





AI绘画未来如何改进?来看斯坦福教授的预测!

扫一扫 
扫一扫 
扫一扫 
扫一扫 编者按:这篇文章是来自斯坦福的年轻教授 Maneesh Agrawala,他本人既是斯坦福计算机专业的教授,也是斯坦福大学布朗媒体创新研究所的所长。他在去年 HAI 2022 秋季会议上发布了演讲「AI回路:演进中的人类」,而这篇文章正是演讲内容修订后的版本。对于 AIGC 当下存在的深层问题,AI 的逻辑以及未来可能的改进方式,给出了详尽的解读和预测。以下是正文: 最近我决定更新一下我的个人网站的图片资料:
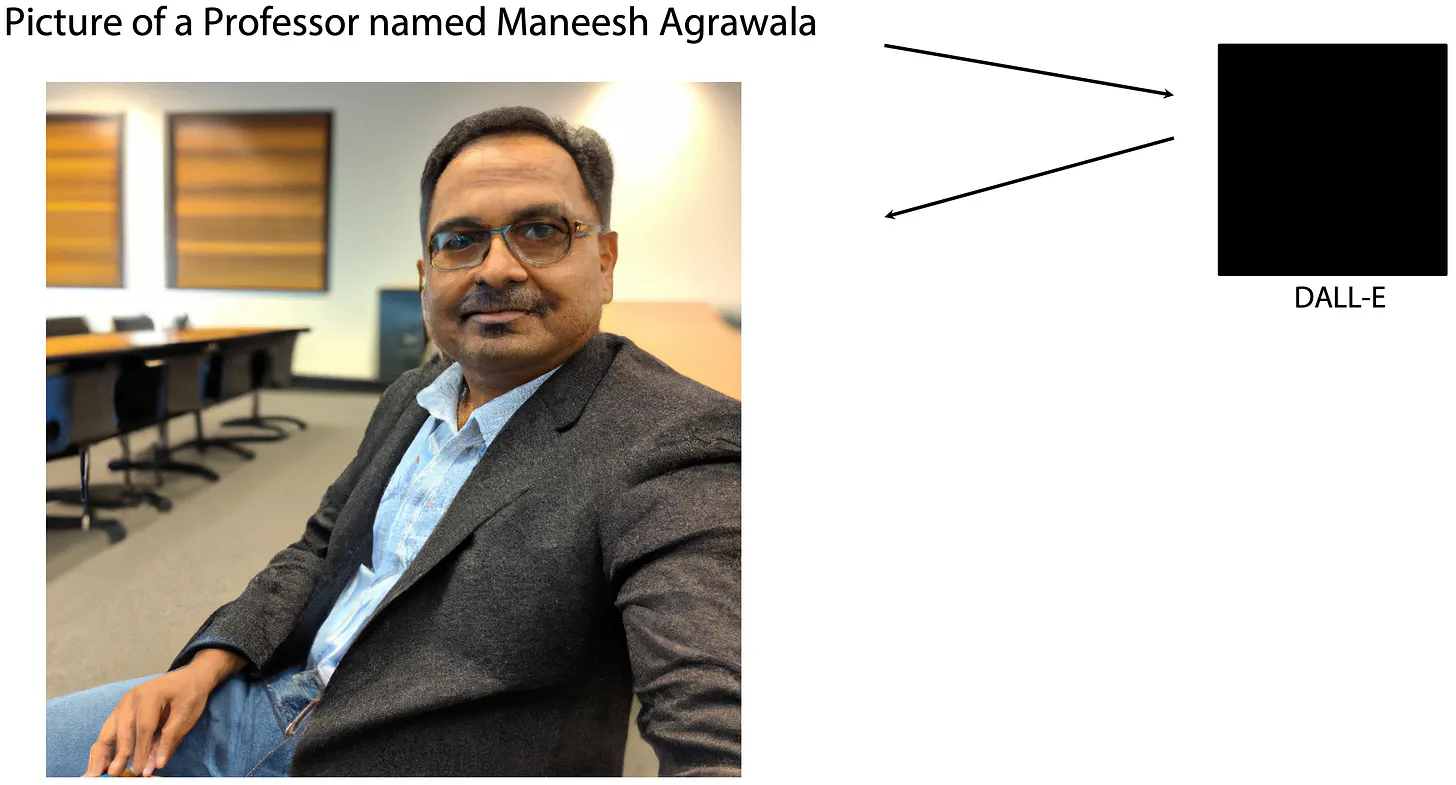
作为一名计算机专业的教授,我觉得现在制作一张高质量照片,最简单的方法,就是使用 DALL-E2 来生成。所以我写了一个简单的 prompt:「Picture of a Professor named Maneesh Agrawala」,然后 DALL-E2 给我生成了……额……这张照片:
根据我文本提示,它生成了一张看起来有着明显印度裔特征的男性,给他穿上了看起来「专业」的服装,并且把场景设置在一个学术研究室当中。从整体上来看,物体、灯光、阴影和色彩都是连贯的,是单一且统一的照片。我对于 AI 生成的照片总体上是不会吹毛求疵的,不过手看起来比较奇怪,有一边眼镜腿没了,当然,从我更人需求的角度出发,我很希望它生成这个角色看起来年轻一点。 总体上来看,AI 能够生成如此之逼真的照片确实是令人惊艳的,这是人类历史上从未有过的数字超能力。 AI 能生成的不止是图片内容。先走的生成式 AI 对于用户而言,是一个巨大的黑箱。将自然语言作为输入内容,AI 能够生成素质惊人的文本内容(GPT4,ChatGPT),图片内容(DALL-E2、Stable Diffusion、Midjourney),视频内容(Make-a-Video),3D 模型(DreamFusion)甚至程序代码(Copilot , Codex )。
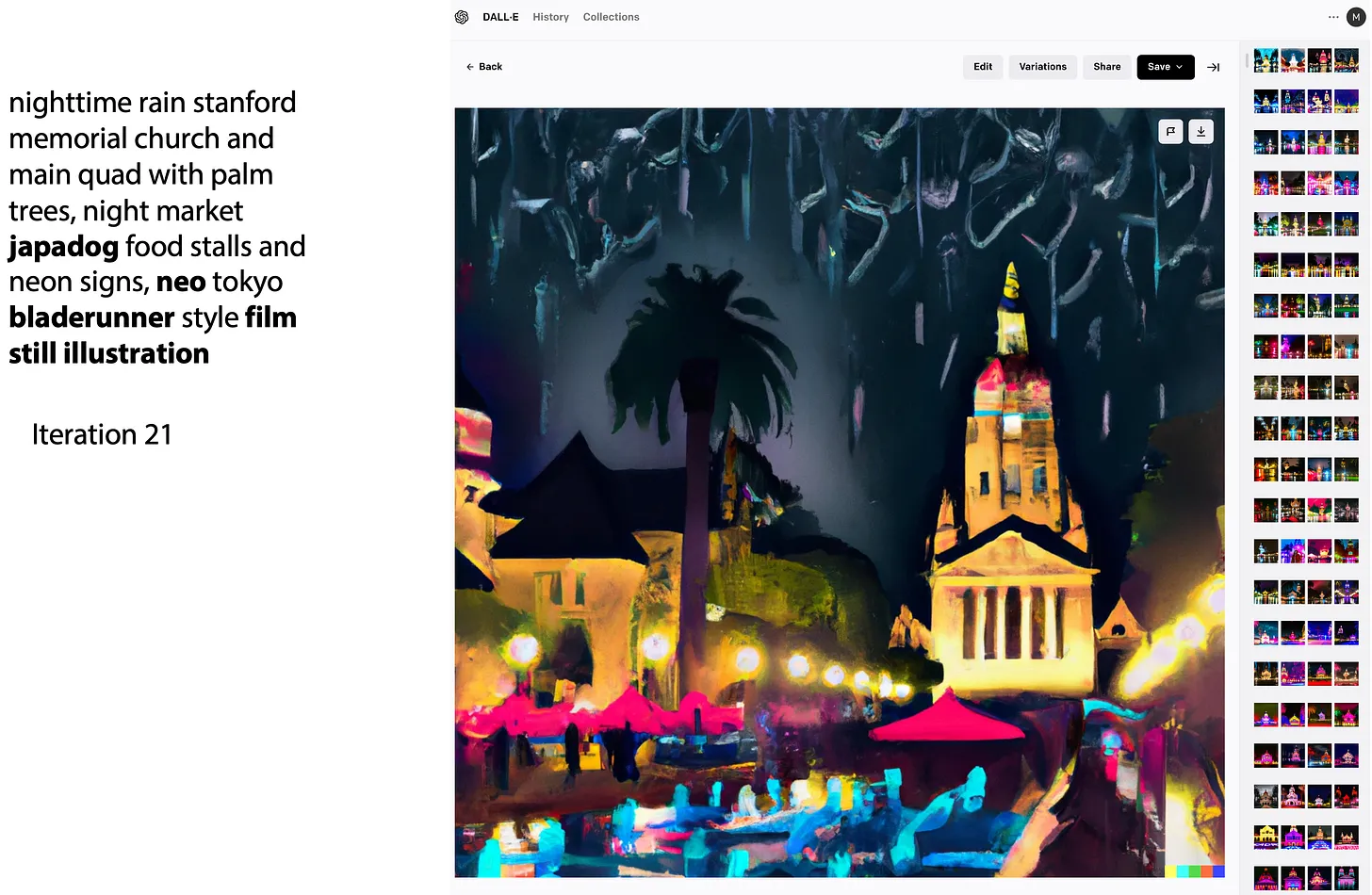
那么这次我们使用 DALL-E2 重新生成一张照片看看吧。这次, 我想看看如果斯坦福以《银翼杀手》的风格呈现出来的时候,会是什么样子。斯坦福最典型的建筑就它的主广场,中间是被棕榈树包围的纪念教堂,而谈及《银翼杀手》的时候,我能想到的是霓虹灯,拥挤的夜市,连绵的雨水和大排档。所以我撰写了 prompt:「stanford memorial church with neon signage in the style of bladerunner」。
在第一次迭代的时候,生成的图片并没有呈现主广场和棕榈树,所以我将「And main quad」添加到第二轮的 prompt 当中,在第三轮迭代中,我加入了「with palm tree」,生成的图像越来越像斯坦福的主广场,但是和《银翼杀手》的夜景没有啥关系。我开始周期性地修改 prompt,尝试找到更合适的 prompt,以产出我想要的图片内容。在第 21 次迭代之后,我在 DALL-E2 耗费了好几个小时,我决定在此止步。
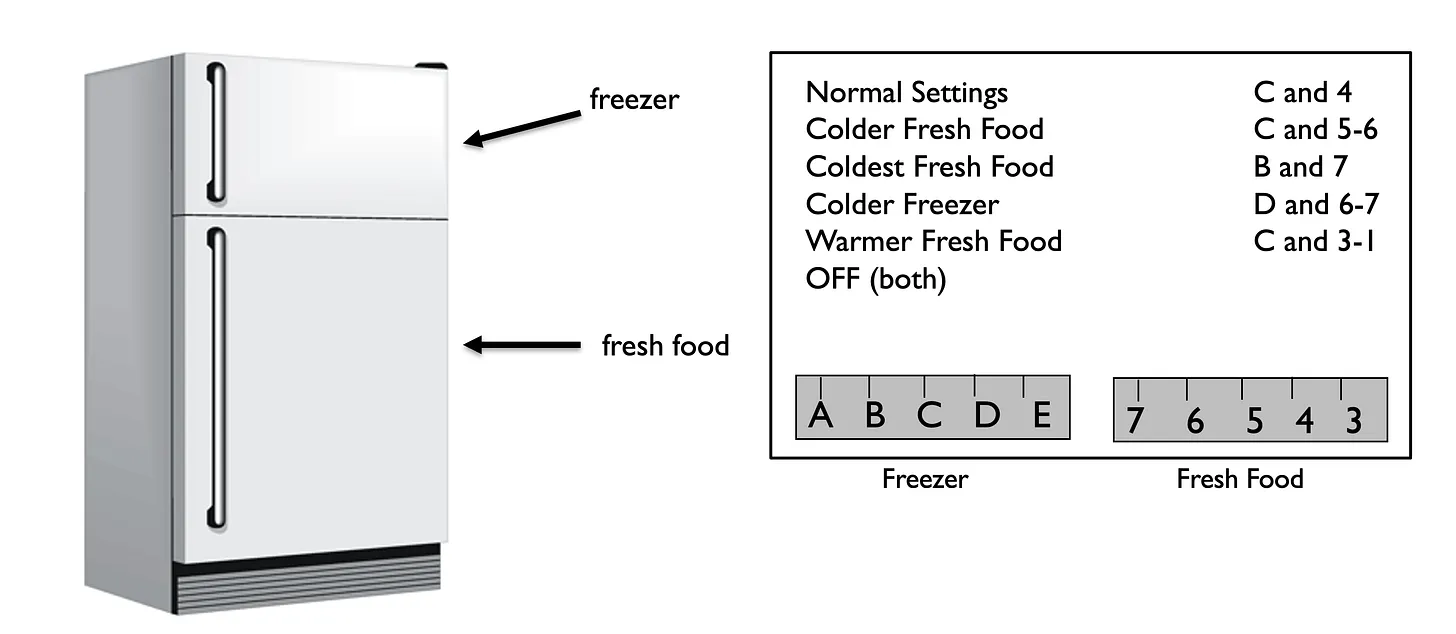
实际上,最终生成的图片依然不符合我的预期。更糟糕的是,我不清楚如何更改 prompt 以确保 AI 生成的内容能够进一步靠近我的想法。 这个过程令人沮丧。(这大概才是绝大多数 AIGC 内容产出的真实情况吧?) 事实上,寻求有效的 prompt 是如此之艰难,以至于现在诞生了专门的论坛(比如 PromptHero、Arthub.ai、Reddit/StableDiffusion)来搜集和分享各种 prompt,甚至还诞生了专门买卖 prompt 的市场(promptbase),还诞生了大量的关于 prompt 的研究性的论文。 良好的 UI 提供了可预测的概念模型要理解为什么写出有效的 prompt 很困难,我认为唐纳德诺曼的《设计心理学》当中提及的一件轶事非常具有启发意义。这个故事说的是他自己拥有一个冰箱,而冰箱内设置温度的功能极度难用,因为它的温控大概是这样的:
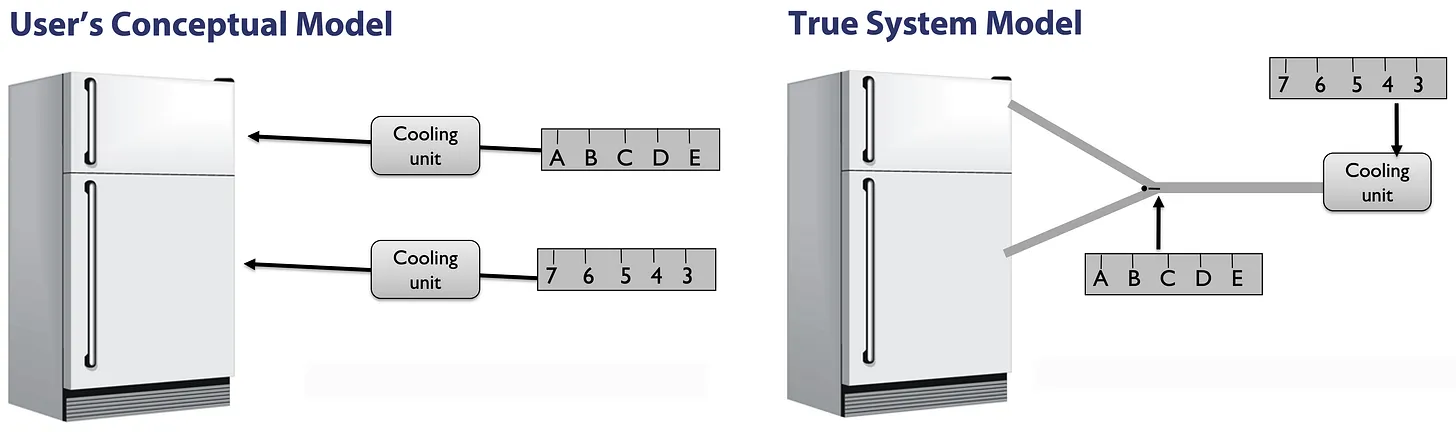
这个冰箱有着典型的冷冻室和冷藏室,它的两套设温控设施让人觉得两者有着独立的控制系统,实际上这个冰箱仅有一个冷却装置,而控制两者温度主要依靠一个阀门,来分配两者所用的冷气。这也意味着,原本的控制功能已经很难理解很难用了,而实际上的体系比我们看到的更加复杂,使用一个你看不到的阀门来耦合控制。
使用不正确的概念模型,用户不仅无法预测输入的数值,也无法掌控输出的效果。实际在操作的时候,用户需要操控 (i) 设置控件进行调整,然后(ii)等待 24 小时等到温度稳定下来,并且 (iii) 检查最终的温度是否符合他们的预期,如果结果稳定且符合预期还好说,如果不符合,需要返回步骤 (i) 。这种操作带来的沮丧感,其实和当前 AI 给人的感觉类似。 对我来说,这件事情给我的主要启示有 2 点:
UI 设计师的工作之一,就是创建一个用户可预测的概念模型。 AI 黑匣子不提供预测概念模型生成式 AI 的黑盒状态,其实是最糟糕的界面,因为它们还无法给用户提供可预测的概念模型,目前绝大多数人都不清楚 AI 是如何将自然语言 prompt 转化为最终的输出结果,即使是 AI 的设计者通常也无法确知,怎样去构建一个让用户可以理解和预测的概念模型,来帮助用户更好输出内容。 现在回到 DALL-E2 ,我试着使用「Picture of a cool, young Computer Science Professor named Maneesh Agrawala」来让它为我创建一个更好的照片:
很多时候我确实不知道 prompt 是如何影响图片的,比如我使用「Cool」这个词,它映射到图片当中的特征是运动外套和 T恤的组合,还是年轻的面容?而「Computer Science」 是否意味着 DALL-E3 需要输出写实的图片而非插画?没有逻辑顺畅的预测概念模型,我也不知道答案是什么。我唯一能做的和大家一样,就是不停输入和修改 prompt 来等待结果。 人类也是糟糕的 UI,但是比 AI 强一点AI 的目标之一,是像人一样创造。你可能会说,自然语言是人和人进行沟通的语言,显然人是更好的 UI,这一点我不完全同意。人类本身也是产出垃圾内容的 UI。人类的可怕之处和 AI 黑箱的缺陷是完全相同的。当我们面对另外一个人的时候,我们其实面对着同样的问题,我们通常很难准确预测对方回复你的语言是什么。
就目前而言,人类比起 AI 黑箱更优,这主要有两方面的原因。 首先,身为人类的我们,在预测人类合作方的「行为模式」的时候,是根据自身响应需求的方式来预测的,也就是「以己度人」。我们对于行为模式和概念模型,有很强的先验性,因为我们会假设对方和我们一样。 其次,根据 Herb Clark 等语言学家所指出的,我们可以和人类合作方通过交谈,来构建共识,共享相同的语义。我们可以在语言沟通中,逐步消除歧义和误解,并且完善和调整策略。 共同性、语义共享和修复策略是人类协作的基础。 尽管人类之间拥有这样的优势,和另一个人想要形成高质量的协作,依然需要通过多次迭代才能完成。最有效的合作通常需要数周、数月乃至于数年的对话,才能建立起共同点(想想婚姻关系吧)。 正如我所说的,人类是可怕的 UI,但是依然是比 AI 黑箱更好的 UI。 向拥有对话界面的 AIGC 前进那么我们要如何才能创建出更好的 AI 工具呢?有一种方法是支持对话式的交互。ChatGPT 等文本生成式工具,已经开始这么做了。这些工具开始支持多轮对话,可以是作为未来人与 AI 进行有效沟通的基础。上下文环境让 AI 和用户都可以参考之前对话中内容的概念,以此为基础达成共识。不过不清楚目前的 AI 系统包含有多少常识,AI 对语义概念的理解似乎还有所不足。但是人类用户而言,ChatGPT 到底懂得多少其实是不确知的,因此对话通常需要进行多轮来回,双方才能构建起基本的共识。此外,AI 和用户对话本身并不会直接更新 AI 本身的模型,为这些模型增加常识、基础概念、推理能力,依然是目前 AI 研究的主要推动力。
Prompt-to-Prompt image editing [Hertz 2022] 自然语言通常是模棱两可的。人类通过对话,来逐步消减歧义,确保大家在讨论的是同一件事情。有研究人员已开始将这种修复机制应用到文本生成图片的 AI 系统当中,比如 Prompt-to-Prompt image editing [Hertz 2022] , 用户可以先用 prompt 生成图片,然后优化 prompt 生成新的图片,这个过程中只需要进行微小的调整即可,上图中,通过添加额外的关键词,生成了更加准确的内容。这本身就是一种改进的方式。
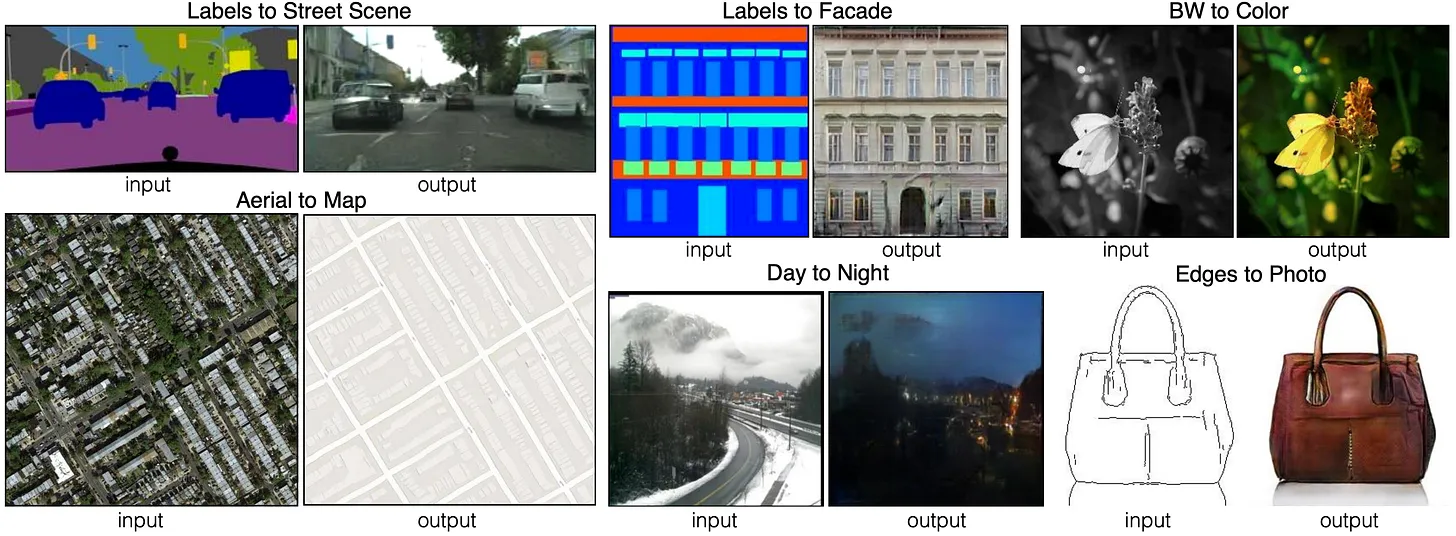
减少自然语言歧义的另外一种方法,是让用户添加约束条件。图到图转化 (Image-to-image translation [Isola 2016])就是一种典型的约束方式,通过机器学习生成对抗网络(GAN),在这种环境下,当你输入一种类型的图像(比如标签图、轮廓图),就能生成另外一类图像(比如照片或者地图),输入的图像会约束输入图像的特征。这样的约束方式比起用户模糊的语言描述会显得更强,提供了更加精确的空间特征。如今我们手底下很多小组在文本转图像的 AI 交互中,使用了这种方式来强化上下文环境。
对话式交互能超越自然语言单一命令。在文本转图像的 AI 模型研究中,很多 AI 研究者已经开始研究「建立共识」的方法。Textual Inversion [Gal 2022] 和 DreamBooth [Ruiz 2022] 都会让用户提供示例图,AI 模型则会将文本 prompt 和这些图像示例关联起来,这样用户和 AI 会建立某种共通的信息基础。
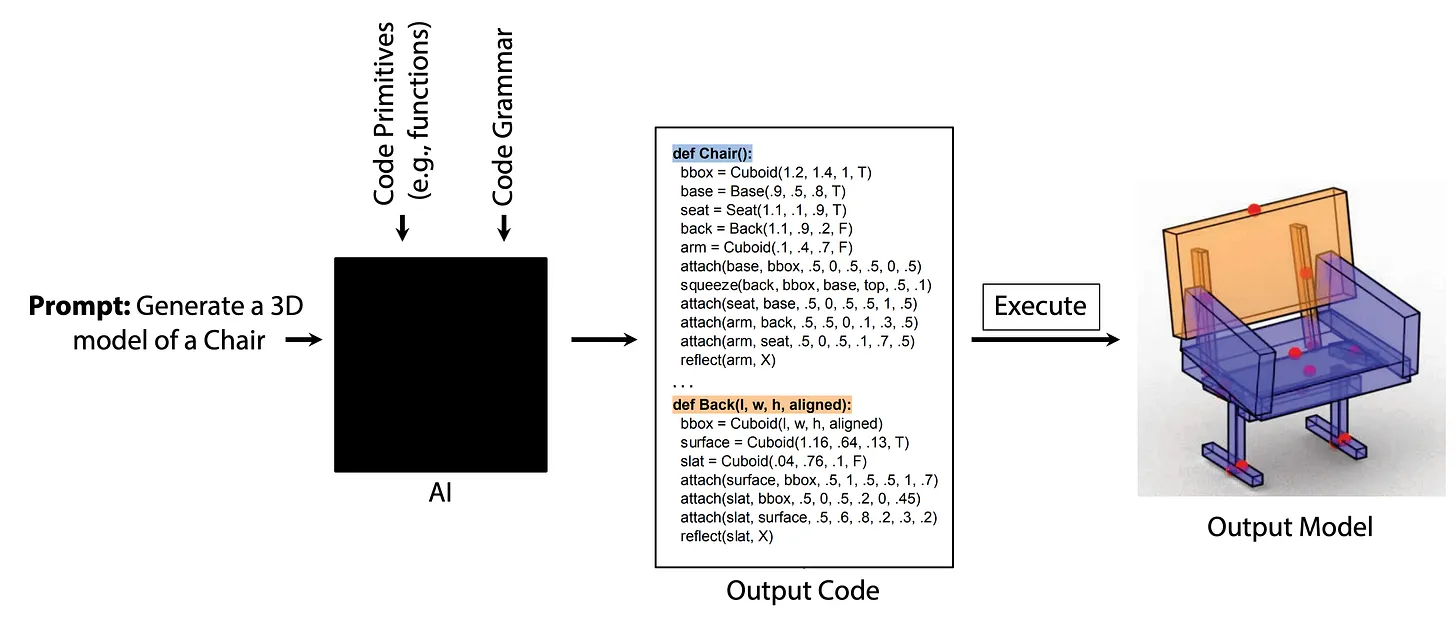
而「神经符号法」则提供了另外一种创建 AI 模型对话界面的图形。一个 AI 模型不是直接生成内容,而是生成某种程序,只有运行了这种程序才能生成内容,这种程序在某种程度上就是 「共识」本身,它是人类和 AI 可以以相同方式理解的东西,而这就是将编程语言语义形式化的基础。这意味着,即使没有明确的语义,开发者依然可以通过检测代码内容来确定 AI 是否在做「正确的事情」。这个时候,开发者可以在编程语言层面上给 AI 提供修复建议,而不是简单的使用自然命令。 结语AIGC 的模型是令人惊叹的,但是它依然是糟糕的界面,只要输入和输出之间的映射不明确,它就一直是个问题。我们可以启用对话式交互来改进 AI,创建更多的「共识」。 提高3倍效率!能落地的AI绘画&设计系统课来了!如何快速入门AI绘画和AI设计? 阅读文章 >手机扫一扫,阅读下载更方便˃ʍ˂ |








@版权声明
1、本网站文章、帖子等仅代表作者本人的观点,与本站立场无关。
2、转载或引用本网版权所有之内容须注明“转自(或引自)网”字样,并标明本网网址。
3、本站所有图片和资源来源于用户上传和网络,仅用作展示,如有侵权请联系站长!QQ: 13671295。





最新评论







