








人工智能快速出图!盘点 4 款大厂出品的 AI 绘画神器

扫一扫 
扫一扫 
扫一扫 
扫一扫 大家好,我是和你们聊设计的花生~ 在 6 月份的时候我写了一篇有关 AI 图像工具的文章,为大家盘点了当时热门的 4 款人工智能图像生成工具,分别是 Disco Difussion、Dall·E 2、Midjounery 和 Tiamat。自今年年初 Disco Difussion 出现后,AI 图像工具越来越受到大家的关注,各类具有强大图像处理功能的 AI 工具纷纷暂露头角。特别是 OpenAI 在今年 4 月份公布的最新技术成果 Dall·E 2,在外网引起热烈讨论,很多主流媒体争相报道,也因此引起不少互联网科技巨头的关注。 在 Dall·E 2 发布后的短短两三个月内,Google、微软、Meta(Facebook)三家互联网科技公司也纷纷推出自己在 AI 图像工具方面的研究成果,其中很多新的技术都令人眼前一亮,今天就和大家简单介绍一下这些新的 AI 图像工具。 人工智能快速出图!盘点 4 款人气超高的 AI 绘画神器大家好,我是和你们聊设计的花生~有关注 AI 绘画领域的小伙伴可能注意到,国内已经出现了能直接使用中文提示词生成 AI 图像的工具了,这就进一步降低了我们进入 AI 绘画世界的门槛,对设计师和创意工作者来说无疑是好消息。 阅读文章 >Google:ImagenImagen 官网地址: https://imagen.research.google/ 在 Dall·E 2 公布仅 1 个月的时间,Google 就公布其人工智能系统 Imagen。 Imagen 是一款文本-图像的扩散(CLIP)模型,由 Google Research 和 Google Brain 团队研发,打出的标语是“前所未有的写实感×深层次的语言理解”,即可以根据给定的提示词,生成高度契合文本含义及具有照片般真实感的图像。
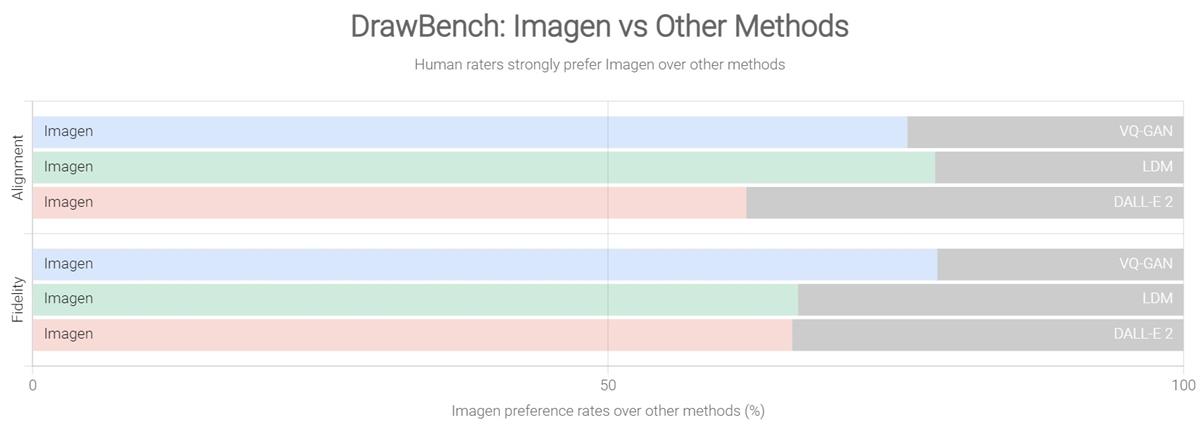
我们之前介绍过,Dall·E 2 的功能包括根据文本生成具有图像、根据文本提示修改图像内容、根据一张图像延展出风格内容相似的多张图像。相比之下,Imagen 则更加专注于根据文本生成极具真实感的图像。 据 Imagen 官网介绍,为了比较 Imagen 与其他文本-图像模型(如 DALL-E 2)在图像生成方面的性能,Google 设立一个名为 DrawBench 的文本-图像模型评估基准。这是一个具有 200 个提示文本的列表,将这些提示文本分别输入不同的模型中输出图像,再由人类参与测评。Google 表示在此基准下,参与测试的人员普遍认为“在并排比较中,无论是在图像生成的样本质量还是在图像与文本的一致性方面,Imagen 都优于其他模型”。
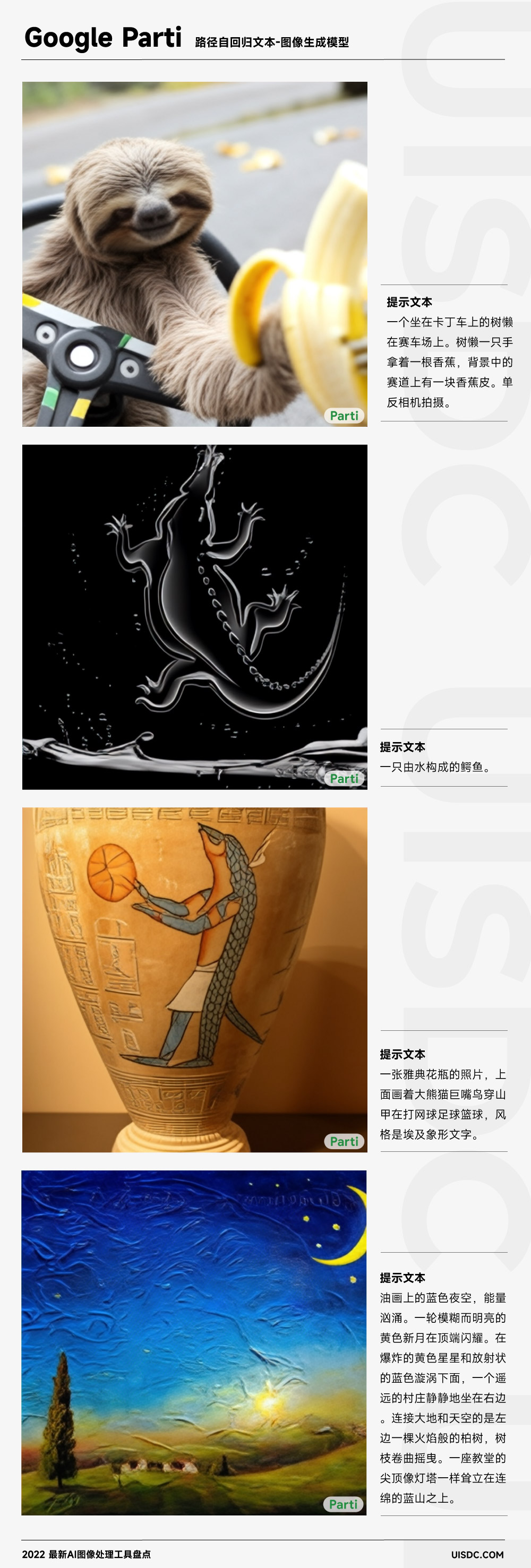
在 DrawBench 基准下,Imagen 与其他模型的测试结果对比。图片来源:Imagen 官网 10秒出图,以假乱真!设计师「用嘴修图」的愿望要成真了?大家好,我是和你们聊设计的花生~之前给大家推荐了 AI 图画生成器 Disco Difussion,它可以根据文本提示自动生成恢弘奇幻的艺术,非常适合作为艺术创作的灵感来源。 阅读文章 >Google:PartiParti 官网地址: https://parti.research.google/ Parti 是 Google 在推出 Imagen 不久后推出的另一款文本-图像生成模型。二者都是专注于通过文本生成逼真的图像,区别在于 Imagen 是扩散(CLIP)模型,而 Parti 是路径自回归文本-图像(Pathways Autoregressive Text-to-Image )生成模型,后者可实现高保真、极具真实感的图像生成。 据官网介绍,Parti 通过研究一组图像来训练自身模型来生成另一组新的图像,可供研究的图像数量越多,生成的图像就越逼真。而 Parti 则在训练过程中,将参照图像数量由 3.5 亿个提升至 200 亿个,这也使得生成图像与文本的契合度达到 75.9% 。
而且 Google 发现,在图片参照数量达到 200 亿的情况下,Parti 在生成有关抽象、世界通识知识、特定视角、书写和符号的图像时特别出色。同时也发现 Parti 可以处理长而复杂的提示,特别是这些提示涉及以下方面:
Google 还列出多组提示文本和输出图像作为例子,展示 Parti 是如何对参与者、活动、描述、地点和格式的变化做出反应的。
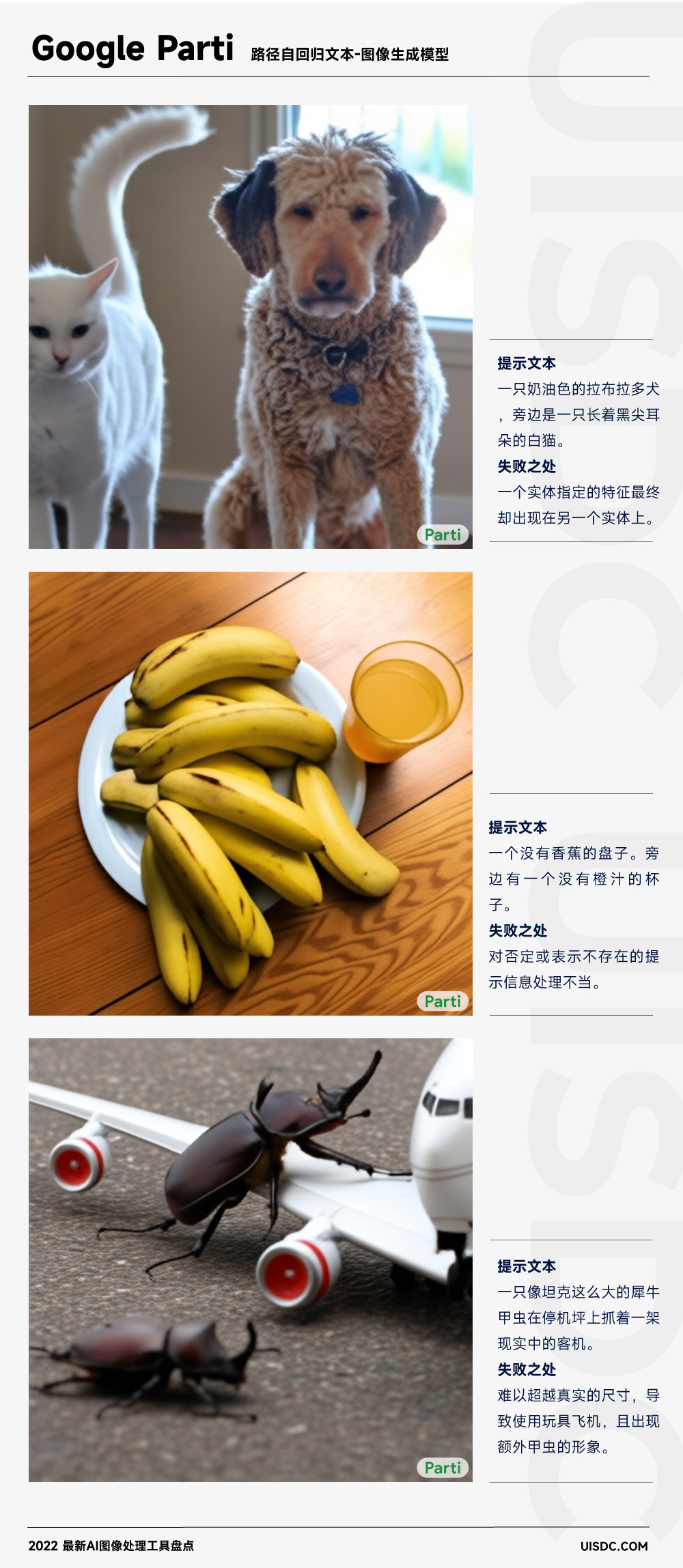
虽然在官网中 Google 展示了 Parti 在图像生成方面的优势,但也坦言这些展示出来的例子都是从很多实验结果中精挑细选出来的。并表示虽然 Parti 能根据宽泛的提示文本产生了高质量的输出,但其模型还是有许多限制,比如对文本数量、特征的错误呈现,以及对表示否定和不存在提示词的错误处理等
Meta:Make-A-Scene官方介绍: https://ai.facebook.com/blog/greater-creative-control-for-ai-image-generation/ Make-A-Scene 是 Meta 在 7 月 14 日宣布推出的一项新的 AI 技术,其最大特点是可以在用户创作的粗略草图的基础上,结合文本提示生成具体的图像,让生成图像的可控性更高。 “为了充分实现人工智能促进创造性表达的目标,人们必须能够影响和控制这些智能模型产生的内容。用户应该能够以他们喜欢的任何方式来表达自己的想法,包括语音、文本、手势甚至是绘图,并且应该易于使用和直观。”这是 Meta 在 Make-A-Scene 的介绍文章提出的观点,也很好的表现了 Make-A-Scene 的意义所在。 与 Dall·E 2 和 Imagen 这种仅凭提示文本生成图像的模型相比,Make-A-Scene 创作出的图像有了更高的可控性。使用者可以通过草图控制最终图像的具体效果,包含元素数量、大小、形式、排列方式、构图、深度等各个方面。这项新技术使 Make-A-Scene 在与其他模型进行对比测试时,在图像与文本契合度方面的评价明显高于只根据文本生成的图像的模型。当然用户也可以选择不使用草图,直接通过文本生成所需的图像。
在给定的文本提示下,不同的形状草图可以生成不同的图像
在给定的草图下,不同的提示文本可以生成形式相同但风格不同的图像 为了进一步开发这种由草图生成图像的技术,Meta 邀请了几位著名艺术家进行合作,共同探索 Make-A-Scene 如何能更好地将人们的想象力变为现实;同时也让儿童参与到这个研究过程中,让 Make-A-Scene 将小朋友充满想象力的绘画的草图变为现实。
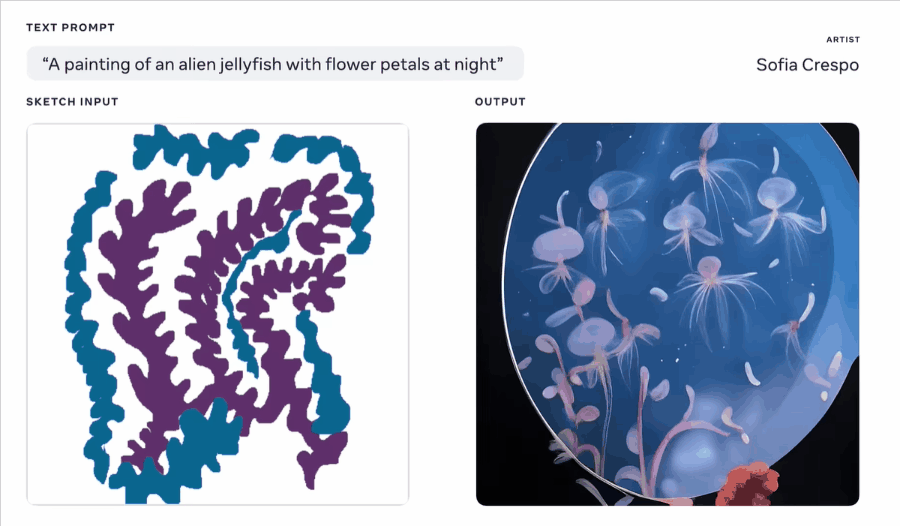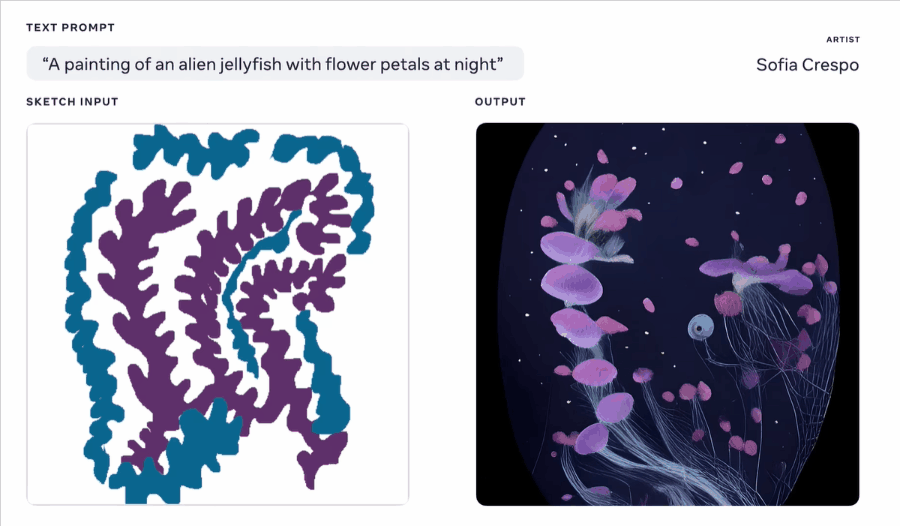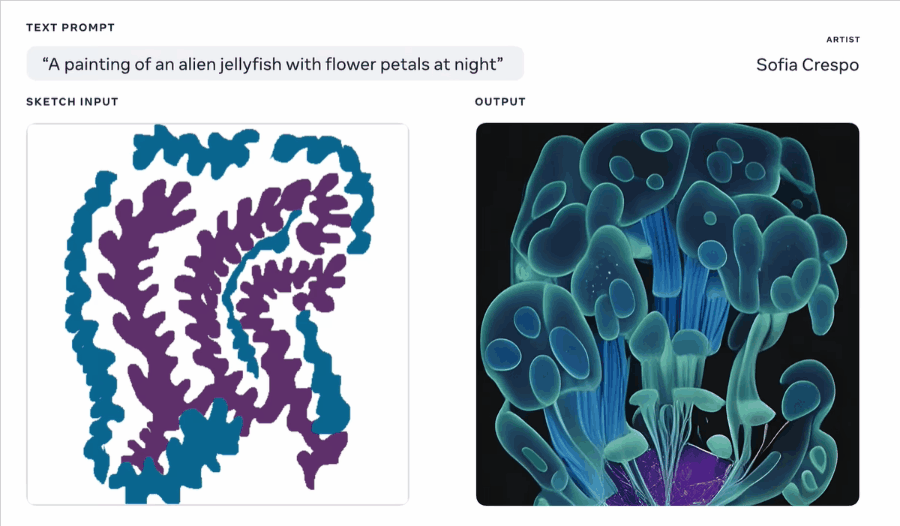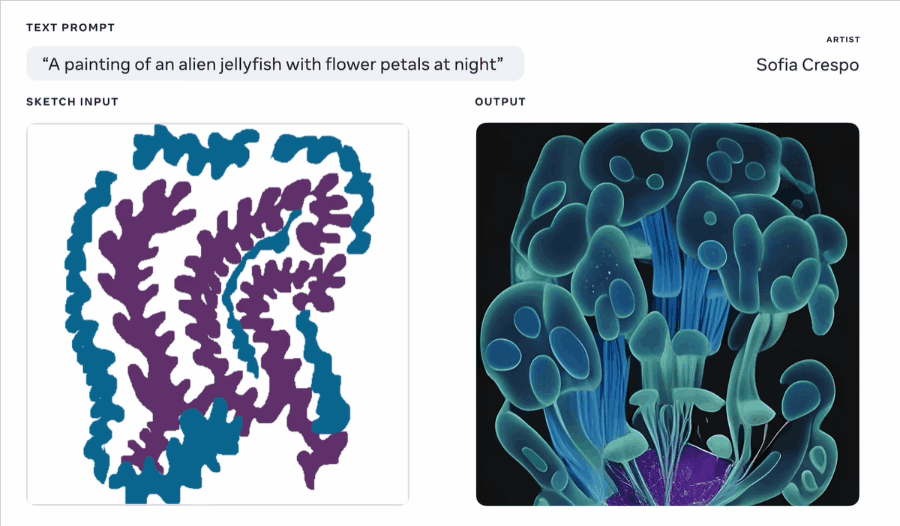
艺术家Crespo使用 Make-A-Scene ,用草图和文字提示创作新的生物插图,提示文本为:一幅夜间的有花瓣外形的外星水母的画。Crespo认为这种创作方式“这将有助于更快地发挥创造力,并帮助艺术家使用更直观的界面工作” Meta 认为通过 Make-A-Scene 这类的 AI 项目,无论原本的艺术能力如何,人们都将能无限拓展创意表达的边界,而且无论是在现实世界和虚拟世界中,人们都能将自己的愿景变为现实。熟悉 Meta 的朋友可能知道其在元宇宙方便的布局,而人工智能图像工具的发展让人们通过语言或其他方式构建虚拟空间成为可能,这对 Meta 进军元宇宙的布局也有重要意义。 堪比艺术家!被疯狂安利的 AI 插画神器 Disco Diffusion 有多强?大家好,我是和你们聊设计的花生~有关注「神器挖掘机」阿文(微博 @Simon_阿文 )的朋友,可能已经了解到他最近正在疯狂安利一款 AI 绘画神器——Disco Diffusion。 阅读文章 >Microsoft: NUWA-Infinity官网: https://nuwa-infinity.microsoft.com/#/ Github: https://github.com/microsoft/NUWA 初看到 NUWA 这个单词你会想到什么?没错,就是我们熟知的中国神话人物“女娲”。 NUWA-Infinity 是微软亚洲研究院联合北京大学、微软 Azure AI 一起推出的一款无限视觉合成的生成模型,能根据给定的文本生成任意大小的高分辨率图像或长时间视频,也是目前唯一一个能从文本生成的图像中生成长视频的 AI 模型。
NUWA-Infinity官网展示的根据《清明上河图》生成的新图像,新图像大小达到了惊人的 38912*2048 px。 之所以说是任意大小的高分辨,是因为前文提到的 Imagen 和 Parti 目前能生成图片大小为 1024*1024px,Meta 在其官方文章中表示 Make-A-Scene 的图像分辨率能达到 2048*2048px,而 NUWA-Infinity 则是真正任意大小的“ Infinity”。 在官网上,NUWA-Infinity 展示了其根据《清明上河图》生成的新图像,新图像的大小达到了惊人的 38912*2048 px。为了更好地适应页面,官方将完整的图像分割为 6 个部分,每个部分的分辨率为有 6485* 2048 px。NUWA-Infinity 还将 Windows 系统经典的草原壁纸延展为超宽的新图像,点开图片静静播放,你能体验到一种坐着绿皮火车穿过草原山川的感觉。
受动图大小限制是截取了一小段,强烈建议大家到官网感受一下 功能一:图像外延(IMAGE OUTPAINTING) NUWA-Infinity 能根据给定的图像,通过学习、想象和生成新内容,将其扩展为任意大小和分辨率的图像。图像具有超大尺寸、自我创作能力、局部细节与全局一致这 3 点特征,且这种图像拓展不限方向。
NUWA-Infinity对图像进行不同方向拓展的演示,包括向左、向右、向下、向上以及向同时向四周拓展 功能二:图像转视频( IMAGE TO VIDEO) NUWA-Infinity 可以将图像转化为视频,给静态图片带来显目的生动性。
左图为原始静态图片,右图为NUWA-Infinity根据静态图像生成的动态图像 功能三:文本转图像 (TEXT TO IMAGE) 只需简单的单词和句子,NUWA-Infinity 就可以生成各种令人叹为观止的高分辨率图像。
NUWA-Infinity根据文本提示生成的各种高清图像 除了以上 3 项主要功能,NUWA-Infinity 还在其论文中提到可以通过图像绘制和从自然语言描述中创建卡通动画,并希望这种技术能够帮助视觉内容创作者节省时间、降低成本,并提高他们的生产力和创造力。 总结本篇一共为大家介绍了 4 款由互联网科技巨头推出的最新 AI 图像工具,它们分别是:
相比 Dall·E 2,这 4 款 AI 图像工具在技术上都有不同程度的创新,虽然由于模型训练数据中存在社会偏见、害怕害怕产生有害的图像、会被公众滥用等各种原因,这些工具还不能对公众开放,但相信等未来技术更加成熟后,这些 AI 工具会给我们的工作和生活带来颠覆性的改变。 以上就是今天的全部内容,喜欢的小伙伴记得点赞收藏,也可以分享给身边感兴趣的朋友。如果你对文章内容有任何疑问,欢迎在评论区提出,我将会第一时间做出回应~
手机扫一扫,阅读下载更方便˃ʍ˂ |










@版权声明
1、本网站文章、帖子等仅代表作者本人的观点,与本站立场无关。
2、转载或引用本网版权所有之内容须注明“转自(或引自)网”字样,并标明本网网址。
3、本站所有图片和资源来源于用户上传和网络,仅用作展示,如有侵权请联系站长!QQ: 13671295。





最新评论







