








超简单!教你零基础入门AI绘画神器Stable Diffusion

扫一扫 
扫一扫 
扫一扫 
扫一扫
本文是一篇关于如何使用 Stable Diffusion 绘画的教程,包括软件介绍和案例带练。 在开始学之前,我想提前说一下,我所理解的 AI 绘画的本质,就是手替,人提出方案,AI 帮你完成具体的作画过程。 写这篇文章的初衷,网上的 Stable Diffusion 教程太多了,但是我真正去学的时候发现,没有找到一个对小白友好的,被各种复杂的参数、模型的专业词汇劝退。所以在我学了之后,想出一篇这样的教程,希望能帮助完全 0 基础的小白入门,即使完全没有代码能力和手绘能力的设计师也可以学得会的教程。 受限于篇幅,这篇只介绍最基本的操作,并且会带手把手带大家去做一个案例出来,让大家先把 AI 绘图的整个流程跑通。如果反馈还不错的话,下一篇补充一些进阶的操作。 另外我还想说的是,最近 AI 的工具越来越多,尤其是 AI 绘画,让大家变得越来越焦虑。我个人感觉要破解这种 AI 绘画带来的焦虑感,第一是要去了解它背后的原理,或者说它大概能做什么了解之后就相对没有那么焦虑了,第二是打不过就加入,让 AI 成为你的一个工具, 同时,即使通过 AI 可以抹平大家技法上的差距,但是审美上的差距是无法用 AI 抹平的,而这个可能会变成大家能力差距的重要来源。 AI工具大对比: AI绘画哪家强?Midjourney、文心一格等 6 大工具出图效果大比拼大家好,这里是和你们一起探索 AI 绘画的花生~3 月份以来 AI 绘画领域又有了不小的变化,Midjourney 更新了 V5 版本、Stable Diffusion 推出了 Clipdrop Reimagine;微软 Bing 也推出了 Image Create (图像生成)功能 阅读文章 >一、软件总览先给大家看一下我用 Stable Diffusion(以下称 SD)画出来的图,可以看到画面很细腻且用色也非常精致。
1. AI 绘画工具的选择 目前市面上最流行的两个绘图工具 Midjourney 和 Stable Diffusion 以及他们之间的区别,具体的研发背景等信息这里不做赘述,大家可以自行百度,只说一下对于设计师更关心的五个方面。
综上,从我的个人角度出发,SD 在工作中落地的潜力是要大于 MJ 的,这也是我选择学习和深入研究 SD 的原因。 2. 软件安装与打开 关于软件的安装,以及环境的部署,建议直接下载大佬们网上的整合包。这里推荐秋葉 aaaki 大佬的整合包,链接在这里: https://www.bilibili.com/video/BV17d4y1C73R 这里建议直接安装大佬的一键整合包,极大地降低了安装难度,对小白非常友好。 这里演示一下 Win 下如何安装,Mac 系统的同学也可以在网上找到对应的一键整合包,以及显卡不太好的同学也可以选择云端部署,这里给大家把链接贴出来。大家可以自行对照视频一步一步进行,基本没有什么难度。 Mac 芯片: https://www.bilibili.com/video/BV1Kh4y1W7Vg 云端部署: https://www.bilibili.com/video/BV1po4y1877P/ ①下载后是这两个文件,先双击运行一下右边的程序,安装一些必要的运行环境,然后解压左侧的压缩文件到你想要安装的位置。
②然后打开解压后的文件夹,找到“A 启动器”的 exe 文件,双击打开。
③打开后如图所示。
④然后点击“一键启动”,稍等片刻后会自动打开这个浏览器界面,就可以使用了(第一次打开时会有点久)
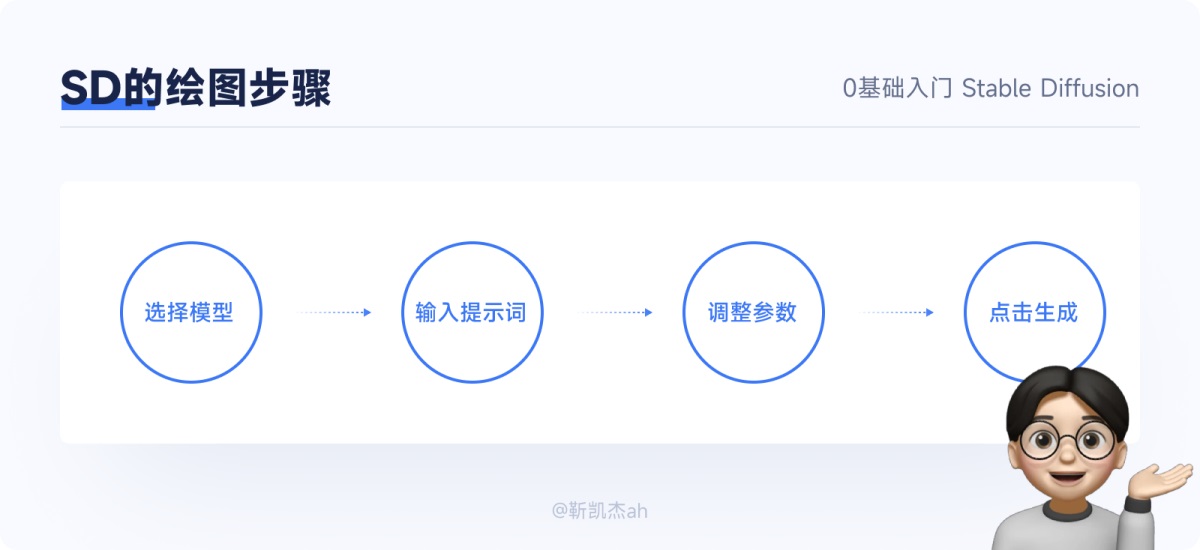
3. 流程和界面介绍 这里不去介绍 sd 的实现模型,只介绍一下我们所看到的呈现模型。可以理解为,就像是在做一道菜一样。首先准备原料(提示词和参数),然后按照菜谱(模型)来烹饪,让原料经历各种处理,最后就得到了可供品尝的美食(图像)。
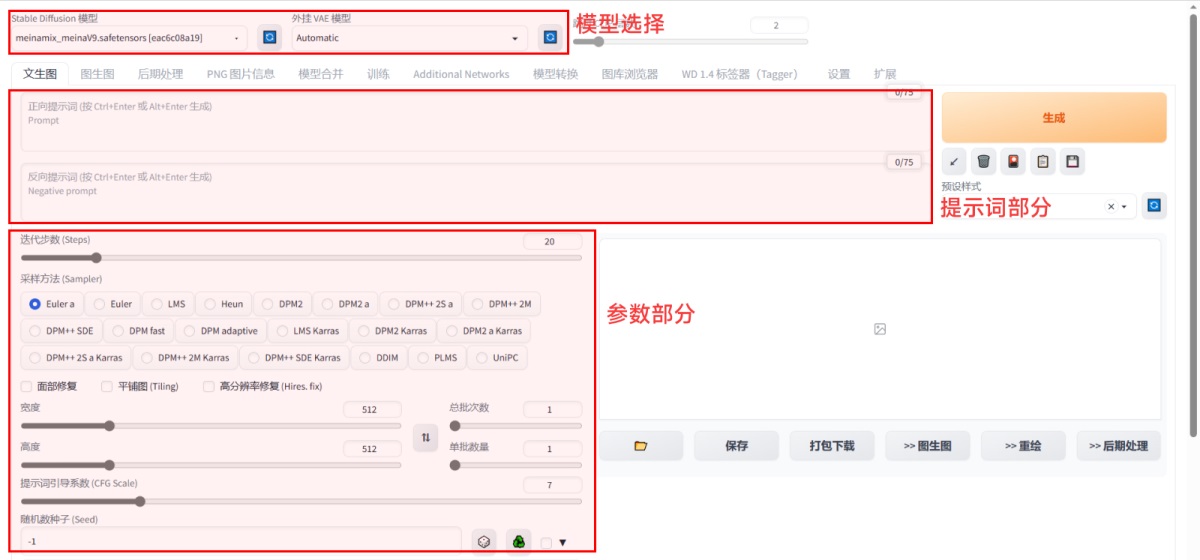
下面是关于软件的界面整体布局介绍,主要是由三大模块构成的,模型,提示词和参数,后面的章节会具体介绍一下每个模块。
二、模型1. 模型分类:SD 五大模型 如前面所说,模型就像是我们做菜时所用到的菜谱。每个模型都会有自己的风格,例如二次元画风,CG 画风等。 在 SD 中,目前共有 5 种模型。
对于这几种的区别和使用方式,可以理解为基础底模型就是烹饪中的“炒”,而辅助模型则是“爆炒,小炒”,最后美化模型则是更细节的方式,例如(盐爆,葱爆,油爆)等。 在 sd 中,基础底模型必须有且只能有一种,而后面的模型则没有限制性,可以没有,也可以是一种或多种。 2. 模型的下载和使用 我们在下模型时,就可以看到对应的类别:这里以最常用的基础底模型(checkpoint)和 lora 模型为例,介绍一下它们怎么使用。 ①首先我们要知道下载的模型是什么类别,如果是从上面两个网站下载的,那我们下载时就知道它的类别。如果是从其他渠道比如说别人的百度网盘链接,那这时,我们可以借助一个网站去获取模型类别: https://spell.novelai.dev/ ②然后,将模型文件放到对应的文件夹中。在这里,我们可以同时放一张模型的预览图,然后将图片名称改成和模型一样,这样后面我们调用模型时,就可以直接根据预览图来选择。另外在模型的命名上,我们可以用 “/” 来对模型进行分类整理。例如一个模型是二次元相关的,就可以命名为“二次元/XXX” 。 ③接下来就是模型的调用,对于基础底模型,我们可以直接在这里选择,如果没有找到,点一下右边的刷新按钮,稍等即可。VAE 模型则是在后面的下拉框中选择。这里可以一般采用默认的选项,然后如果出来的图发灰,再考虑使用 Vae 模型。对于其他模型,则需要先点一下这里的 icon,然后点一下想用的模型即可,这时上面的正向提示词输入框会出现对应的模型,想取消调用的话,再点一下模型或者直接在输入框中删掉即可。对于某一些模型,还需要在正向提示词输入框中输入特定的触发词,才可以让模型发挥效果。 三、提示词提示词也就是我们对 AI 的指令。
1. 基本规范 这里有两条基本规范需要注意一下:
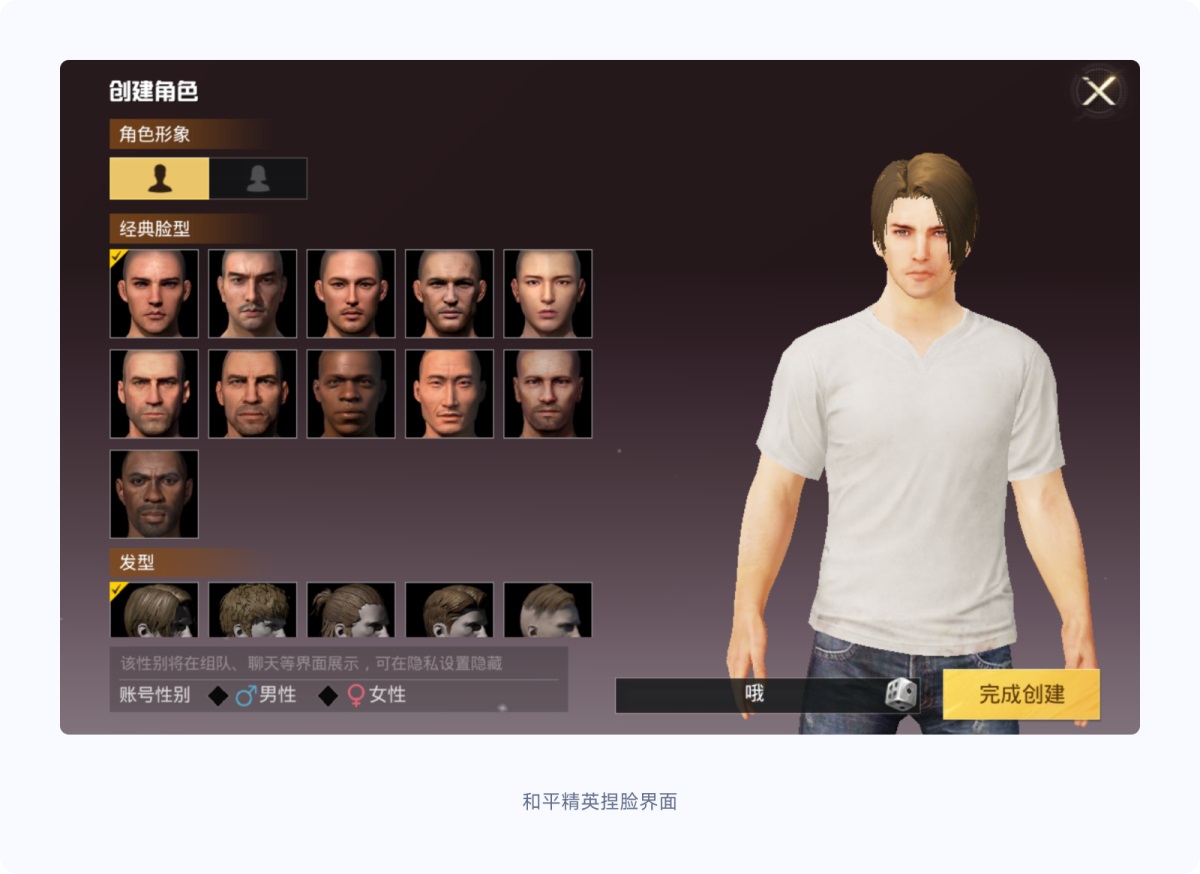
2. 书写提示词的整体思路 在给正向提示词的时候,我们一般通过分类描述的方式来给出。具体可以分为以下三类:整体描述、主体、场景。 ①整体描述 这里包括四个方面: 画质:高画质还是中等画质或者低画质,2k、或者 4k 等等 画风:CG、二次元、真人等 镜头:画面中人物的占比,半身像还是全身像 色调:冷色调或暖色调 ②主体 对于人物主体的描述包括三个方面:头部、服饰、姿势 ③头部 这里面包括的内容和我们玩游戏时捏脸的内容差不多,具体也就是包括这些内容:
④服饰 包括衣服,裤子、鞋以及其他更细节的比如袜子之类的 ⑤姿势 即人物的姿势,坐立跑等 ⑥场景 基础的场景描述一般包括三个内容:时间、地点、天气,进阶的表达可以加入一些细节,例如天空中的蝴蝶、花瓣等。 3. 提示词的语法 仅仅有了提示词还不够,我们还需要知道怎么把提示词组成 SD 可以识别的格式。 ①提示词的连接方式
②提示词的强化/弱化方式
③提示词的进阶玩法 这里推荐几个提示词的网站。在掌握了提示词的基本用法后,再去看这些网站就会更得心应手一些。
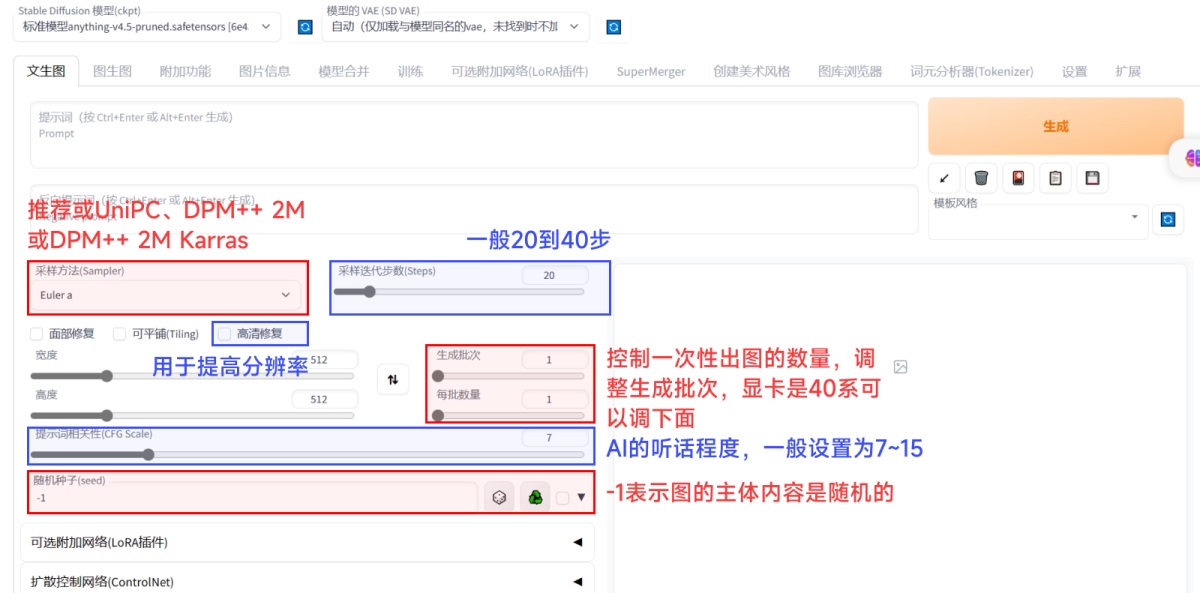
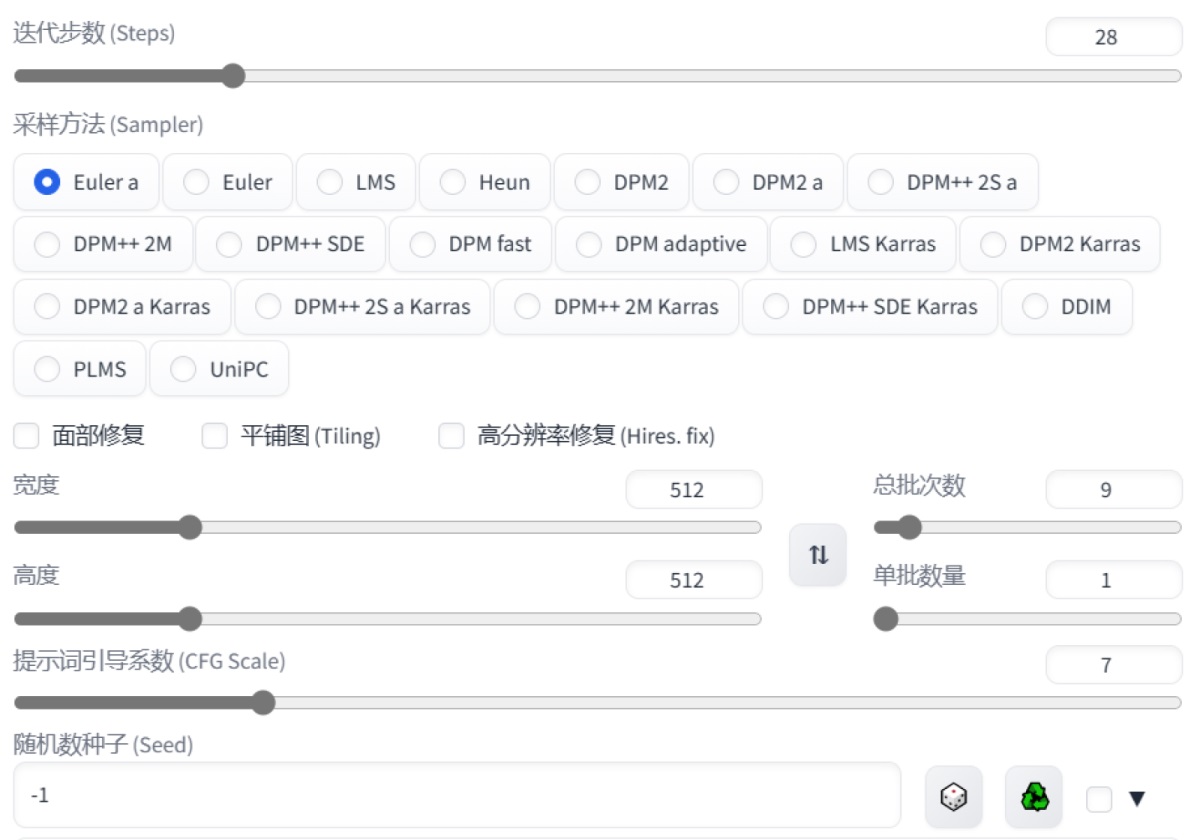
四、参数这里不想去说太多参数的官方解释,而且,在初期并不是所有的参数都需要了解,所以这里直接用通俗易懂的语言来给大家介绍一下需要用到的参数是什么,以及怎么用。 1. 采样方法 这里的原理比较复杂,笔者这里直接抛出结论: 一般情况下使用 DPM++ 2M 或 DPM++ 2M Karras 或 UniPC,想要一些变化,就用 Euler a、DPM++ SDE、DPM++ SDE Karras、DPM2 a Karras。 2. 迭代步数 这里指的是 sd 用多少步把你的描述画出来。这里先给出结论,一般 20 到 40 步就足够了。迭代步数每增加一步迭代,都会给 AI 更多的机会去比对提示和当前结果,并进行调整。更高的迭代步数需要更多的计算时间。但并不意味着步数越高,质量越好。 这里是相同提示词和参数,不同迭代步数时的表现。可以看到在这组参数下,步数在 32 左右表现是最好的,从 32 到 40 提升不大,到 48 时以及出现了一些畸形,到 64 时腿部已经完全畸形了。
3. 面部修复 根据个人喜好开关,这个对最终成像效果影响不大。 4. 平铺图 这个一般用不到。 5. 高分辨率修复 通俗来说,就是以重新绘制的方式对图像进行放大,并且在放大的同时补充一些细节。 打开后,这里会出现一些子参数。 放大算法:用默认值即可。 高分迭代步数:一般选在 10~20 即可。这里还是以这个图为例,可以看到在步数超过 20 后就开始出现了畸形。
重绘幅度:一般是 0.5~0.8 之间。幅度过小,效果不好,幅度过大时,和原图差异太大。
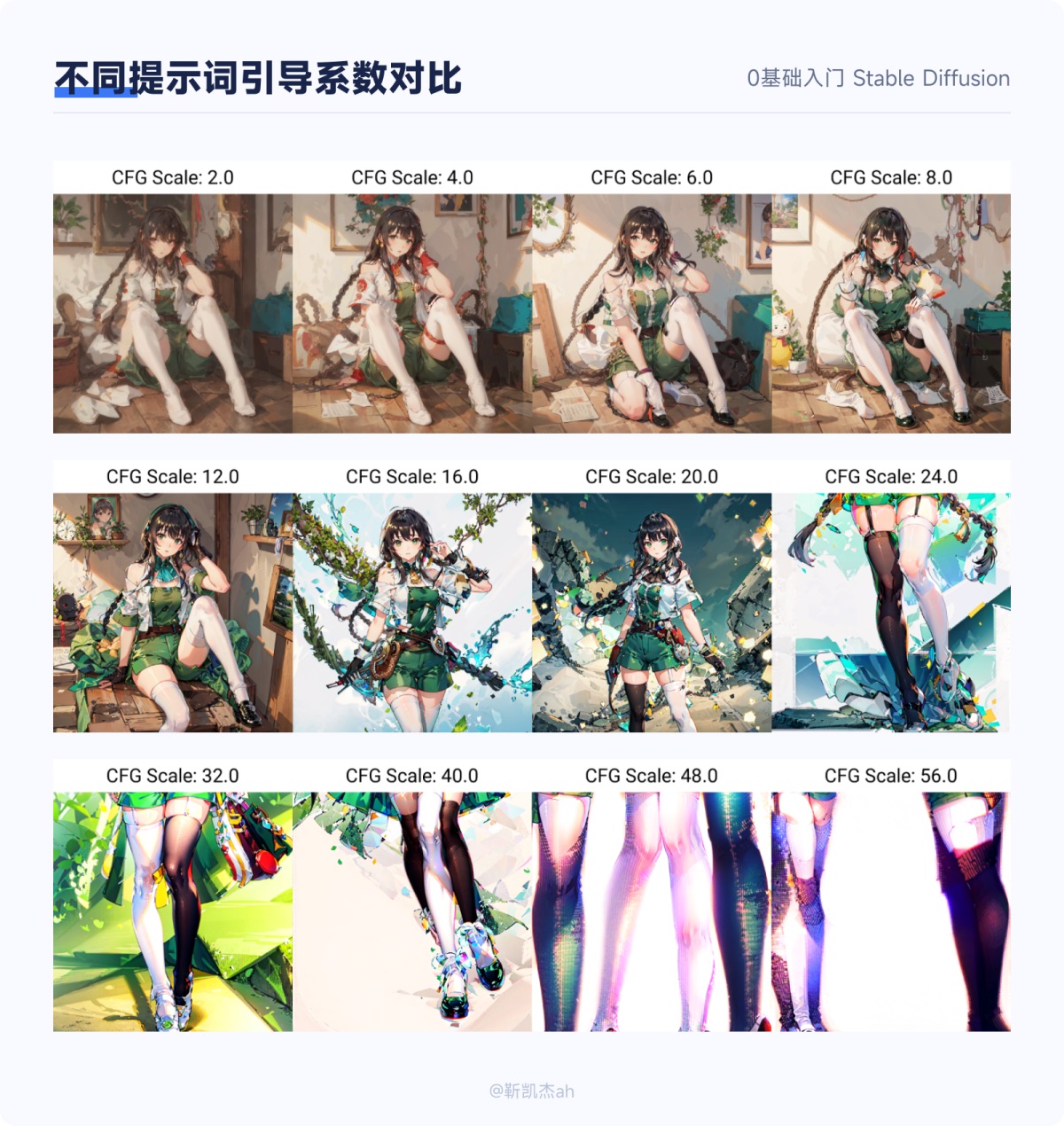
放大倍率:这个比较好理解,就是指最终的图原来图的分辨率的比值。例如,默认生成的图是 512_512,设定为 2 倍后,最终产出的图就是 1024_1024。 6. 总批次数和单批数量 这个是指一次性出图的数量。以搬砖为例,同样是搬 4 块砖,体力好的人可以一次搬 4 块,只搬一次,对应到 SD 中,就是总批次数是 1,单批数量为 4;而体力不好的人一次只能搬一块,需要搬 4 次,对应到 SD 中,就是总批次数是 4,单批数量为 1。一般而言,如果不是顶级显卡,我们都会保持单批数量为 1,去改变总批次数来增加一次性出图的数量。 7. 提示词引导系数 最终生成的画面和你的描述词的趋近程度,一般设置为 7~15 之间,太高也会出现问题。
8. 随机数种子 随机数种子就像在做一道菜时加入的特定调料,它可以影响整道菜的味道。在这个图像生成方法中,随机数种子就是一个特定的数值或代码,可以影响最终生成的图像的过程,就像特定的调料会影响整道菜的味道一样。不同的随机数种子会生成不同的图像,就像加入不同的调料会让同一道菜变成不同的味道。每个图都会有它对应的随机数种子,如果想还原这张图,或者绘制一张相似的图,必须保证这个值是相同的。随机数种子不变的情况下,即使模型发生了改变,最终生成图的大概结构和配色也会有一定相似性。就像是无论是以土豆还是以茄子作为食材,只要加入的都是甜辣酱,最终的味道是差不多的。我们可以在输入框中输入特定的值,以保证随机数种子固定,否则可以点一下旁边的骰子 icon,变成-1(-1 就指的是随机值)使得模型采用随机的值来生成图像。 9. 变异随机种子 在理解了随机种子之后,我们再去理解变异随机种子就更好理解了。变异随机种子相当于又加入了第二种特定调料。而后面的变异强度就指的是两种调料的占比,数值越大,越接近第二种。数值为 0 时,就指的是完全不用变异随机种子。一般是用于确定了图后,对图生成其他相似画面的图像。例如,在做 ip 时,通过加入变异随机种子,可以实现画面内容不变的情况下,生成带有些许差异的画,从中选择更优的。 我们来总结一下上面提到的重要参数。
五、案例演示这里以做这样一个盲盒 IP 为例,演示一下基础的文生图的流程,在了解了基础的概念后,其他的操作就相对简单了,大家可以自行去探索。 这里先说一下做这个图的整理思路。
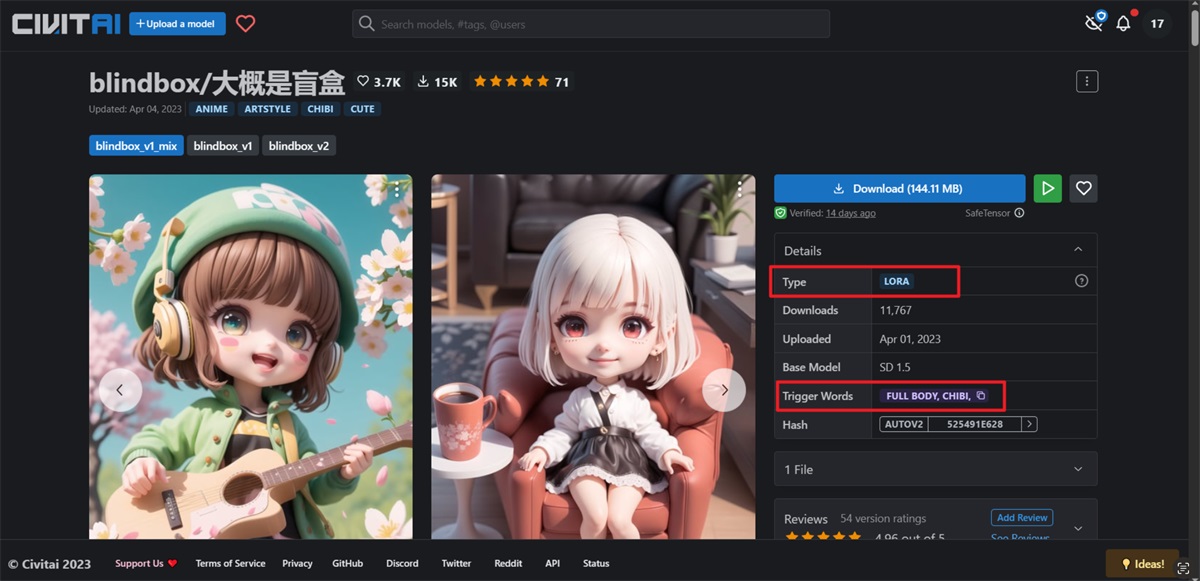
1. 模型下载与安装 首先我们去 C 站下载对应的模型,以这个盲盒模型为例: https://civitai.com/models/25995/blindbox
从右边模型信息,我们可以知道两个重要的信息,这个模型的种类是 LORA 模型,以及它的触发词是 full body, chibi。这里补充一下,所谓触发词指的就是,只有在将触发词加入到正向提示语的输入框中,才能触发这个 Lora 模型的效果。前面我们讲过,LORA 模型是一种辅助模型,需要配合基础底模型来使用。这里我们一般也推荐使用作者示例图中所使用的基础底模型。点开一个示例图,这里就是示例图的信息,包括基础底模型,提示语,以及参数。
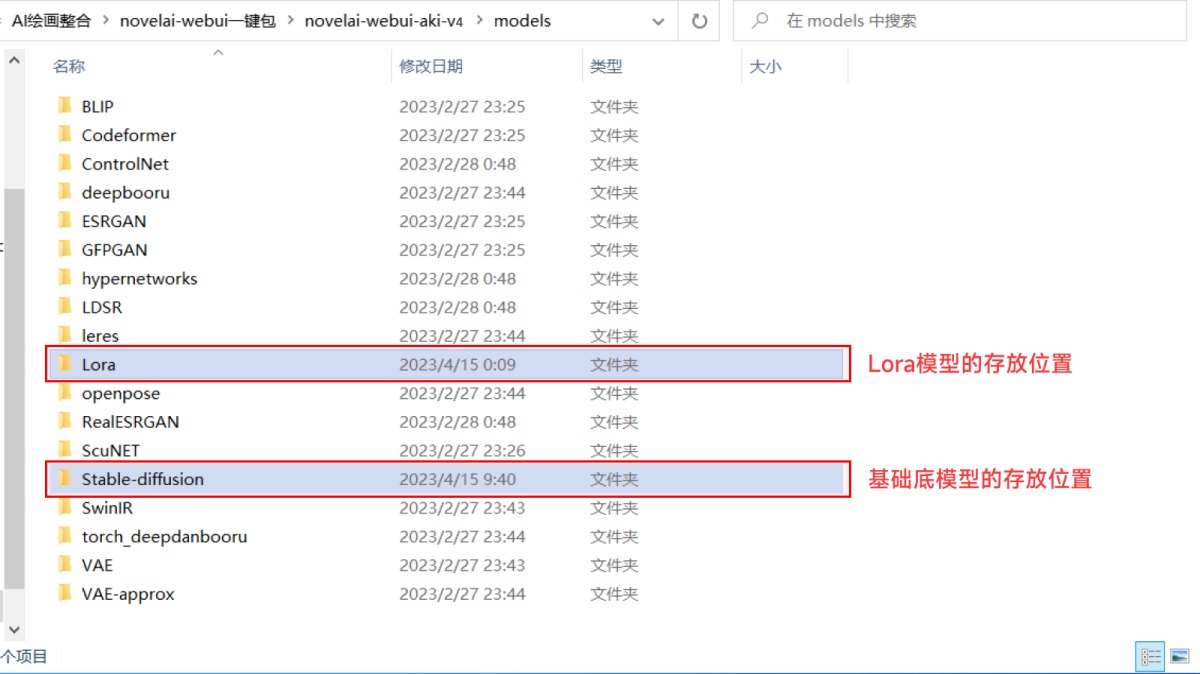
这里作者也贴心得给出了对应资源的下载链接: https://civitai.com/models/7371?modelVersionId=46846 我们将两个模型下载好后,分别放到对应的文件夹中。 基础底模型(checkpoint)的文件夹是“novelai-wvebui 一键包/novelai-webui-aki-v4/models/Stable-diffusion”,lora 模型的文件夹是“novelai-wvebui 一键包/novelai-webui-aki-v4/models/lora”
这里有两个小技巧:
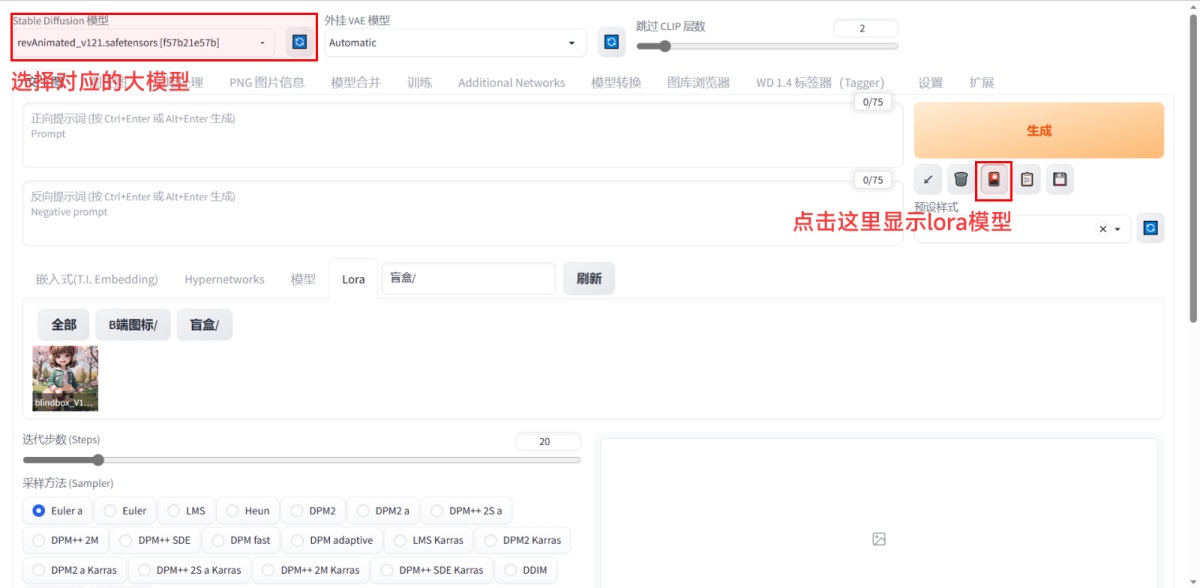
接下来,打开 web ui 界面,点击模型后的刷新按钮。并将左上角的第一个下拉框选择到对应的模型。其中,Lora 模型是默认隐藏的,需要点一下生成按钮下的第三个 icon 才会显示。
到这里,我们完成了模型的下载和基础底模型的调用。 2. 提示词的书写 对于新手,建议先从模仿开始,这里还是打开 C 站盲盒模型的页面,然后点击示例图,可以看到包括提示词在内的各种信息。
然后,我们把提示词复制下来,对于英文不好的小伙伴可以直接复制到翻译工具中。
接下来, 我们对这段关键词做一个简单的分析拆解: 整体描述:(杰作),(最好的质量),(超细节),(全身:1.2),(美丽的细节脸),(美丽的细节眼睛), 触发词:chibi 人物&场景:一个女孩,可爱,微笑,张开嘴,花,户外,弹吉他,音乐,贝雷帽,拿着吉他,夹克,腮红,树,衬衫,短发,樱花,绿色头饰,模糊,棕色头发,腮红贴纸,长袖,刘海,耳机,黑色头发,粉红色的花 我们可以直接复用整体描述的部分,将这部分复制到正向提示词输入框中。然后对后面的人物和场景部分重写。 这里用到我们之前介绍过的书写提示词中人物和场景的技巧:「眼睛,皮肤、头发、服饰、姿势、时间、地点」,按着这个顺序对画面描述如下:
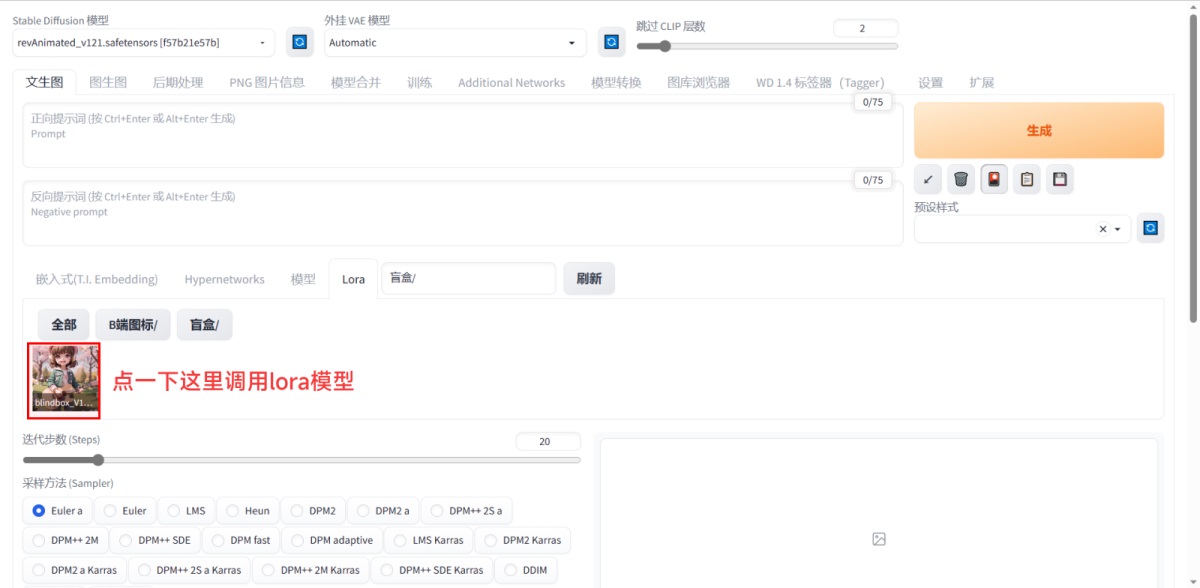
将英文复制到正向提示词中,接下来,我们点击一下盲盒的 Lora 模型,正向提示词部分就多了一句,这句话就表示对 lora 模型的调用。
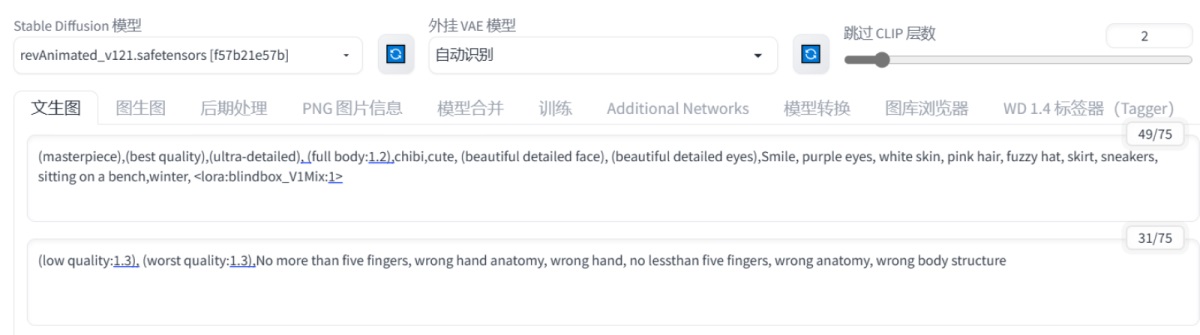
最后一步,将示例图的负向提示词也复制到我们的 SD 中,就得到了如图所示的最终的提示词。
3. 参数设置 参数设置这里,采样方式、采样迭代步数和提示词引导系数三个参数建议设置成和 Lora 模型示例图一致的参数,这样能比较好地发挥 Lora 模型的效果。然后,作为我们前期探索风格的阶段,总批次数和单批数量可以设置成 9 和 1,随机种子设置成-1,这样一次性会产出 9 张不同的图,方便我们选择。高分辨率修复在前期不建议打开,可以在图的内容确定后再打开,进行细节优化。
设置好参数后,点击生成。这里由于是随机的,所以生成的图像会和我这里不一样,但是整体的画面都是很相似的。
可以看到,整体图片的风格已经比较满意了,除了手的部分还有些问题。接下来,就可以选择一张最满意的,去补充和修复细节了,这里就以第 6 张图为例,大家可以选一张自己喜欢的。
我们接下来要做的是这三件事:
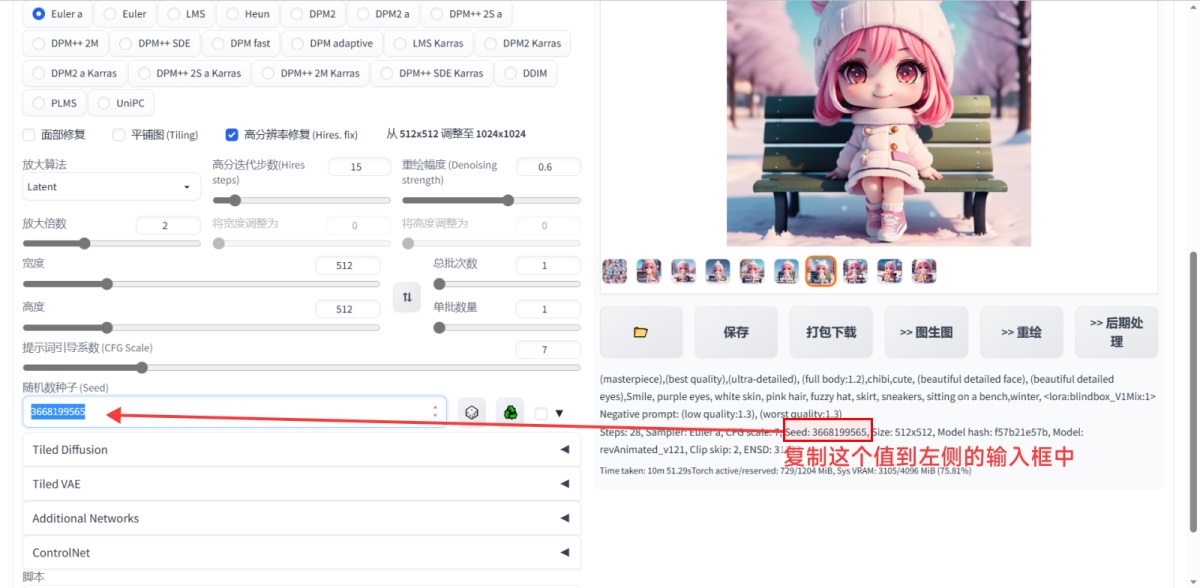
首先是第一步固定画面,前面我们讲过,每个图都会有它对应的随机种子,如果想还原这张图,或者绘制一张相似的图,必须保证这个值是相同的。所以,我们需要把找到这张图的 seed 值,填入参数栏中的随机数种子输入框中。
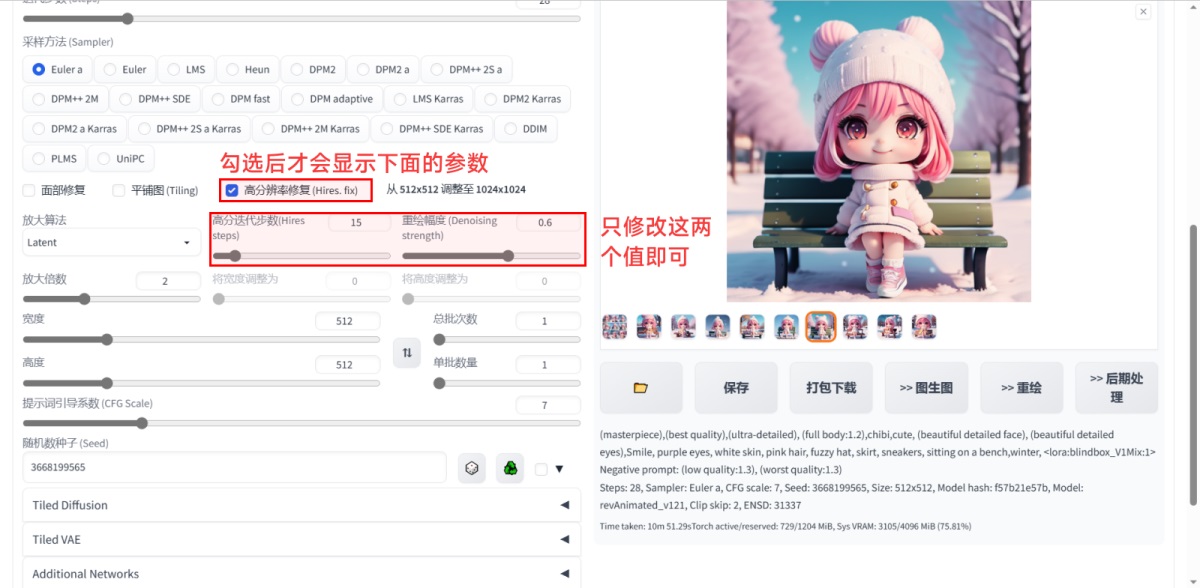
下一步是对画面进行细节补充,这一步我们会用到高分辨率修复的参数,先选中第 6 张图,然后根据前面的知识,把高清修复采样次数调整到 15,重绘幅度调整到 0.6。注意,这一步把总批次数和单批数量调整到 1,否则还是会一次性生成 9 张图,会需要较长的时间。
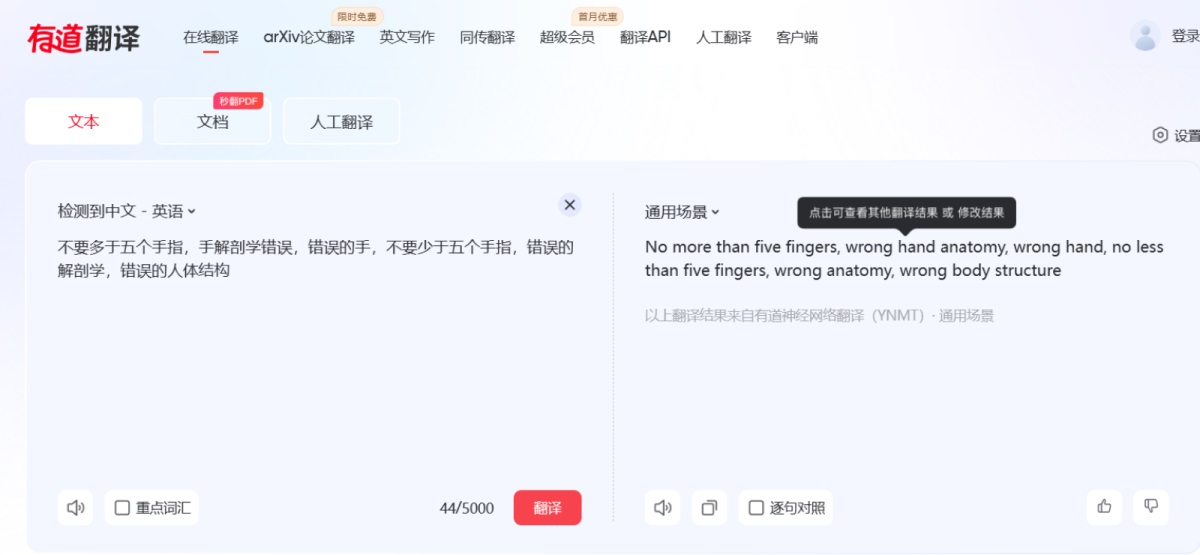
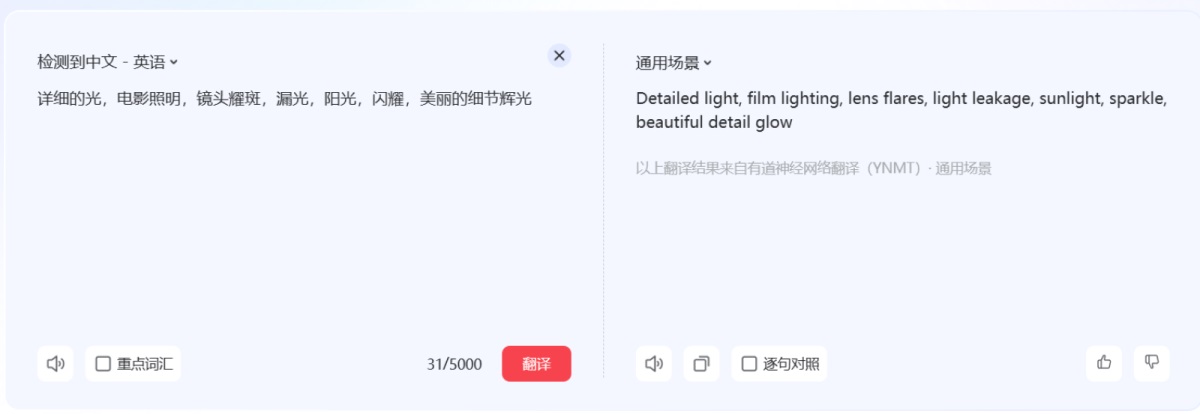
最后一步,我们去修复手的问题,这里我们采用补充反向提示词的方式来完成。这里依然用有道翻译:
将英文翻译填入反向提示词中后,我们点击生成,就可以得到这么一张效果还算不错的图了。
这只是一个简单的例子,里面用到的提示词并不多,我们可以继续加入提示词来丰富画面,提升细节,例如加入光效描述到正向提示词中。
生成的图像如下,可以看到又增加了一些光感,整体细节和品质又提升了一些。这里仅仅以此为范例,大家可以去增加自己想要的各种提示词来生成自己想要的图。
文章最后再给大家推荐 5 个我认为非常优质的模型:
50个保姆级咒语,带你彻底玩转二次元AI绘画神器Niji V5近期 Midjourney 推出了最新的 Niji Version 5,很多用户反馈,在插画和动漫制作方面,niji V5 要比 V4 的作图能力强很多倍。 阅读文章 >手机扫一扫,阅读下载更方便˃ʍ˂ |
















@版权声明
1、本网站文章、帖子等仅代表作者本人的观点,与本站立场无关。
2、转载或引用本网版权所有之内容须注明“转自(或引自)网”字样,并标明本网网址。
3、本站所有图片和资源来源于用户上传和网络,仅用作展示,如有侵权请联系站长!QQ: 13671295。





最新评论







