





如何找到你的细分目标用户?试试这个决策树!

扫一扫 
扫一扫 
扫一扫 
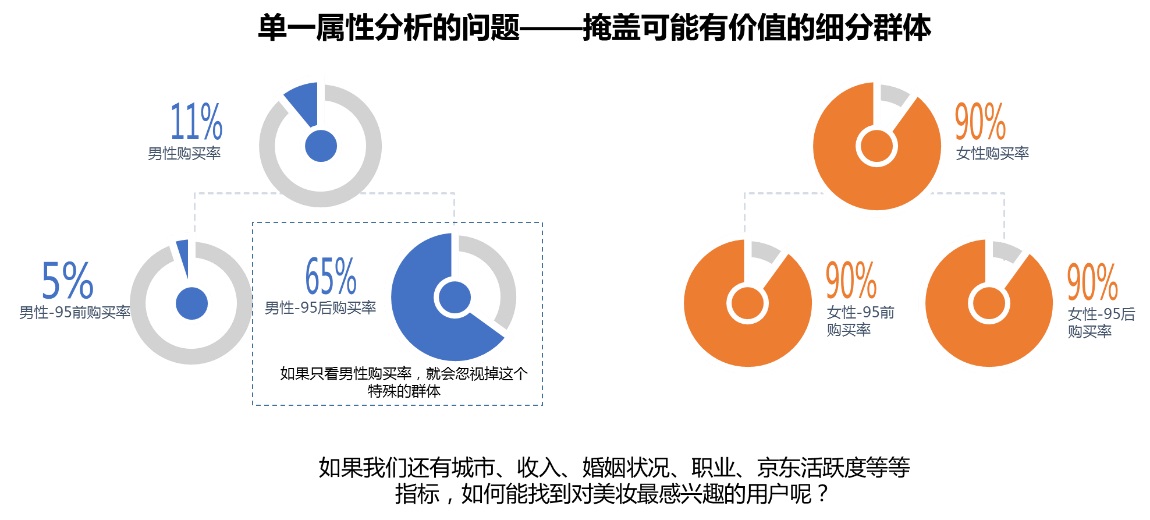
扫一扫 我们最常用的细分用户方式是聚类分析。但是如果你针对某一个关键指标,找到在这个指标上差异最大的细分人群,可以试试用决策树来细分用户。 在近期的项目中,业务方提到了一个问题:因为内容的曝光量少,没有很好的基础数据作为推荐算法输入,希望通过调研指导内容投放的冷启动,知道要给哪些特征的用户投放哪些内容。 针对这个问题如果只是单单分析一个特征的结果,可能会把一些重要的属性组合淹没在了特定人群中。比如举一个不真实的例子,如果对用户购买美妆产品行为进行分析,只看男女数据分析,我们会发现相比于女性,男性几乎是不购买美妆产品的。但是如果针对性别进一步拆分年龄,我们会发现 95 后的男性也有较高的美妆购买行为,如果只看性别分析这个对美妆有高需求的特殊男性人群就会被忽视。
但是可以分析的用户属性很多,如果手动组合分析就非常的不方便。这个时候就可以用决策树分析来解决这个问题。 什么是决策树?决策树是一种细分用户的方式。不同于聚类细分用户,决策树细分用户中有一个目标变量的概念。决策树的细分目的就是通过逐层划分不同解释变量值获得多属性组合细分人群,使得细分人群在目标变量上表现区隔度尽可能的大。 解释变量就是用户特征,比如人口学、消费特征、用户行为数据等。 目标变量则是我们调研中关心的核心指标。它有两种类型,分别服务于两种不同目的。
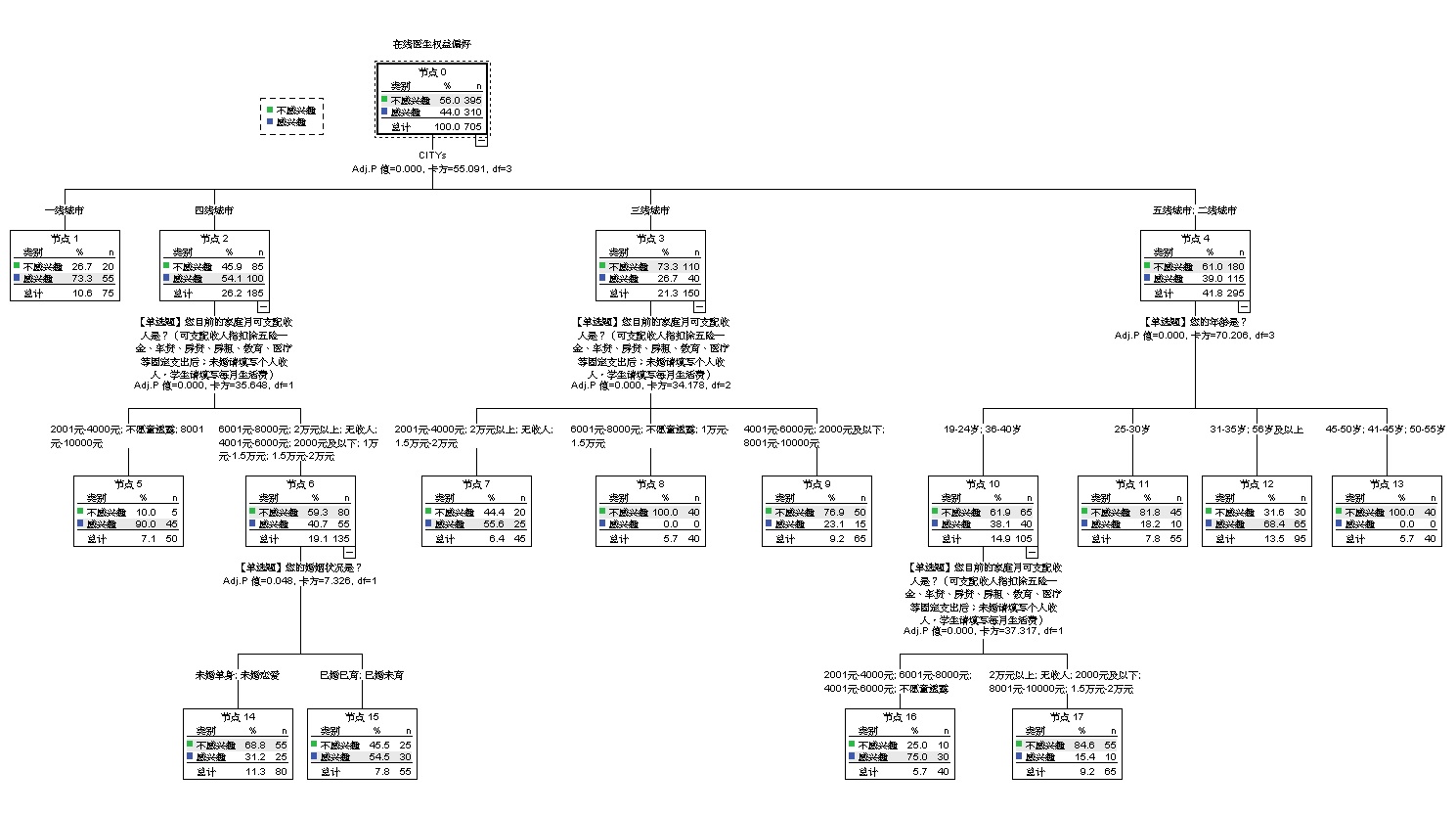
决策树的原理是什么?决策树算法中 CHAID 和 exhaustive CHAID 在结果的简洁度和区隔度上表现都更好是最常用的算法。而 exhaustive CHAID 与 CHAID 区别在于计算了更多的组合情况,可能获得更好的分割,但本质上两者计算方式是统一的。因此本次就以 CHAID 为例进行具体介绍。 CHAID 算法又称卡方自动交互检测法。顾名思义,CHAID 就是自动对解释变量和目标变量进行交叉分析并进行卡方检验,通过比较卡方检验显著性程度来寻找最佳细分维度。然后在此基础上继续细分直到卡方不再显著或达到数生成的条件限制。最终输出的树如下图 1。 输出的决策树结果向我们传达了两个重要的信息:
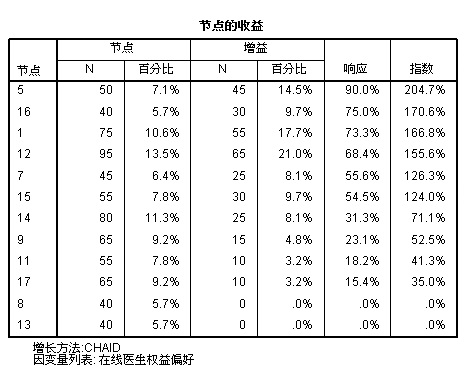
△ 图 1 决策树结果示意 有的时候决策树会过于庞大复杂,可以通过设置树的层级数、父节点、子节点最小样本数来修剪决策树:如果决策树达到树最大层级限制则不往下细分;如果节点样本达不到父节点数量要求则不往下继续分割;如果节点样本数达不到单个子节点的数量要求即与其它节点合并。 但是如果从决策树图中找哪些最终分组是对目标变量更感兴趣的比较费劲。所以决策树除了输出决策树图之外还可以输出目标类别收益表(比如内容偏好中将有偏好设为目标类别,示意见图 2),收益表包含 4 个数:
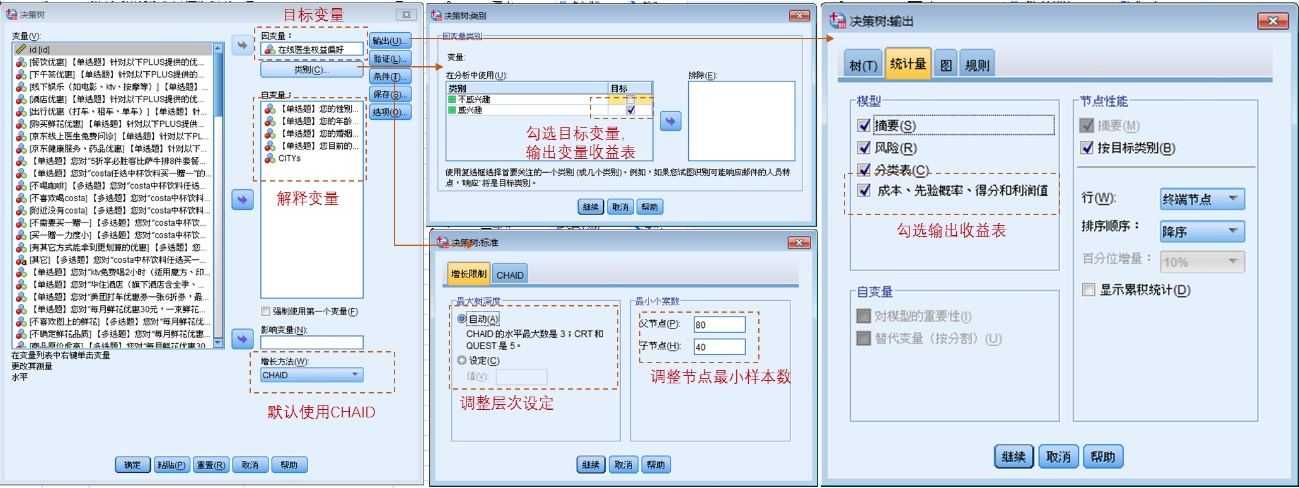
△ 图 2 收益表示意 收益表将对目标类别偏好度从低到高进行排列,所以能很快找到哪些最终节点分组对目标类别偏好度高。比如上图就显示节点 5 是对目标变量最感兴趣的人群。同时因为收益表还包含了节点百分比,所以可以知道这些分组在整体市场中的大小,用于判断可以将哪些分组包含进来扩大目标人群范围。比如上图中虽然节点 5 是目标变量最感兴趣的群体,但人数较少,在整体市场中只占到 7.1%。所以我们可以将节点 5、16、1、12 都作为目标群体,将市场覆盖率提高到 37%。 SPSS 中如何操作?1. 描述目的下如何操作
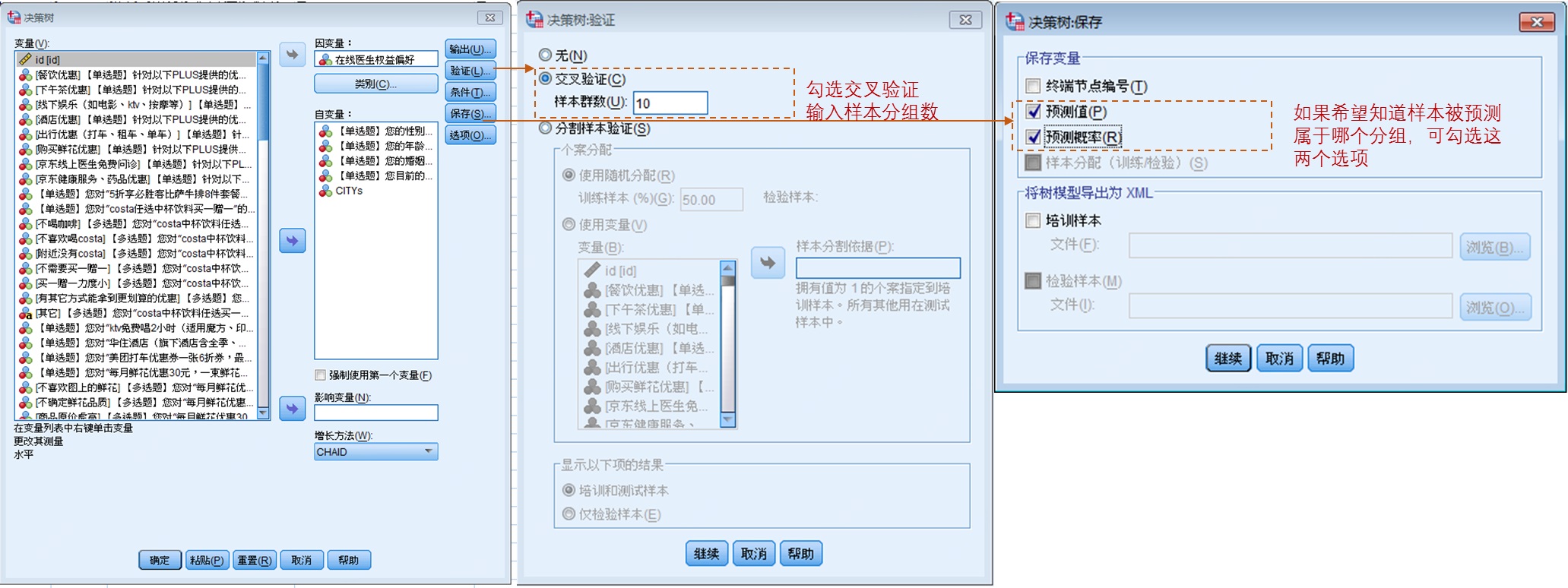
△ 图 3 描述目的决策树面板操作说明 2. 预测目的下如何操作 如果是预测目的,前期计算设定操作与描述目的一致,但是还有模型风险估计和预测
△ 图 4 预测目的下验证和保存预测变量操作 决策树的应用与局限如果分析的目的就是希望能找到在目标指标上尽量差异明显的细分人群,决策树是一种不错的方式。如果是以聚类的方式细分,我们可以将目标指标作为其中一个细分输入变量,但是因为聚类是为了让用户在空间的距离尽可能远,目标指标可能并不是最重要的影响因素,所以最终的结果可能目标指标上用户区分并不明显。而决策树的目的就是尽量在目标变量上拉开差距,所以细分结果上差异会更加明显。所以决策树经常被运用在市场产品、品牌来定位最核心的目标人群特征上。特别适合一开始业务方提出来的业务问题:特定内容应该给哪些用户投放更加合适。 但是决策树也有其局限和问题。
超详细!从0到1构建用户画像的流程与方法总结用户画像作为一种设计工具,可以很好地帮助设计师跳出“为自己设计”的惯性思维,聚焦目标用户,发现核心价值,赋能产品。 阅读文章 >欢迎关注「JellyDesign」的小程序:
手机扫一扫,阅读下载更方便˃ʍ˂ |

@版权声明
1、本网站文章、帖子等仅代表作者本人的观点,与本站立场无关。
2、转载或引用本网版权所有之内容须注明“转自(或引自)网”字样,并标明本网网址。
3、本站所有图片和资源来源于用户上传和网络,仅用作展示,如有侵权请联系站长!QQ: 13671295。





最新评论







