








AI辅助IP形象设计!用 Stable Zero123 生成任意角色的三视图

扫一扫 
扫一扫 
扫一扫 
扫一扫
大家好,这里是和你们一起探索 AI 绘画的花生~ 今天为大家推荐一种用 AI 辅助生成任意角色三视图的方法,用到的是 Stability AI 新出的 Stable Zero123 模型,并结合 Midjourney、Stable Diffusion WebUI、Ps 等工具完成。工作流搭建完成后,用来生成一些简单 IP 形象的三视图非常方便。 相关推荐: AIGC大厂实战!如何用 Stable Diffusion 制作超级符号海报?前言品牌符号宣传海报作为品牌运营很重要的曝光手段,随着 AI 技术的不断发展,已经逐渐替代传统设计方法,质量和效率的提升使它成为热门的超级符号延展设计方式,今天我们就来了解下这套设计方法论,解析利用 AI 生图制作超级符号海报的方式。 阅读文章 >一、根据图像生成多视角图Stable Zero123 是 Stability AI 在前段时间推出的一个新模型,可以根据一张图像生成高质量的 3D 模型,并且支持调整相机角度,也就我们可以根据一张图像生成多个不同视角的新图像。
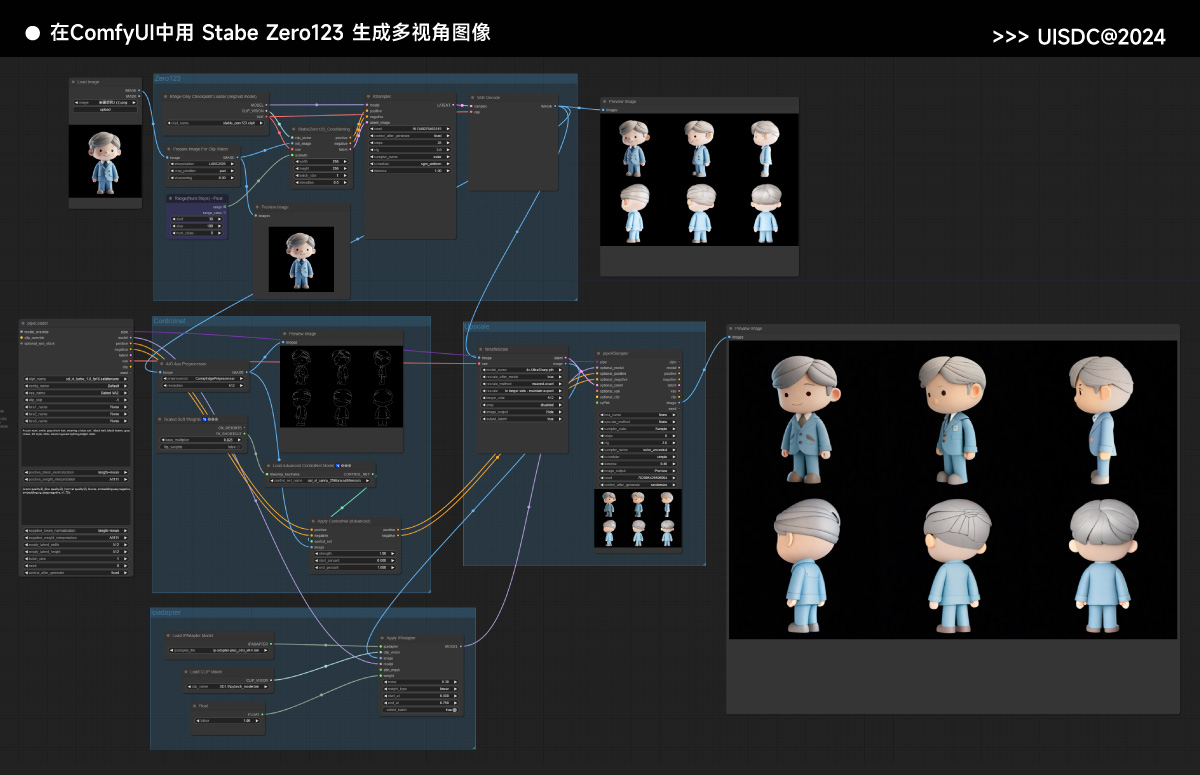
由于 Stable Zero123 是开源模型,所以很快就有人在 ComfyUI 中建立了用 Stable Zero123 生成多视角图像的工作流,下图就是根据一张正面图生成的 6 个视角的新图像(文末有文件资源)。
工作流的具体操作方法为: ①将工作流导入 ComfyUI,对于缺失的节点,可以直接在 Manager 中安装补全然后重启。 ②先在 Load Image 中上传一张 IP 角色图像,图像需要有干净的背景,并且主体和背景之间的反差要明显。 ③安装 Zero123 模型。首先我们需要下载官方的 stable_zero123.ckpt 文件,安装根目录的 Checkpoints 大模型文件夹中。然后在 Range (Num Steps)- Float 节点中设置开始角度、结束角度和总的生成张数。30 表示顺时针旋转 30°,180 表示顺时针旋转 180°,6 表示在 30°-180° 之间生成 6 张图像。 ④生成时可以多尝试调节 KSampler 节点中的 cfg 参数,推荐在 2-6 之间尝试,数值较低时,新图像的效果会比较稳定。 链接:https://huggingface.co/stabilityai/stable-zero123/tree/main(文末有资源包)
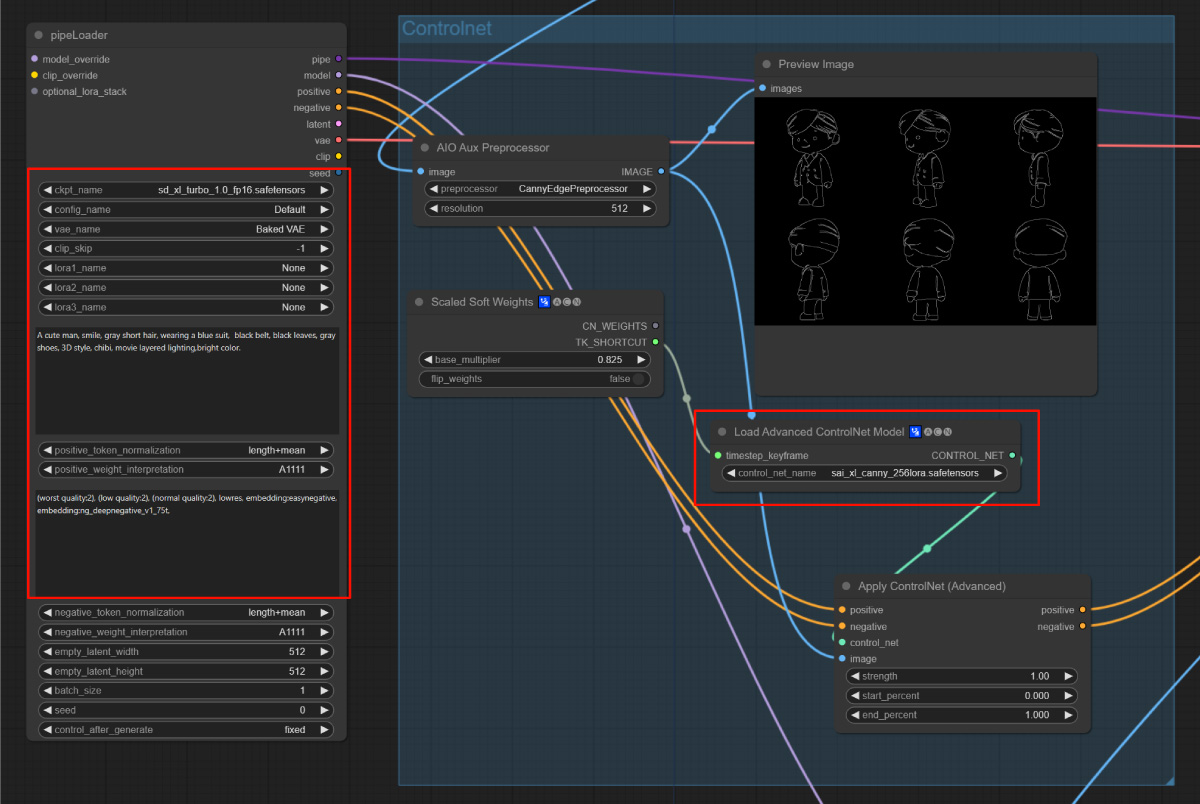
⑤然后在 PipeLoader 节点中设置新图像的生成参数,包括大模型、VAE、提示词等。我选择的是一个 SDXL 大模型,提示词描述了图像的内容 “A cute man, smile, gray short hair, wearing a blue suit, black belt, black leaves, gray shoes, 3D style, chibi, movie layered lighting,bright color”,反向提示词选常用的即可。 ⑥再设置 Controlnet 参数,这一步用于控制放大后图像的外轮廓。因为我的大模型是 SDXL 的,所以这里用的是 controlne t 模型是 sai_xl_canny_256lora.safttensors,预处理器是 CannyEdgePreprocessor。
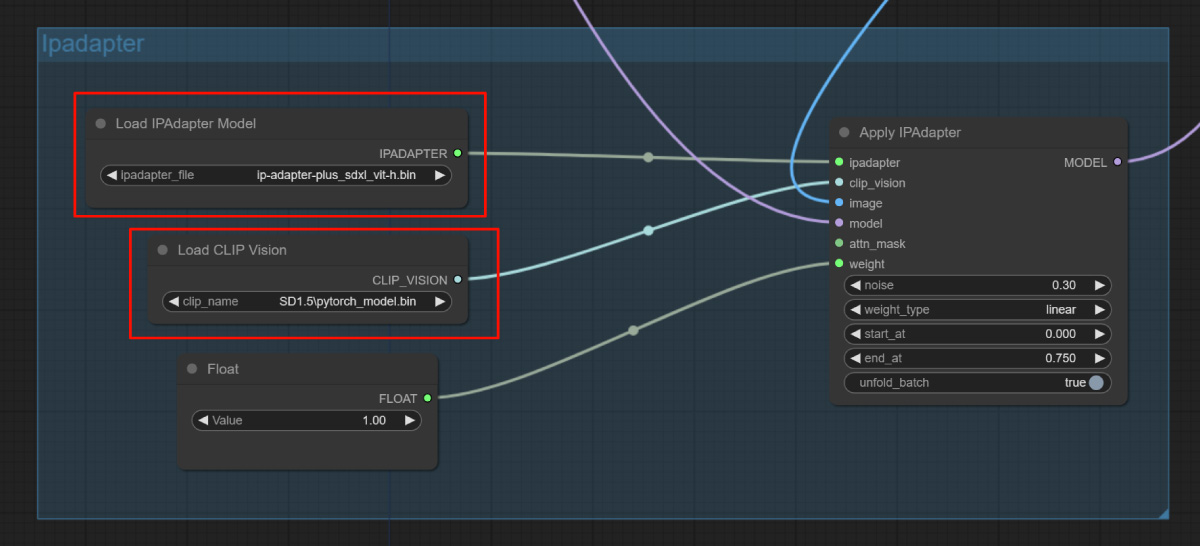
⑦继续设置 IPAdapter 参数,这一步可以让新生成的图像在风格上与原图保持一致,需要用到 ip-adapter-plus_sdxl_vit-h.bin 模型(文末有资源包),下载后安装到根目录的 custom_nodes\ComfyUI_IPAdapter_plus\models 和 custom_nodes\IPAdapter-ComfyUI\models 文件夹中。
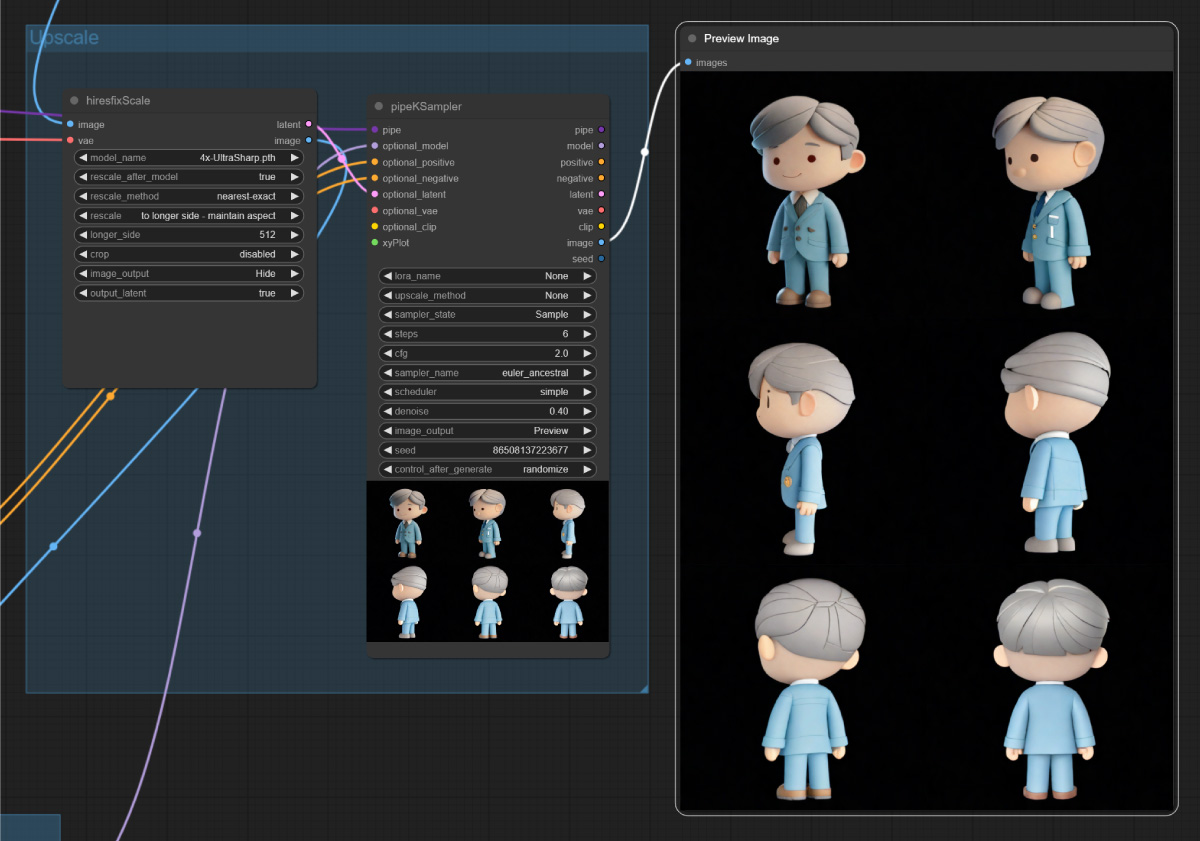
⑧最后设置 Upscale 放大参数,用到的是 4x-UltraSharp 模型。然后点击 Queue Prompt 模型,就能得到多张清晰的视角图了。
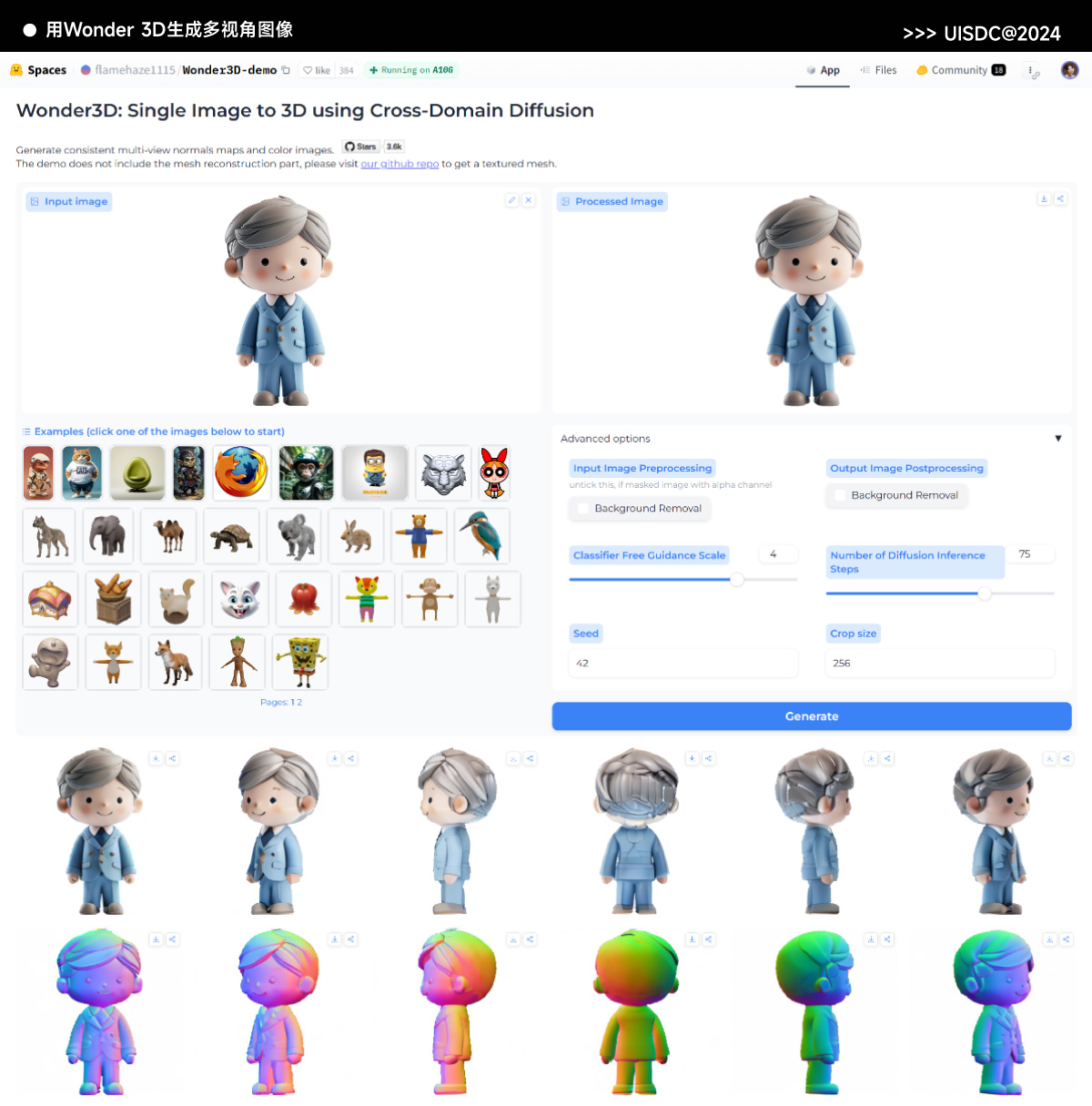
上面是在本地部署 Stable Zero123 模型生成多角度视图的方式,优点是可以灵活调整角度和生成效果。对于不会使用 ComfyUI 的小伙伴来说,我们也可以使用一些同类的在线工具生成多视角图像,下面为大家推荐 2 种: 1)Wonder3D 网址: https://huggingface.co/spaces/flamehaze1115/Wonder3D-demo Wonder3D 是一个根据单张图像生成 3D 形象的模型,支持 2D 和 3D 图像,并且效果相当稳定。它在 Huggingface 上有一个免费使用的 Demo,可以根据一张图像生成 6 个不同的视角以及法线 图。如果对生成效果不满意,可以点击 Adanced options 选项,修改 cfg 参数、Inference Steps 和种子值来优化图像效果。
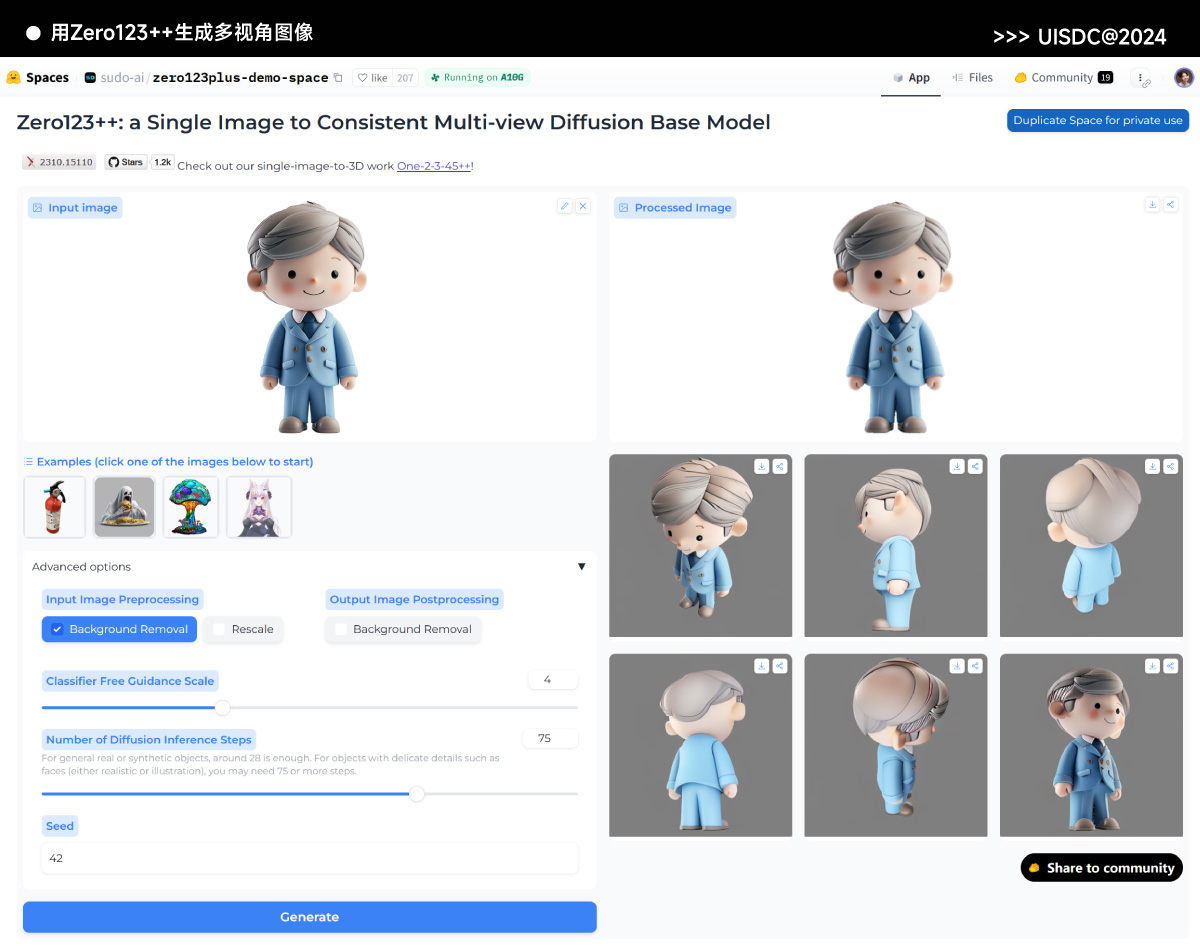
2)Zero123++ 网址: https://huggingface.co/spaces/sudo-ai/zero123plus-demo-space Zero123++ 也是一个可以根据单张图像生成多视角图像的模型,图像上传后点击 Generate,等待几分钟就能得到多个视角的图像,同样支持修改 cfg 参数、Inference Steps 和种子值来优化图像效果。由于它的视角非常多样,所以生成的图像也可以用来训练单个物体或人物的 Lora 模型。
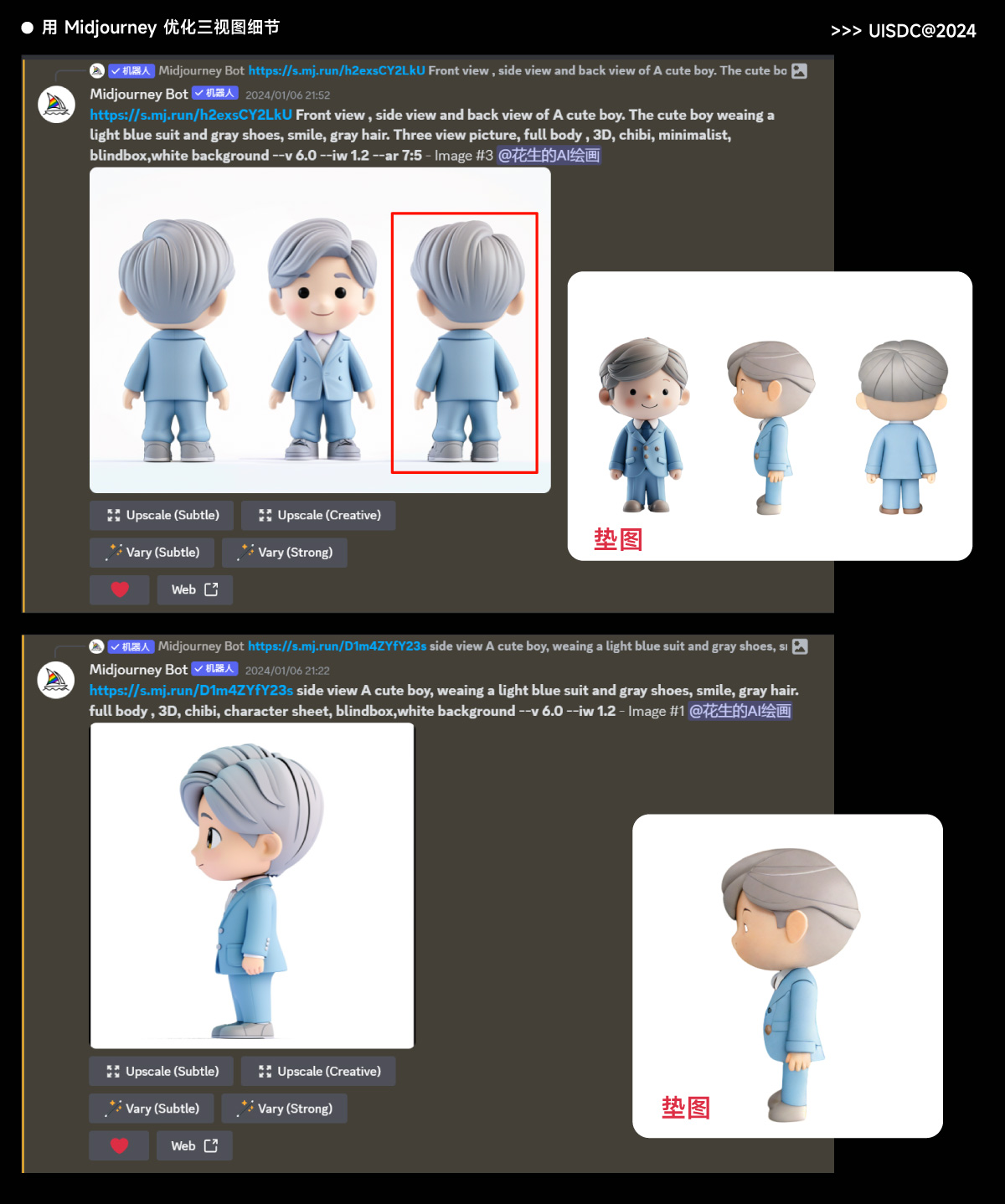
二、用 Midjourney 优化图像通过上一步我们可以得到一个角色的基础三视图,如果你觉得图像中的人物的细节还不够好,可以再用 Midjourney 的垫图功能优化图像,让细节更完整精致。如果觉得上一步的图已经很完整了, 那么也可以跳过这里的优化。
这一步需要注意的包括:
多次抽卡后,从中挑选出最合适的图像,组成新的三视图用于下一步的操作。中间我还用 Ps 处理了一下人物的眼睛,让画面的细节更一致。
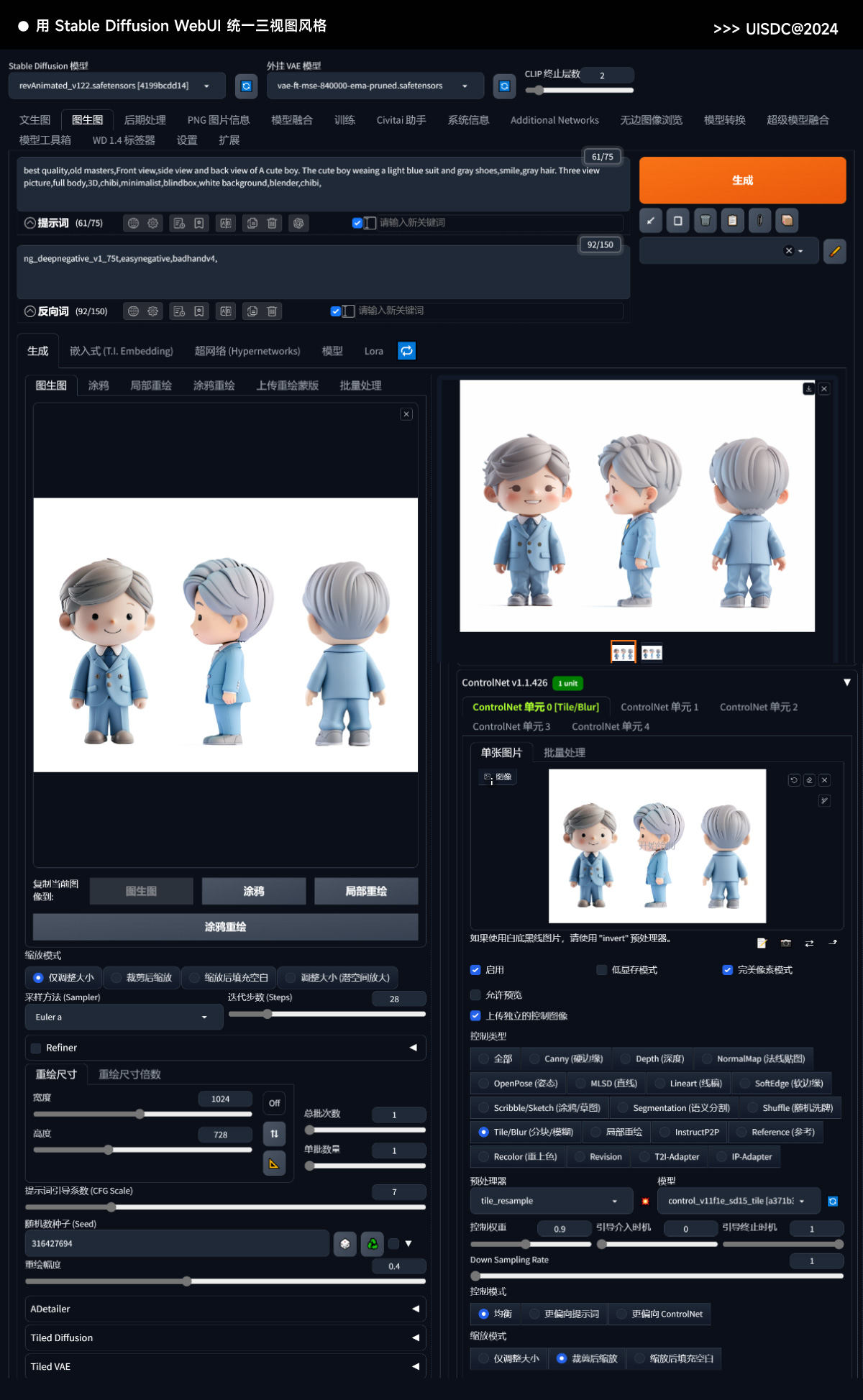
三、用 Stable Diffusion WebUI 统一三视图风格有了基础的三视图之后,我们可以用 Stable Diffusion WebUI 对其进行进一步加工,让三个视角在风格和细节上更统一,具体操作方式如下:
生成参数可以参考下面的设置(文末也有 Lightflow 工作流文件,可以直接导入 WebUI 中使用):
完成以上步骤后,我们就获得一套完整且细节对应的三视图了,后期还可以继续放入 Ps 中对色调、对比度等细节进行调节。这算是目前效果最好的生成任意角色三视图的方法,文章内提到的模型和工作流文件都在文末的网盘链接内,大家记得下载。如果你还不了解 Midjourney 和 Stable Diffusion 的用法,可以看看我最新制作的 《零基础 AI 绘画入门指南》,这是一门面向 AI 绘画零基础人群的系统课程,有全面细致的用法教学,并提供配套资源,能帮你快速掌握这两款目前最热门的 AI 绘画工具。
喜欢本期推荐的话记得点赞收藏支持一波,也可以分享给身边有需要的朋友。如果有关于文章或者 AI 绘画的疑问,可以扫描下方二维码加入 “优设 AI 绘画交流群” 和我直接交流,还可以和其他设计师 一起交流学习 AI 绘画知识~
推荐阅读: Stable Diffusion ComfyUI 基础教程(六):图片放大与细节修复往期回顾:补充:①在开始之前推荐一个插件,ComfyUI-Manager(ComfyUI 管理器),下载地址: https://github.com/ltdrdata/ComfyUI-Manager.git②安装方式除了可以使用我们第一节课上讲的 “git 拉取”外( 不 阅读文章 >15 组高质量春节主题 Midjourney 提示词!助你高效完成设计大家好,我是和你们一起探索 AI 绘画的花生~再过 1 个多月就是农历新年了,这段时间大家设计的物料应该都离不开这个主题。 阅读文章 >手机扫一扫,阅读下载更方便˃ʍ˂ |






@版权声明
1、本网站文章、帖子等仅代表作者本人的观点,与本站立场无关。
2、转载或引用本网版权所有之内容须注明“转自(或引自)网”字样,并标明本网网址。
3、本站所有图片和资源来源于用户上传和网络,仅用作展示,如有侵权请联系站长!QQ: 13671295。





最新评论







