





AI绘画基础科普!一次性帮你搞懂所有技术名词

扫一扫 
扫一扫 
扫一扫 
扫一扫
近期,以 Stable Diffusion、Dall-E、Midjourney 等软件或算法为代表的 AI 绘图技术引起了广泛关注。尤其是自 2022 年 8 月 Stable Diffusion 模型开源以来,更是加速了这一领域的发展。 对于初学者来说,面对这些令人惊叹的 AI 绘图作品,他们既想了解绘图软件的使用和技巧,又面对着诸如 Lora、ControlNet、Dall-E 等复杂术语,不知道从何入手。通过收集资料,本文将从以下四个方面介绍目前最流行的 AI 绘图工具和模型训练方法,力求用通俗易懂的语言帮助大家理清术语背后的真实含义。
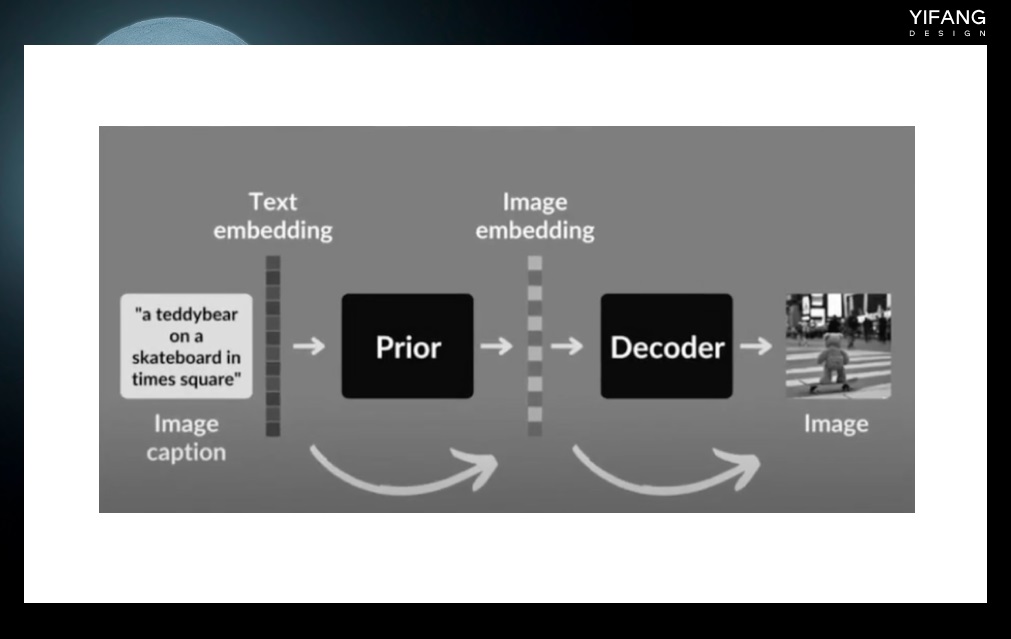
一、文生图算法简介text to image 技术,又称为文生图,是一种基于自然语言描述生成图像的技术。其历史可以追溯到 20 世纪 80 年代。
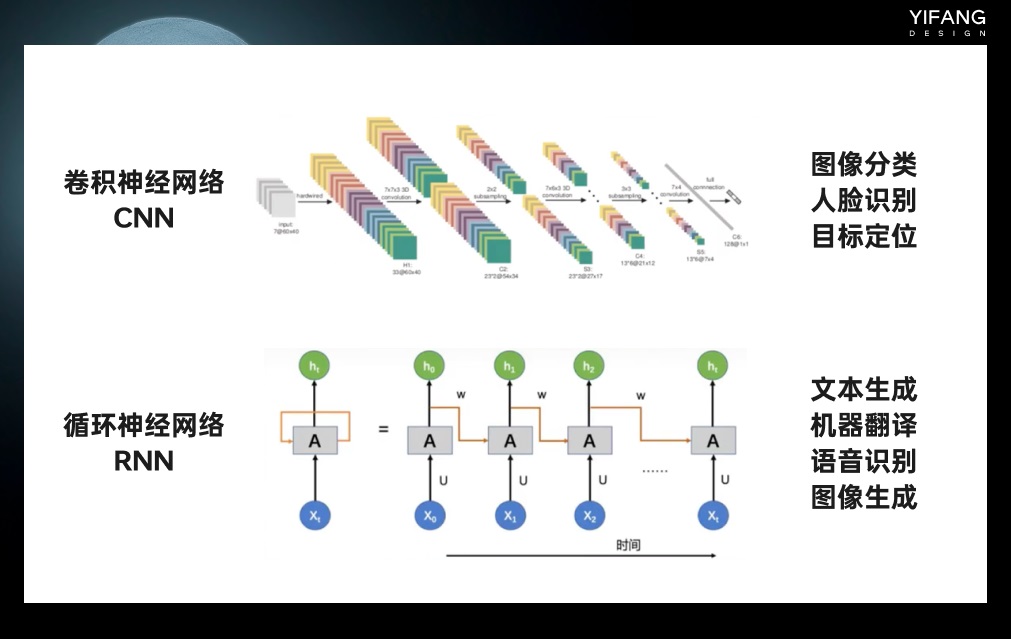
随着深度学习技术的发展,特别是卷积神经网络 CNN 和循环神经网络 RNN 的出现,text to image 技术开始采用神经网络模型进行训练和生成。
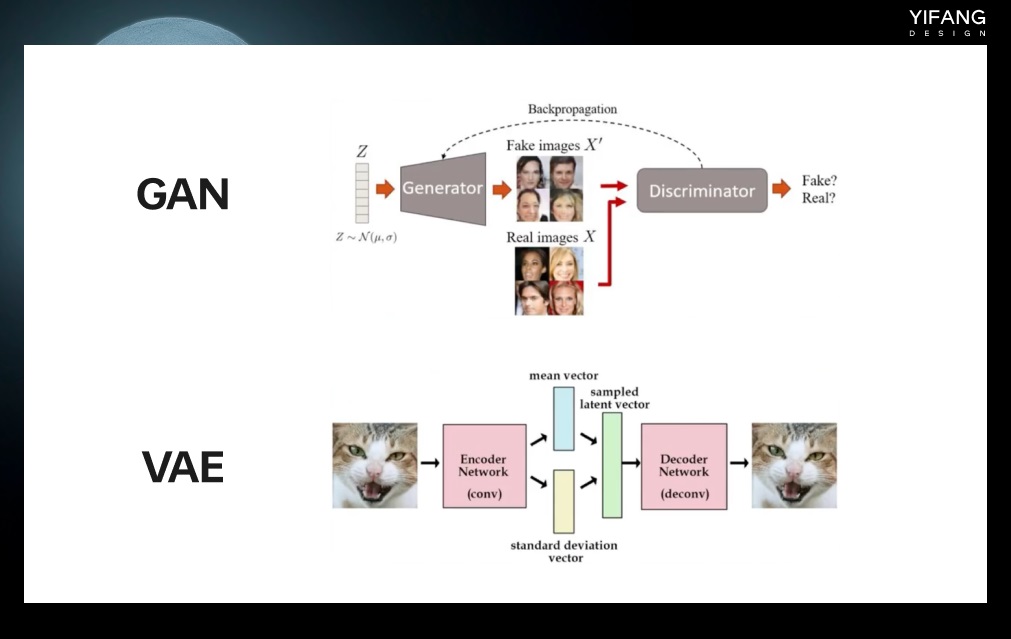
GAN(generative adversarial networks)和 VAE(variational auto encoder)算法是最早被应用于 text to image 任务的算法。
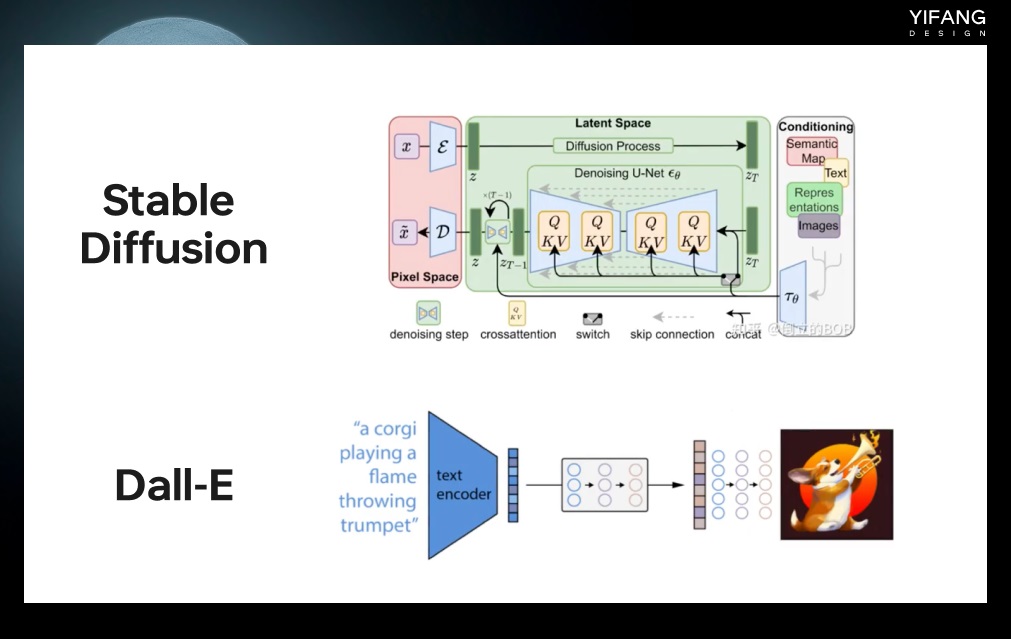
随着计算机硬件和算法的不断进步,越来越多的新算法涌现出来,例如 Stable Diffusion 和 Dall-E 等。相较于传统算法如 GAN 和 VAE,这些新算法在生成高分辨率、高质量的图片方面表现更加卓越。
Stable Diffusion(稳定扩散)是基于 DPM(Diffusion Probabistic models)的改进版本,DPM 是一种概率建模方法,旨在使用初始状态的噪声扰动来生成图像。模型会首先生成一张初始状态的噪声图像,然后通过逐步的运算过程逐渐消除噪声,将图像转换为目标图像。这也是我们在进行 Stable Diffusion 绘图时,首先需要确定噪声采样方式和采样步长的原因。
Stable Diffusion 是由 Stability AI COMP、VIZ LMU 和 Runway 合作发布的一种人工智能技术,其源代码在 2022 年 8 月公开于 GitHub,任何人都可以拷贝和使用。该模型是使用包含 15 亿个图像文本数据的公开数据集 Line 5B 进行训练的。训练时使用了 256 个 Nvidia A100 GPU,在亚马逊网络服务上花费了 150,000 个 GPU 小时,总成本为 60 万美元。
Dall-E 是 OpenAI 公司于 2021 年 1 月发布的一种基于 Transformer 和 GAN 的文本到图像生成算法,使用了大规模的预训练技术和自监督学习方法。Dall-E 的训练集包括了超过 250 万张图像和文本描述的组合。该算法的灵感来源于 2020 年 7 月 OpenAI 发布的 GPT-3 模型,后者是一种可以生成具有语言能力的人工智能技术。Dall-E 则是将 GPT-3 的思想应用于图像生成,从而实现了文本到图像的转换。
2022 年 2 月,OpenAI 发布了 Dall-E2。相比于上一版本,Dall-E2 生成的图像质量更高,而且可以生成更加复杂和多样化的图像。Dall-E2 的训练集包括了超过 1 亿张图像和文本描述的组合,比 Dall-E 的训练集大 40 倍。
当前 Dall-E 算法虽未开源,但已经有人尝试创建 Dall-E 的开源实现。比如,Crayon 前身为 Doy Mini,于 2022 年在 Hugging Face 的平台上发布。 大部分的绘图工具都是基于 Stable Diffusion、Dall-E 相关的或类似或衍生的算法开发的,尤其是已经开源的稳定扩散算法。 以下是与此相关的几个常见、广泛使用的 AI 绘图工具:Midjourney、Stable Diffusion、Dall-E、NovelAI、Disco Diffusion。
二、AI 绘图工具介绍接下来给大家介绍市面上常见的 AI 绘图工具: 1. Midjourney Midjourney 是一个由 Leap Motion 的联合创始人 David Holz 创立的独立研究室,他们以相同的名称制作了一个人工智能程序,也就是我们常听到的 Midjourney 绘图软件。该软件于 2022 年 7 月 12 日进入公开测试阶段,基于 Stable Diffusion 算法开发,但尚未开源,只能通过 Discord 的机器人指令进行操作。
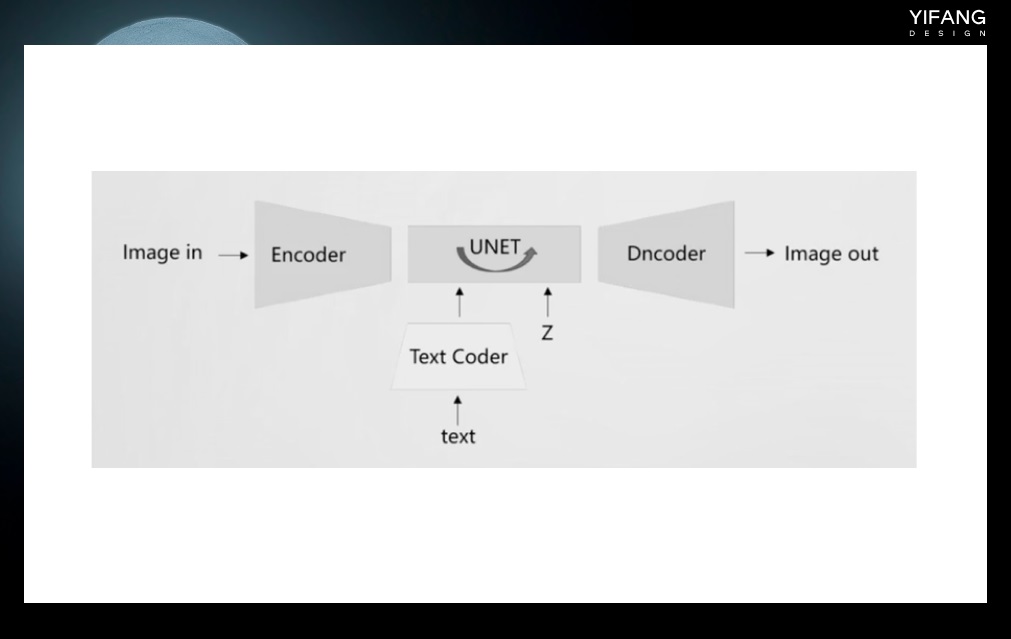
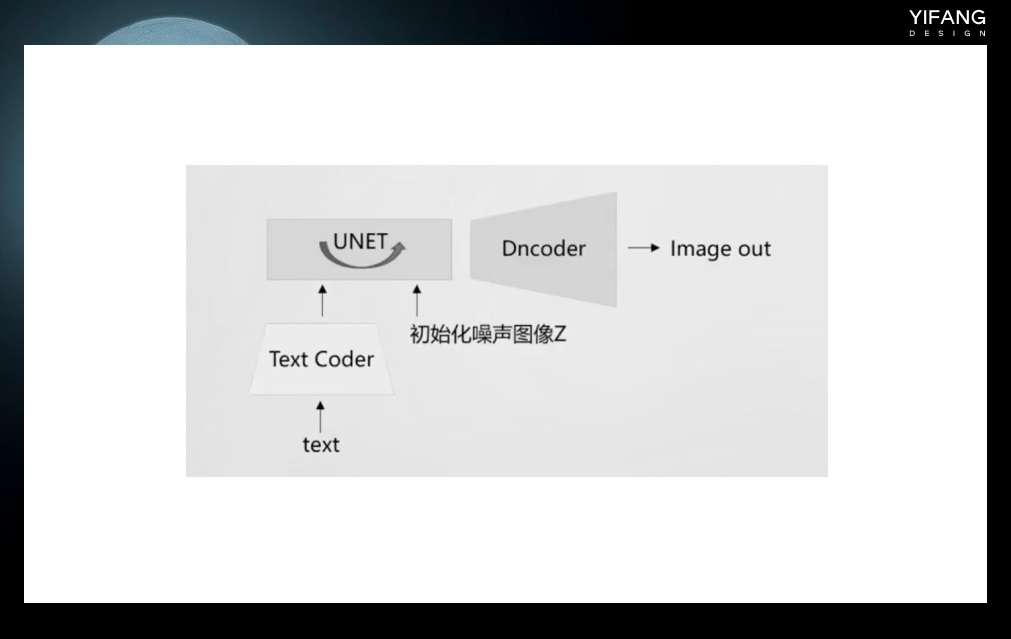
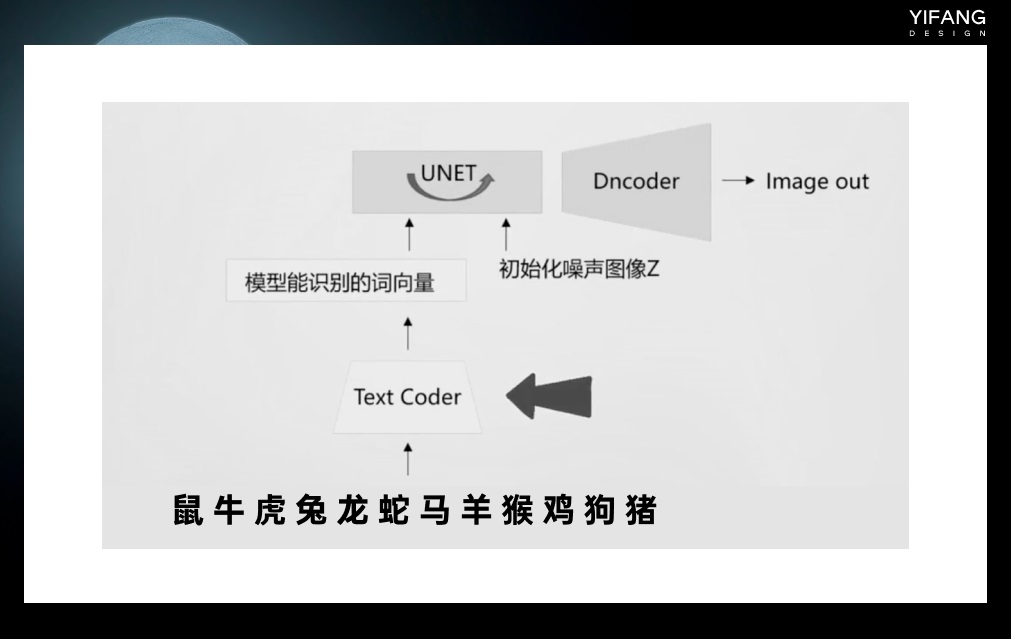
https://www.midjourney.com/app/ Discord 是一个在线聊天和语音交流平台,类似于我们常用的 QQ 聊天工具。Midjourney 官方提供了一个 discord 机器人,用户可以在 discord 中添加该机器人,进入指定的服务器进行绘图操作。具体方法是,登录 discord,在添加了 Midjourney Bot 的服务器中,在聊天框里输入“image”,然后输入绘图指令即可。 Midjourney 是一个学习成本极低、操作简单的绘图工具,生成的图片非常有艺术感,因此以艺术风格闻名。只需输入任意关键词即可获得相对满意的绘图结果。绘图者只需要专注于设计好玩实用的绘图指令(Prompt),而无需花费太多精力在软件操作本身上。但是,Midjourney 的使用需要全程科学上网,并且使用成本相对较高。由于软件未开源,生成的图片可能无法满足用户的特定需求,只能通过寻找合适的关键词配合图像编辑软件来实现。 超详细!AI 绘画神器 Midjourney 基础使用手册一、前提条件需要魔法: 新用户可免费创作 25 张图片,超过需要办会员 版权问题:会员生成的图片版权归创作者所有Midjourney相关资讯:二、注册/链接 服务器温馨提示:下方多图预警1. 注册、创建服务器① 打开Midjourney官网,右下角选择"J 阅读文章 >2. Stable Diffusion Stable Diffusion 是一种算法和模型,由 Stability.ai、CompVis-LMU 和 Runway 共同发布,于 2022 年 8 月开源。因此,用户可以下载 Stable Diffusion 的源代码,并通过各种方式在自己的电脑上进行本地部署。 将 Stable Diffusion 分解后,有以下几个结构和模型。在训练时,输入的训练图像首先通过编码器模块进行编码,以进行降维,例如从 512*512 降到 64*64,这将大大加快训练速度。输入的文本长度是不固定的,通过文本编码器(通常是 clip 模型)将其转换为固定长度的向量以进行计算。这两者结合后,输入到 UNET 网络进行训练。训练后,图像通过解码器解码后恢复为 512*512 的图像。 超详细!AI 绘画神器 Stable Diffusion 基础教程一、AI 绘画工具的选择与运用1. 工作场景下 AI 绘画工具的选择目前文生图的主流 AI 绘画平台主要有三种:Midjourney、Stable Diffusion、DALL·E。 阅读文章 >
生成图像时候只需要带入一个初始化了的噪声图像和文本,二者组合后输入 UNET 网络进行去噪,最后通过 Dncoder 还原成清晰的图像。
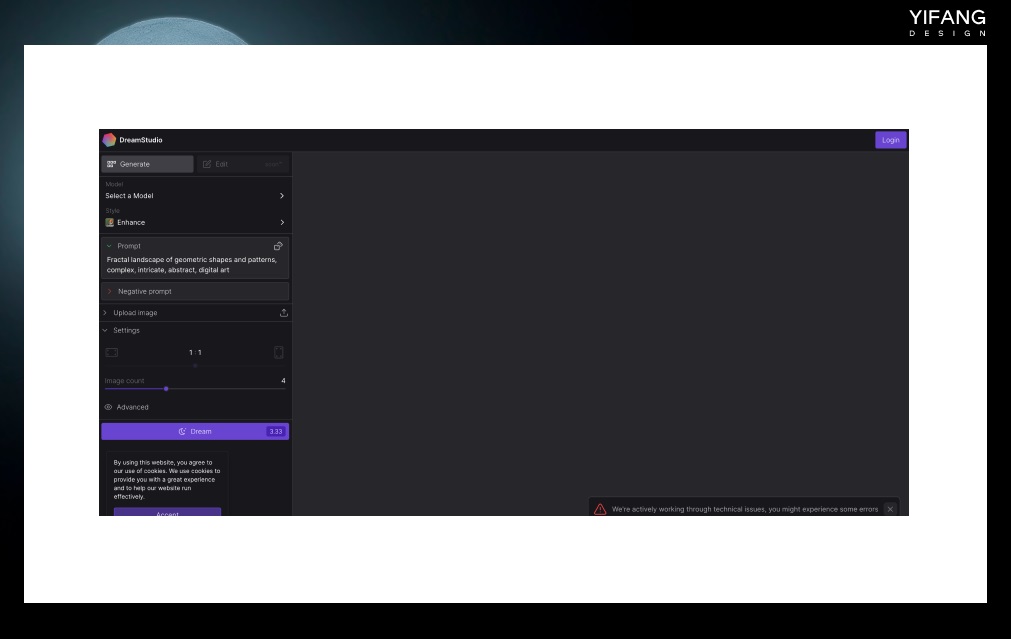
大家可能会认为安装和部署 Stable Diffusion 很困难,因为需要安装 Python 运行环境和一些依赖库,以及对 Python 语言有一定的编程经验。但是,有一些一键式的安装包可以帮助你快速搭建 stable diffusion 的环境。这些安装包包含了 Python 运行环境和相关的依赖库和代码。只需要下载安装包,然后根据指示进行几个简单的步骤,即可完成 Stable Diffusion 的安装和部署。 最受欢迎的工具包是 GitHub 上 automatic 1111 用户创建的 Stable Diffusion Web UI。它是基于 radio 库的浏览器界面交互程序。具体的安装视频可以在各大知识平台都可以搜到,这里就不展开了。 一键式安装包(包含 Python 运行环境,还集成了 Stable Diffusion 的相关依赖库和代码) https://github.com/AUTOMATIC1111/stable-diffusion-webui 目前最新的 stable diffusion 的版本是 2.1,但 2.0 以上版本砍掉了 NSFW 内容和艺术家关键词,相当于封印了很多能力。 Stable Diffusion Web UI 只是运行 Stable Diffusion 的可视化界面,就如一辆车子缺乏发动机,我们还需要从 Stability AI 的 Hugging Face 官网下载 Stable Diffusion 模型,才能开始运行 Stable Diffusion 绘图。 本地运行 Stable Diffusion 需要较高的显卡配置,建议使用显存大于 8G 的 N 卡显卡。如果配置不够但还想体验一下,Stable Diffusion 有线上版本 DreamStudio,只是需要付费使用。新用户可以获得 200 个点数,每次标准生成将消耗一个点数。
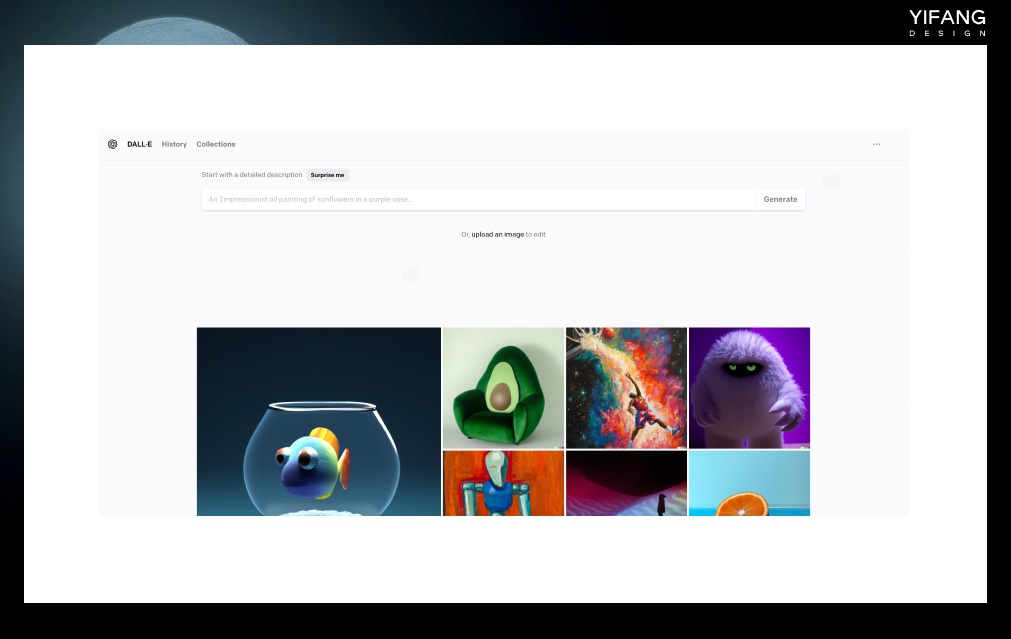
https://beta.dreamstudio.ai/generate?from=%2Fdream 3. Dall-E Dall-E 是 OpenAI 旗下的一款 AI 绘图工具软件,与 ChatGPT 同属于一个公司。最新版本 Dall-E 2 于 2022 年 2 月发布。Dall-E 可以在线使用,Dall-E 会根据这些文字描述生成一张或多张图片,并显示在屏幕上。用户可以上传自己的图片,标记图像中的区域进行进一步的编辑和修改。Dall-E 还会根据已有图像的视觉元素对图像进行二次加工,延展图片边界。
https://labs.openai.com/ 用户在注册的第一个月可以获得 50 个免费积分,每月可以获得 15 个积分,每张图片花费 1 个积分。如果需要更多的图像,用户需要付费。当前,Dall-E 算法并未公开源代码。 4. NovelAI Nova AI 是由美国特拉华州的 Anlatan 公司开发的云端软件。最初,该软件于 2021 年 6 月 15 日推出测试版,其主要功能是辅助故事写作。之后,在 2022 年 10 月 3 日,Nova AI 推出了图像生成服务,由于其生成的二次元图片效果出众,因此它被广泛认为是一个二次元图像生成网站。
https://novelai.net/ Nova AI 的图像生成模型是使用 8 个 Nvidia A100 GPU 在基于 Damburu 的约 530 万张图片的数据集上训练而得到的,其底层算法也是基于 stable diffusion 模型微调而来的。 使用 Nova AI 的方法很简单,只需登录官方网站,进入图像生成界面,输入关键字,即可生成图像。此外,由于 Novel AI 曾经发生过代码泄露,因此也可以下载 Novoai 的模型(Naifu、Naifu-diffusion)在 Stable Diffusion web UI 中使用。 5. Disco Diffusion Disco Diffusion 是最早流行起来的 AI 绘图工具,发布于 Google Clab 平台。它的源代码完全公开且免费使用,可通过浏览器运行而无需对电脑进行配置。Disco Diffusion 基于 Diffusion 扩散模型开发,是在 Stable Diffusion 发布之前最受欢迎的扩散模型之一。然而,它在绘制人物方面表现不佳,且生成一张图片需要十几二十分钟的时间,因此在 Stable Diffusion 发布后逐渐失去了市场热度。 6. 其他工具 NiJiJourney 是一个专门针对二次元绘画的 AI 绘画软件,由 Spellbrush 和 Midjourney 共同推出。使用方法与 Midjourney 基本相同,用户可以在 Discord 上输入相应的绘画指令进行绘画。目前 NiJiJourney 处于内测阶段,绘画是免费的,但是版权问题尚未明确表态。预计在正式公测时,付费用户可以获得商用权利,与 Midjourney 类似。
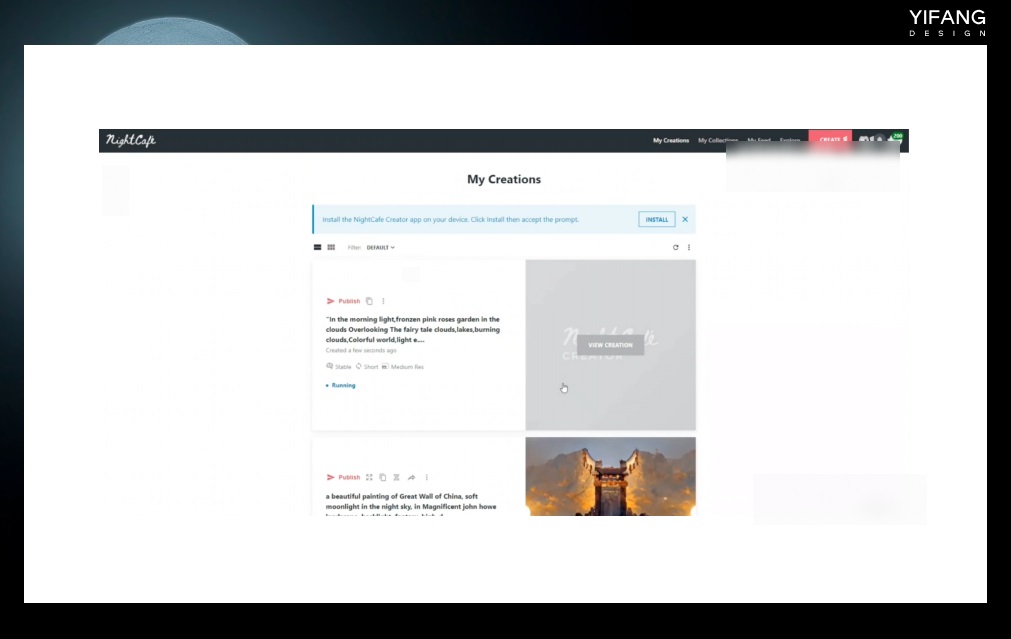
Waifu Diffusion 是一种基于扩散模型的 AI 绘图模型,它的早期版本 1.4 在动漫领域的绘图效果与 NovelAI 非常相似。有些人甚至认为 Waifu Diffusion 是在 NovelAI 模型的基础上进行微调得到的,但 Waifu Diffusion 团队表示他们的模型是 Trinart Derrida 和 Eimis Anime Diffusion 模型的合并结果。我们可以从 Hugging Face 上下载 Waifu Diffusion 模型,并在 Stable Diffusion Web UI 中使用它。 除此以外还有很多类似 Midjourney 的绘图工具,几乎都是基于 Stable Diffsion 或者类似算法进行开发。如 Leonardo AI、BlueWillow AI、Playground AI、Dreamlike、NightCafe.studio 等等。有一些还具备图像修改、图像延展等功能,尽管这些软件还处于测试阶段,需要申请才能使用,但它们生成的图片质量不输 Midjourney,因此常被拿来与 Midjourney 进行对比。 ① Leonardo AI
https://leonardo.ai/ ② BlueWillow AI
https://www.bluewillow.ai/ ③ Playground AI
https://playgroundai.com/ ④ Dreamlike
https://dreamlike.art/ ⑤ NightCafe.studio
https://nightcafe.studio/ 三、模型训练相关名词AI 大模型,也被称为基础模型(Foundation Model),是指将大量数据导入具有数亿甚至万亿级参数的模型中,通过人工智能算法进行训练。Stable Diffusion、NovelAI、Dall-E 等模型都属于大模型。这类大模型普遍的特点是参数多,训练时间长,具备泛化性、通用性、实用性,适用于各种场景的绘图。
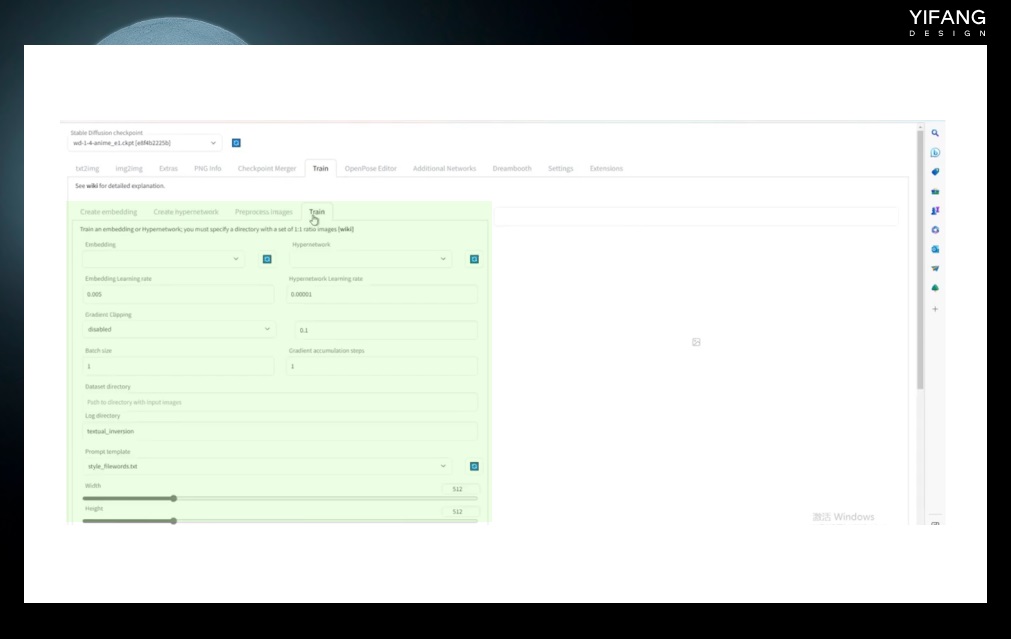
这类 AI 大模型也存在一个普遍的缺点,就是无法满足对细节控制或特定人物特定绘图风格的绘图需要。即便掌握了算法知识,训练一个好的 AI 绘图模型也需要强大的计算资源,这些计算资源对于普通人来说过于昂贵。例如 Stable Diffusion 在亚马逊网络服务上使用 256 个 NVIDIA A100 GPU 进行训练,总共花费了 15 万个 GPU 小时,成本为 60 万美元。 于是,针对这些大模型的微调技术应运而生。为了达到绘制特定人物或特定绘图风格的需要,我们不需要重新训练大模型,只要提供几张图片和一张显卡,几个小时的时间就可以实现。也就是我们常听说的 Embedding、Hypernetwork、Dreambooth、Lora、ControINet,它们都属于大模型的微调技术,可以在 Stable Diffusion Web UI 中进行训练后使用,感兴趣的话可以在 Civitai 进行下载。
1. Embedding Text Coder 就像一本词典,输入文本后 Text Coder 能快速查找到符合要求的词向量,
那如果出现新的关键词,text coder 上找不到该怎么办?这就是 Embedding 算法要做的事情,它通过训练在 Text Coder 中找到与新的词特征、风格相同的词向量。例如这个麒麟训练后可以看作龙羊虎的组合。
Embedding 算法不改变大模型的基本结构,也不改变 text coder,所以就能达到微调模型的目的。对于风格的描述,一般需要较多的关键词。Embedding 对于复杂的词汇的调整结果并不太好,定义人物需要的关键词少,所以适用于对人物的训练。
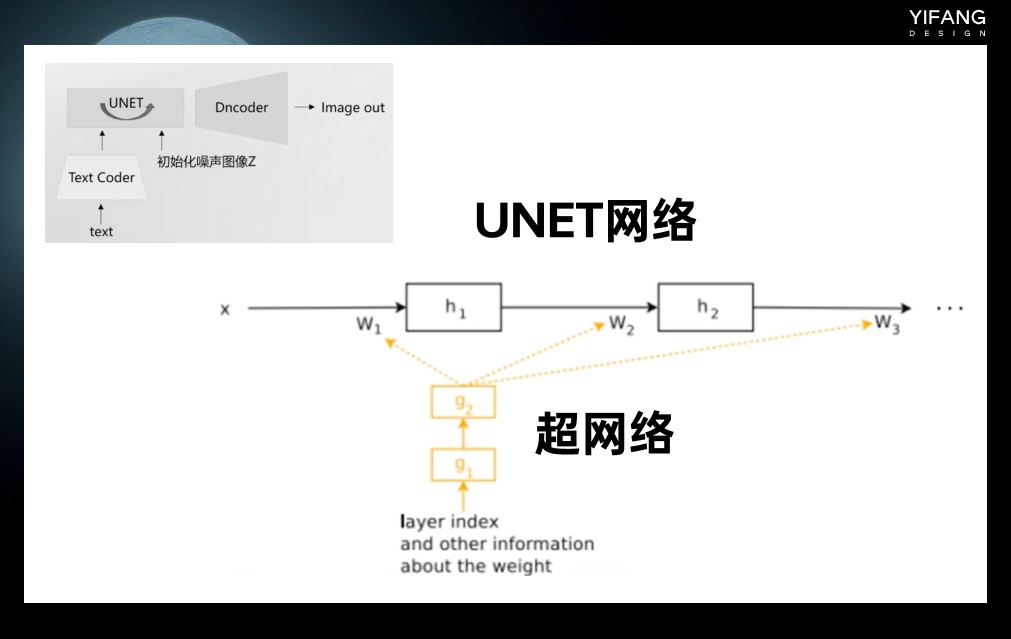
② Hypernetwork 与 Embedding 不同,Hypernetwork 是作用在 UNET 网络上的,UNET 神经网络相当于一个函数,内部有非常多的参数,Hypernetwork 通过新建一个神经网络,称之为超网络。超网络的输出的结果是 UNET 网络的参数。超网络不像 UNET,它的参数少,所以训练速度比较快,因此 Hypernetwork 能达到以较小时间空间成本微调模型的目的。
Hypernetwork 会影响整个 UNET 的参数生成,理论上更适合风格的训练。Stable Diffusion Web UI 上也继承了 Embedding 和 Hypernetwork 的训练环境。
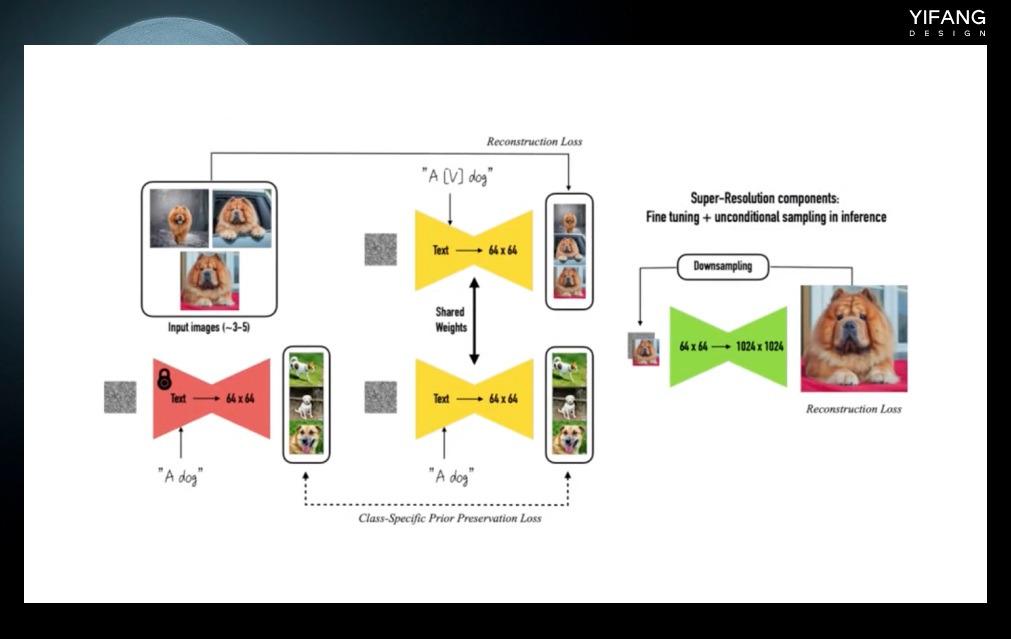
3. Dreambooth Dreambooth 是 Google 在 2022 年 8 月提出的一种新的网络模型,它的强大之处在于能完整地保留你想要关键视觉特征。例如图中最左边的黄色闹钟上面一个醒目的黄色的。采用 Dreambooth 生成的新图像可以准确还原这个图像最右边这个样子。这需要模型能够准确识别物体的细节。你只需提供 3- 5 张的图像和文本提示作为输入,就可以达到很好的效果。Dreambooth 适合人物训练,改版的 Dreambooth 方法 native train 适合于风格的训练。
Dreambooth 要求同时提供特征词加类别和类别文本图片信息带入模型进行训练,例如 a dog 和 a [V] dog。这样做的好处是既可以保留类别的原始信息,又可以学习到特征词加类别的新的信息。
4. LoRA LoRA(Low-Rank Adaptation of large Language Models)是由微软研究员开发的一种用于微调大模型的技术。该技术建议冻结预训练模型的权重,并在每个 Transformer 块中注入可训练层,从而在保持大部分参数不变的情况下,调整局部的一些模型参数。由于不需要重新计算模型的权重参数的梯度,这大大减少了需要训练的计算量,并降低了 GPU 的内存要求。 使用 LoRA 模型进行微调可以为我们提供更自由、更便捷的微调模型的方式。例如,它使我们能够在基本模型的基础上进一步指定整体风格、指定人脸等等。此外,LoRA 模型本身非常小,即插即用,非常方便易用。 5. Controlnet Controlnet 是当前备受瞩目的 AI 绘图算法之一。它是一种神经网络结构,通过添加额外的条件来控制基础扩散模型,从而实现对图像构图或人物姿势的精细控制。结合文生图的操作,它还能实现线稿转全彩图的功能。 Controlnet 的意义在于它不再需要通过大量的关键词来堆砌构图效果。即使使用大量关键词,生成的效果也难以令人满意。借助 Controlnet 可以在最开始就引导它往你需要的构图方向上走,从而实现更准确的图像生成。 四 、VAE 模型的作用正如我们之前介绍的,Stable Diffusion 在训练时会有一个编码(Encoder)和解码(Dncoder)的过程,我们将编码和解码模型称为 VAE 模型。预训练的模型,如官网下载的 Stable Diffusion 模型,一般都是内置了训练好的 VAE 模型的,不用我们再额外挂载。但有些大模型并不内置 VAE 模型,或者 VAE 模型经过多次训练融合不能使用了,就需要额外下载,并在 Stable Diffusion Web UI 中添加设置。如果不添加,出图的色彩饱和度可能会出问题,发灰或变得不清晰。大家可以根据模型说明信息来确定是否要下载 VAE。 提高3倍效率!能落地的AI绘画&设计系统课来了!如何快速入门AI绘画和AI设计? 阅读文章 >欢迎关注作者微信公众号: AI Design Center
手机扫一扫,阅读下载更方便˃ʍ˂ |














@版权声明
1、本网站文章、帖子等仅代表作者本人的观点,与本站立场无关。
2、转载或引用本网版权所有之内容须注明“转自(或引自)网”字样,并标明本网网址。
3、本站所有图片和资源来源于用户上传和网络,仅用作展示,如有侵权请联系站长!QQ: 13671295。





最新评论







