Upscale(Creative),二者都可以将将一张图像放大 2 倍,区别在于 Subtle 放大的图像会与原图非常相似,只在细节上会有细微变化;而 Creative 放大后的图像则会在细节上与原图有明显的不同,这个大家按实际需求选择就可以了。
V6 模型上线后,很多小伙伴都反映说同样的提示词 v5.2 和 v6 出来效果完全不同,这是因为 v6 是一个重新训练的模型,它的图像生成算法与 v5.2 有很大的不同,所以我们需要重新学习其提示词的写法。 但目前也没有一套确定的提示词规则可以作为参考,因为目前的 v6 是 alpha 测试版,在未来一段时间它的还会发生一系列的重大变化,所以在完整版确定下来之前,我们只能自己先摸索。我总结了一些官方以及网友给出的建议,大家可以做为参考:
下图是同一组提示词分别在 v5.2 和 v6.0 中生成的图像,二者风格差别非常明显。 A young man and a young woman are checking out for the buying in a shopping center, flat illustration style --ar 10:16
这是因为对于 v6 模型来说,“ flat illustration style”所指的内容太过宽泛了。如果想让 v6 生成的风格贴近 v5.2 的样式,需要加入一些更具体的风格关键词,比如 UI、极简、矢量等,此外也可以再优化一下提示词顺序,加入一些颜色、服装等方面的细节描述,让生成的图像更贴合自己的需要。
那么以上就是为大家总结的 Midjourney 新版本 v6 的相关内容,后续 v6 应该还会有一波大的更新,我也会及时带大家了解最新的动态。喜欢本期推荐的话记得点赞收藏支持一波,也欢迎大家扫描下方二维码,加入优设 AI 绘画交流群,和大家一起学习 AI 知识。
想系统学习 Midjourney 的小伙伴也可以了解我最新制作的 《 零基础 AI 绘画入门指南 》 ,我会带大家了从零开始学习 2 款目前最热门的 AI 绘画工具 Midjourney 和 Stable Diffusion WebUI,并提供各种相关资源,解决大家在自学时教程不全面、找资源难、有疑问无处请教等情况,帮你快速入门~ 推荐阅读: 过于可爱!手把手教你用SD做人气超高的毛绒玩具大家好,这里是和你们一起探索 AI 绘画的花生~最近网上看到一些用 Stable Diffusion 生成的毛绒玩具,非常可爱。 阅读文章 >年度盘点!2023年不容错过的30款AI神器,你用过多少?大家好我是花生~还有几天 2023 年就结束了,过去的 1 年里生成式 AI 技术发展迅速,出现了很多优质的 AI 工具,今天就为大家盘点其中我觉得非常不错的那些产品~相关推荐:一、AI 聊天机器人① ChatGPT过去 1 年是大语言模型发展的井喷之年,但是说起目前 阅读文章 >手机扫一扫,阅读下载更方便˃ʍ˂ |











@版权声明
1、本网站文章、帖子等仅代表作者本人的观点,与本站立场无关。
2、转载或引用本网版权所有之内容须注明“转自(或引自)网”字样,并标明本网网址。
3、本站所有图片和资源来源于用户上传和网络,仅用作展示,如有侵权请联系站长!QQ: 13671295。





最新评论







