








跟上时代趋势!人工智能行业常用名词科普

扫一扫 
扫一扫 
扫一扫 
扫一扫 本文整理了人工智能行业中设计师需要理解的一些名词和内容。 一方面供自己学习思考,另一方面也希望能帮助到准备投入到人工智能行业的设计师。之前听有的朋友讲到,觉得自己没有计算机背景,有点害怕进入到这样一个领域来。 没有计算机背景没有关系,只要对这个行业充满好奇,一个个的问题解决掉,在你眼前的迷雾都会散去的。 先简单举几个人工智能在生活中有在应用的例子: 像现在有的超市寄存物件,开箱时采用的人脸识别;像家里购置的智能音响,时不时还能跟它聊上几句;像接听到的银行电话(是的,对方可能是机器人噢);像在淘宝上咨询的客服小蜜;像你手机里的虚拟助手….等等这些都是人工智能在生活中的应用。 人工智能在设计领域的应用也相当广泛,具体可以看这篇文章: 双11期间有1.7 亿个banner,都来自阿里的“鹿班”AI设计系统随着人工智能时代的到来,设计与人工智能的纠葛,艺术与科技的博弈,越来越频繁地现身热门话题榜。 阅读文章 >这几个例子是在生活中比较普遍能接触到的,实际人工智能应用的领域还在不断的扩大,我们甚至都无法想象到,未来的生活会是怎样的状态和场景。 在这家公司之前,我做过语音交互类的产品交互设计。当时在定义人与设备进行语音交互时,会是怎样的一个交互场景。从说唤醒词到发出指令,从收到反馈到继续对话。唤醒后等待的时间、结束的规则等等这些。 而现在,我大部分时间是在设计工具,如何让使用者能快速的创建出一个智能机器人。如何让机器人的创建者方便快捷的添加机器人的相关数据和创建出对话场景。 所以在进行这些工具的设计之前,有些名词概念,会需要设计师来了解一下,能让我们更好的理解人工智能的一些原理以及能够让设计师具象化到实际的设计中,甚至能基于此技术/原理来进行相关的创新或研究。 整理内容如下:(内容基于工作及自身理解,如有概念理解错误,欢迎指正) 下面尝试用较易理解方式来解释这些名词:
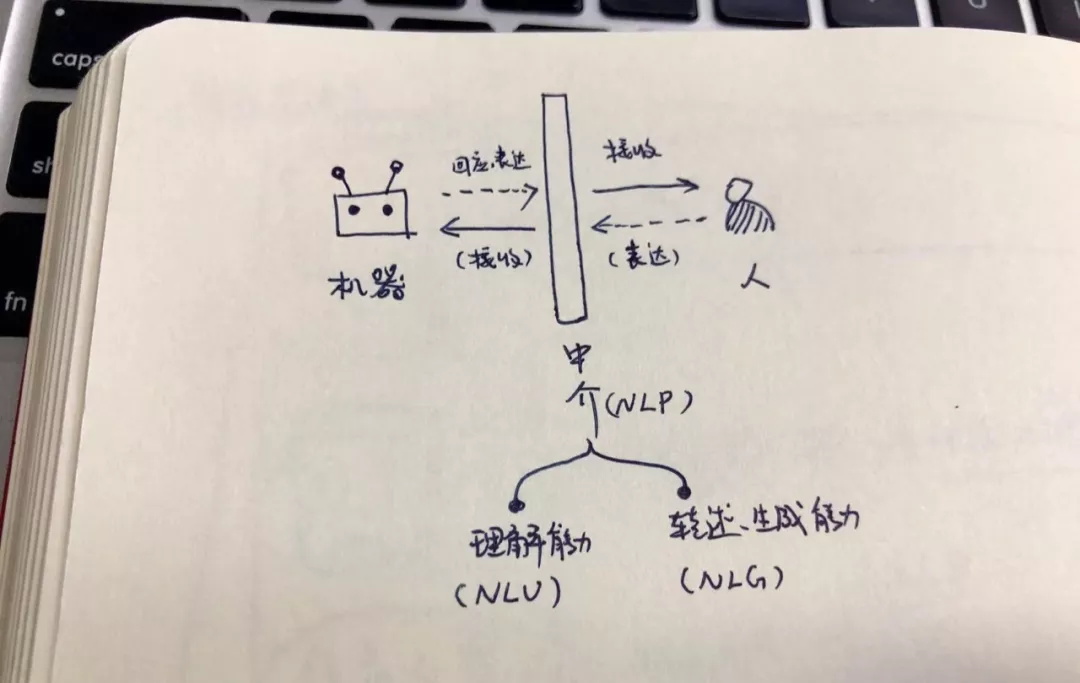
我把这三者关系画了张图示,我是以这样的方式理解的
从图中可进一步看出,NLU 和 NLG 是 NLP 的子集,而 NLP 是人与机器沟通中很重要的存在。
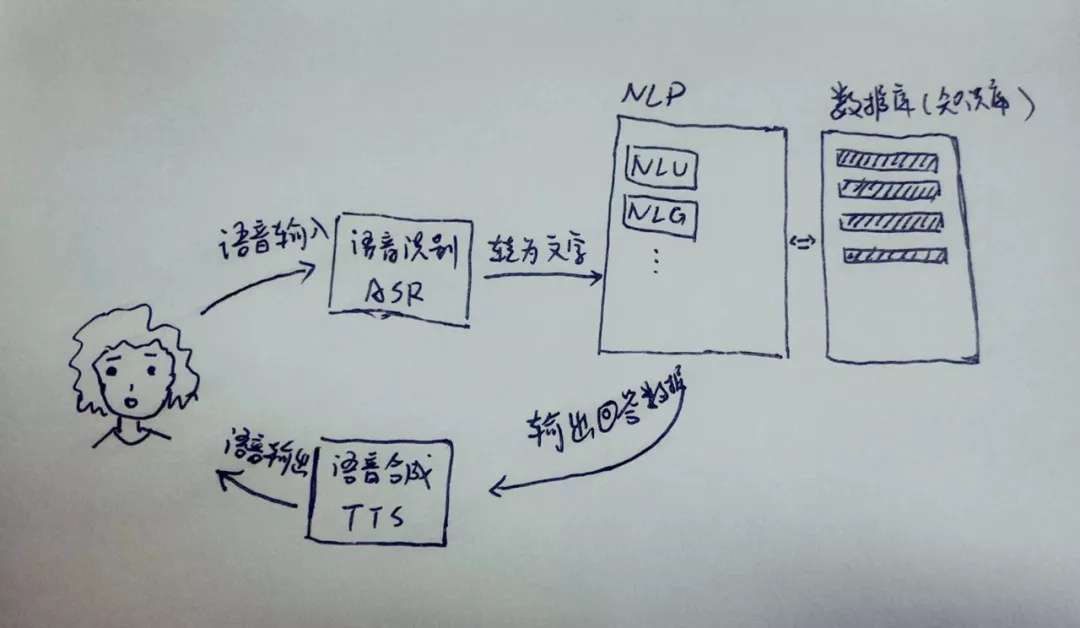
语音识别(ASR):将语音内容转为文字 如微信里面,当别人发的语音信息不方便外放收听时,可以转为文字查看 语音合成(TTS):将文字内容转为语音 如现在很多的阅读软件,支持播放,有的就是利用 TTS,直接将文本内容转为语音播放出来。 我试着将上面提到的 NLP 和 ASR、TTS 组合起来,关系可以如下图所示
意图(Intent):一个人希望达到的目的,或者解释为想要做什么,他的动机是什么。 如:
槽位(Slot):可以理解为系统要向用户收集的关键信息。 如: 「买张明天从上海到北京的机票」 上面这句话中,获取到意图(买机票);提取关键信息 时间(明天)、地点(出发地:上海;到达地:北京) 还可以这样理解,当我们去银行营业厅办理卡的时候,会填写一张表,表每个要填写的选项,就是一个个的槽位。槽位就是为你服务的人员要从你那收集的关键信息。 实体(Entity):用户在语句中提到的具体信息 实体这词放在生活中,我们很容易理解,就是实实在在的物体,像桌子、电脑、熊猫等等这些都是实体。 但是在人机对话中,机器理解人的语句内容,会识别出语句中的实体信息(如:地点、人名、歌曲名等),然后进行标记。 那槽位和实体是不是讲的是一回事?只是不同的说法? 我之前有一度陷入这样的困惑中,但其实这两者还是有所区别的。比如,一个实体是数字,但是在语句中,数字将代表不同的含义。 如: 人:有没有10元的鲜花? 机器人:玫瑰花10元一支 。 这句话中,实体number「10」,但这个 10 在句子中表达的是价格,所以收集到的槽位信息是价格:「10元」 这样说可能还是不太能理解,那我们可以先了解下,在一句表达中,需要进行槽位信息收集,但机器如何知道「买张明天从上海到北京的机票」中,「上海」是城市,并且「上海」是出发地呢? 「上海」这个词会被建立在一个城市实体词库中,这是「上海」能被识别到是「城市」的原因。 其次,通过将解析槽位加入语料中,加以训练让机器学习相关表述结构,来获知该句式中,收集到的第一个城市是出发地,于是把第一个城市填到对应的槽位中。 使用什么工具来让机器知道,这个信息是要提取的信息? 解析器(Parser):抽取/解析用户语句中的关键信息 上一个讲到实体,这里讲到的解析器则是这么个工具,用来抽取这些信息。比如会有些通用的解析器如时间解析器、城市解析器、歌手解析器等等。 解析器的类型也比较多,如通用解析器、词典解析器、正则解析器、组合解析器等等,这里就不再扩展开讲具体解析器,实在过于复杂了。 命名实体识别(NER):用来识别具有特定意义的实体。主要会包括像机构、地名、组织等。 是不是发现,解析器和 NER 在做差不多的事情?我是这样理解的,解析器的话是一个更大的存在,其中包括了 NER。解析器下会有不同类型和不同功能的工具来实现关键信息的识别/抽取。
上面是在有次分享中提到的,这四个不同类型的对话,在机器人平台中,会需要借助不同的功能模块来实现。 任务对话(Task Dialogue ):有上下文联系,就像我们要去订票、订餐之类的一段任务型的对话。 我们公司产品中,任务引擎模块就是做这个任务对话的创建,比如,要订机票的场景。用户在这个订机票的场景中,会涉及到的对话内容、流程的设计。 知识图谱(Knowledge Graph):这个可以理解为可视化关联信息。
训练(Train):这个概念可以这样理解,比如你创建了个机器人,但是它什么都还不懂,于是你塞了堆知识给他,这时,它就需要自己训练学习了。训练好了,就能回答你塞的那堆知识里的问题了。 讲到这就忍不住想用这个学习的例子,来简单讲下一般机器人的创建流程。像我们在学校,会经历上课学习新知识-复习温习-考试-整理错题集,以此循环进行。 这个创建机器人的流程也是一样通过知识的导入/创建-训练-测试-优化-上线-优化,以此循环,不断强化机器人,让它越来越智能。 其他: 数据标注:将对话日志中的有价值数据做标注(标记/匹配/关联之类)。 因为人的表达万千,多种表达方式都代表的同一个意思。有时用户说了句话,是语料库中并不包含,于是机器人可能就答非所问了。 Ai 训练师们就可以将这些数据信息标注到对应的问题中去,这样当用户再用同样方式表述时,机器人就能如预期回答了。 讲到标注想到之前在朋友圈很火的你画我猜,谷歌推出的这个小游戏席卷朋友圈。他们用了个如此聪明的做法,其实我们参与其中的做法就是在做数据标注,而且还是主动提供数据的那种。 这也反映了,数据对于机器人的重要性,通过不断的进行数据维护和补充数据,机器人就会越来越理解人,表达也会越来越智能。就跟我们学习一样,不断学习才能够理解其他的含义,甚至当认知能力提升了,看待问题的角度才能不一样。 更为深入的名词,像分词、神经网络、深度学习等等这些,可以搜索 Easyai 这个网站去了解。 还有很多词我不太能转为自己可理解的方式来表述。我也在继续学习中,欢迎一起探讨~
相关学习资料来源: 浅谈自然语言处理和自然语言理解《自然语言处理实践》:https://blog.csdn.net/IT_xiao_bai/article/details/81180513 如果没有相关的项目经验,这些名词可能我这样表达、这样解释还是令人费解的?里面有很多内容,都是在不断的接触、设计的过程中,再回头看时,才发现原来代表的是这个意思,原来要通过这样那样的方式才能够得以解决。 这篇主要还是自己在查漏补缺,不希望自己很多都一知半解过于迷糊,虽然真的做这事有时困惑着但还得继续进行。 还好在这工作中有充满耐心、优秀的同事一直在帮助着我,缓解了我有时冒出的困惑和不安。十分感谢~ 欢迎关注作者的微信公众号:「空明里」
手机扫一扫,阅读下载更方便˃ʍ˂ |

@版权声明
1、本网站文章、帖子等仅代表作者本人的观点,与本站立场无关。
2、转载或引用本网版权所有之内容须注明“转自(或引自)网”字样,并标明本网网址。
3、本站所有图片和资源来源于用户上传和网络,仅用作展示,如有侵权请联系站长!QQ: 13671295。





最新评论







