





Apple 出品!如何做好机器学习时代的产品体验设计:输入的设计 ...

扫一扫 
扫一扫 
扫一扫 
扫一扫 了解过界面输出的一系列设计要素与原则,接下来我们要探讨关于「输入」的设计。 往期回顾: Apple 出品!如何做好机器学习时代的产品体验设计:基本原理篇WWDC 19,Session 803,机器学习与体验设计相关话题,包括基本原理、设计要素、数据、指标、界面设计原则。 阅读文章 >Apple 出品!如何做好机器学习时代的产品体验设计:数据与指标今天是「机器学习」的第二篇,进入「模型」层面的讨论,内容相比于之前一篇「基本原理与设计要素」来说抽象了很多。 阅读文章 >Apple 出品!如何做好机器学习时代的产品体验设计:输出的设计聊过了机器学习的基本原理及模型层面的设计要素,即「数据」和「指标」,接下来我们将探讨界面层面的设计。 阅读文章 >人们会与界面输出进行互动,期间系统所接收到的反馈信息即为「输入」。我们可以有意识地通过这些反馈来优化模型并提升功能体验。 我们将要探讨四种类型的输入:
校准设置通过校准设置,系统可以获取到用于开启功能的基本信息,譬如生物识别或环境信息等等。
我们以 HomeCourt 为例。这款 app 可以辅助人们提升投篮水平。它通过机器学习来分析摄像头捕捉到的图像,进而为你提供一系列相关的统计数据,例如命中率等等。
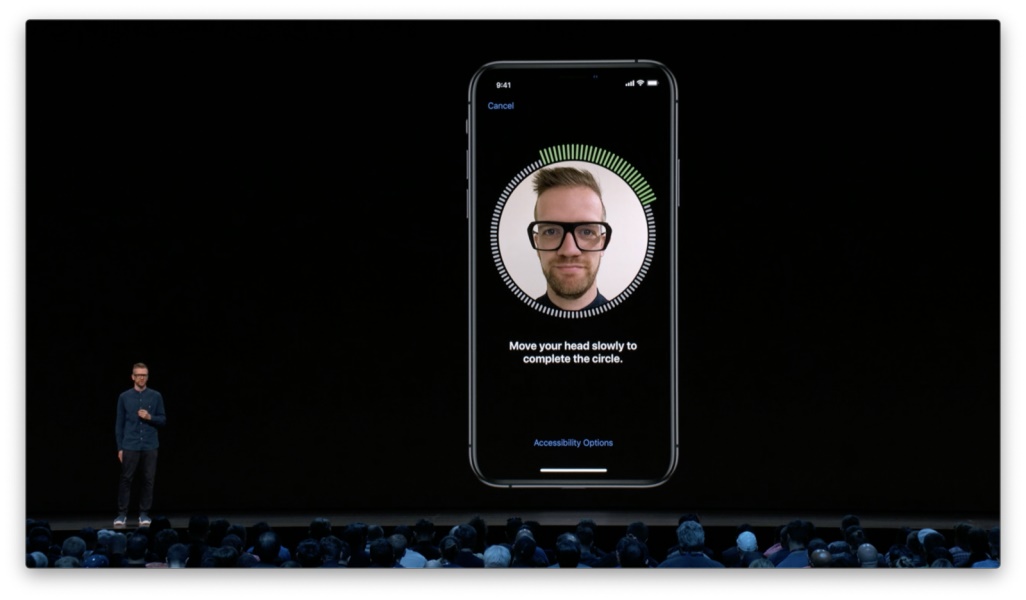
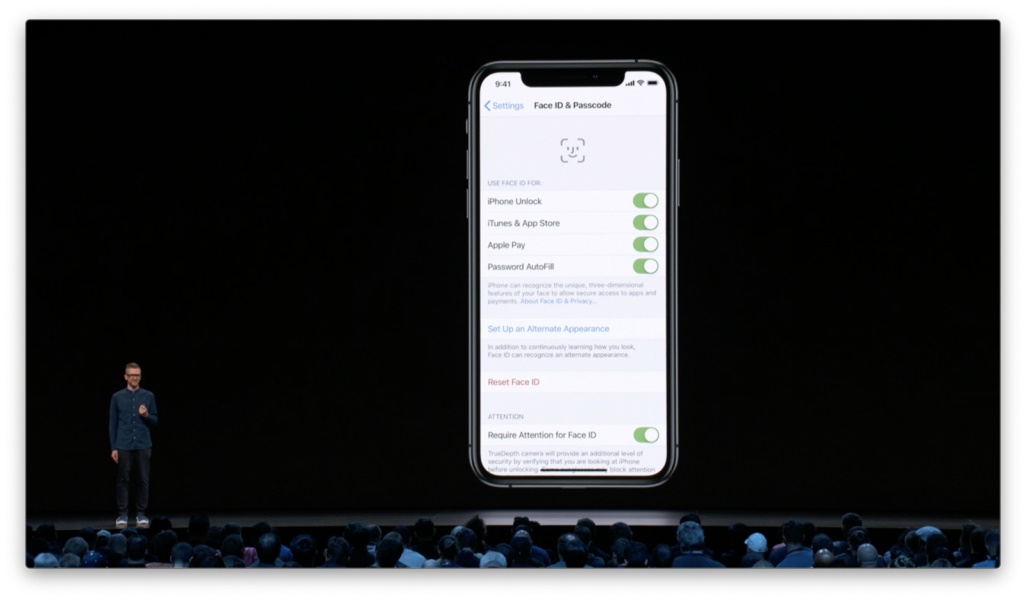
为了实现这些功能,app 首先需要进行校准设置,从而正确地识别到人、篮筐和球场。其实现方式非常简单易行,你只需要将前置摄像头对准篮筐的方向,app 即可自动标定位置。 接下来,它会提示你投一次篮,然后所有的校准工作就完成了。 这里的体验亮点在于整个校准过程的简单与自然。你不需要手动画线帮助系统进行识别,不需要确认识别结果是否正确,不需要在不同的位置反复投篮来提升识别率。 设计原则:确保校准过程的简单快捷,仅让用户提供最为必要的信息。 再来看 Face ID。其校准设置只需要通过两次扫描来收集最基本的信息;接下来无论人们戴上眼镜或是改变发型,都无需再次校准。
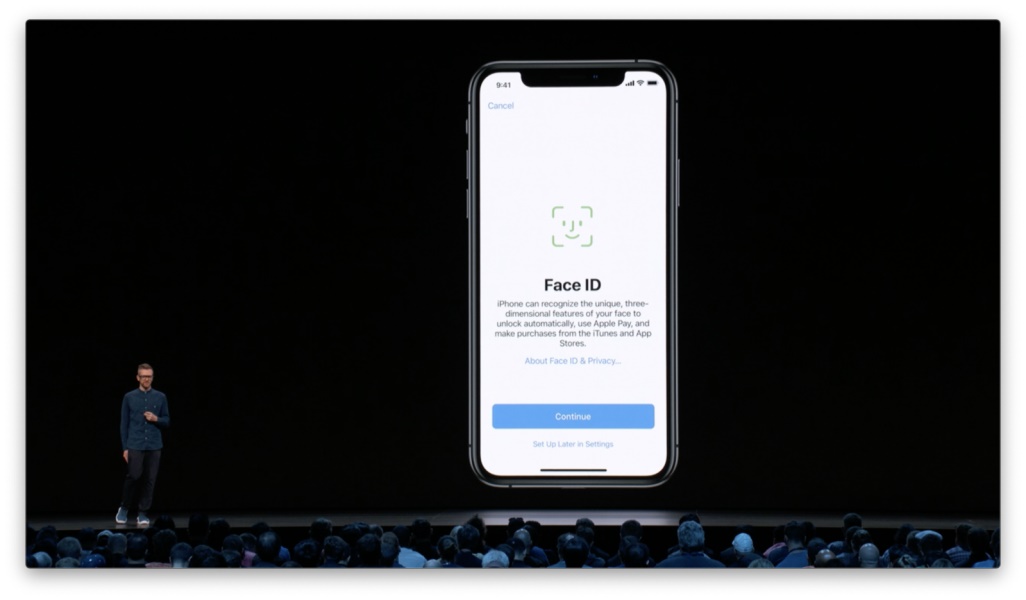
设计原则:尽可能通过技术手段避免在使用过程中进行多次校准设置。 在设置 Face ID 的过程中,我们也会进行持续的提示和引导。首先,我们会清楚地告诉人们为什么需要扫描面部,让人们知道 Face ID 的工作机制及便捷之处。
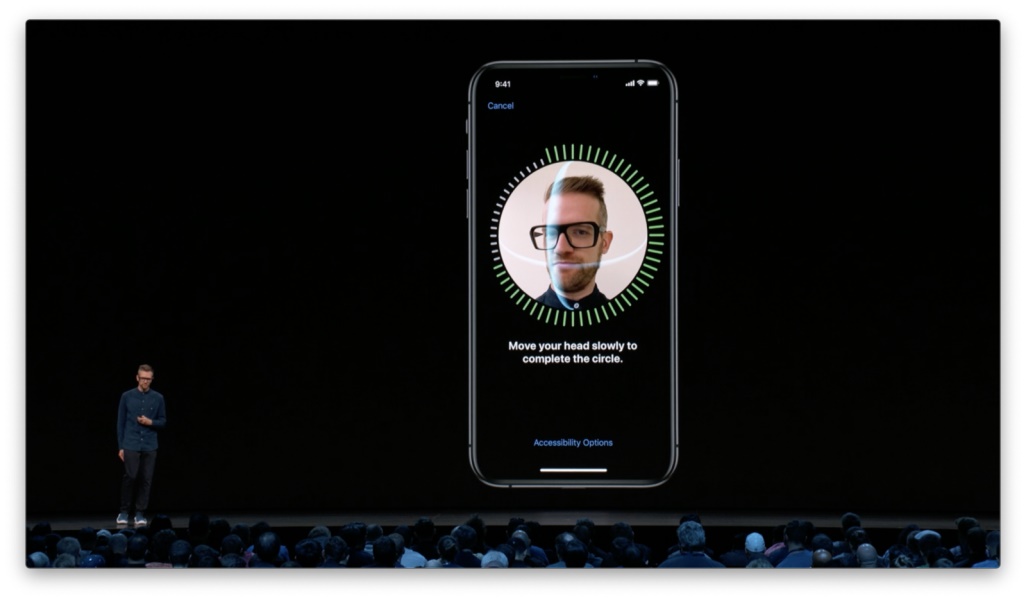
在整个过程中,我们会以可视化的方式让人们始终对进度保持感知。
如果扫描停滞了,我们会提供必要的指引,帮助人们进入正确的操作状态。
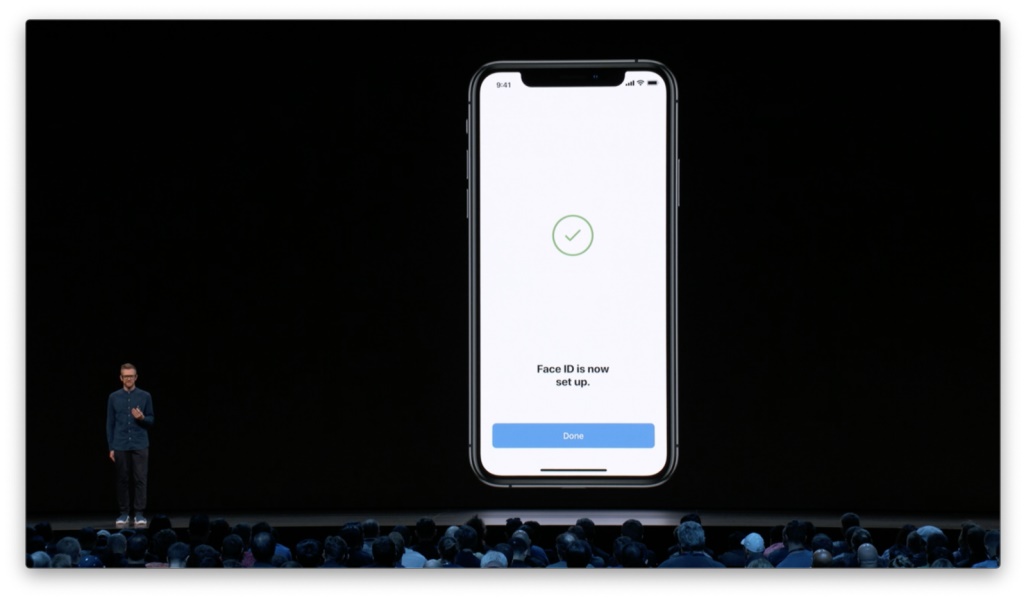
最后,我们会明确地反馈成功结果。
设计原则:在校准设置的过程中,要始终为人们提供介绍、指引、状态反馈与确认。 当然,Face ID 所收集的信息对于人们来说非常敏感。为了尊重人们的隐私,我们还会在「设置」当中提供修改或删除相关信息的方式。
设计原则:为人们提供更新信息的方式。 正如前面所说,完成初始的校准设置后,无论人们改变发型,还是戴上眼镜、帽子、围巾,甚至是随着年龄增长而发生相貌的变化,Face ID 都可以持续运行,而无需多次设置。这对于我们来说其实是非常大的挑战。 人们自然不会愿意被反复要求进行校准设置。Face ID 所采用的策略,是在人们每一次使用 Face ID 时潜移默化地获取和更新面部信息。这就是我们接下来要聊的第二类输入类型。 隐性反馈隐性反馈会在人们使用功能的过程中获取相关信息,用以对功能进行优化和更新。
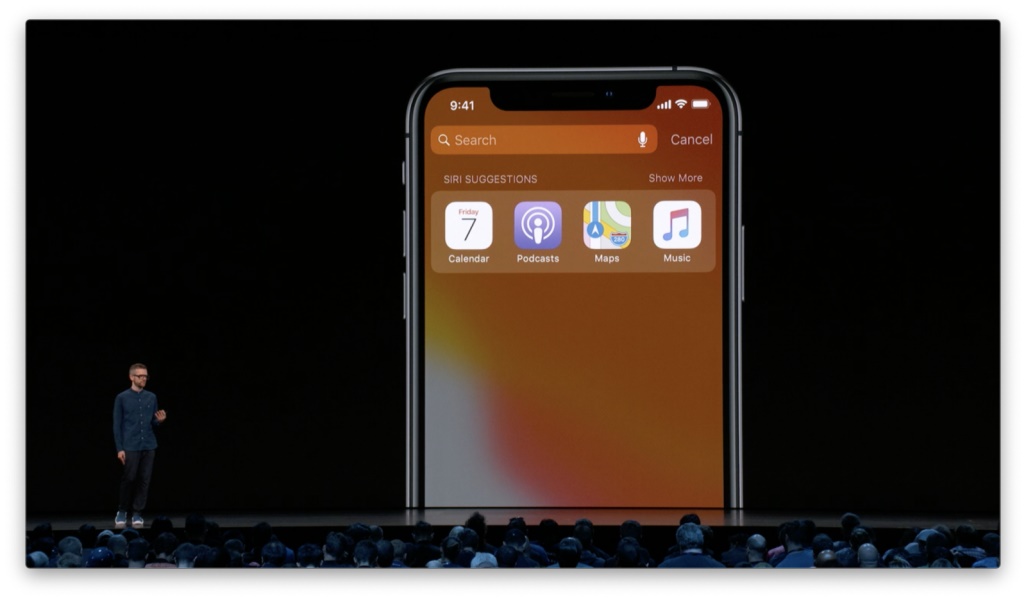
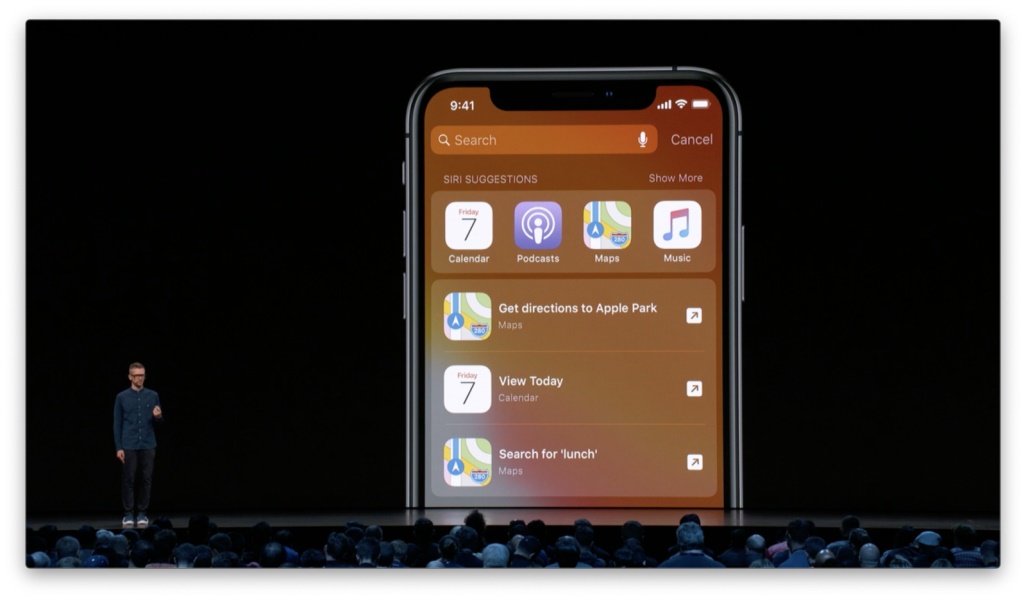
隐性反馈最常用于功能的个性化处理。譬如 Siri 会根据人们使用设备的习惯对搜索状态进行定制。你在首屏展开搜索栏后,Siri 便会直接呈现一些你最有可能需要用到的 app。 这里具体会呈现哪些 app 将取决于 Siri 所接收到的一系列隐性反馈,包括你最常用到哪些,你刚刚用过哪些,以及你在每天的这个时段通常会用哪些,等等。
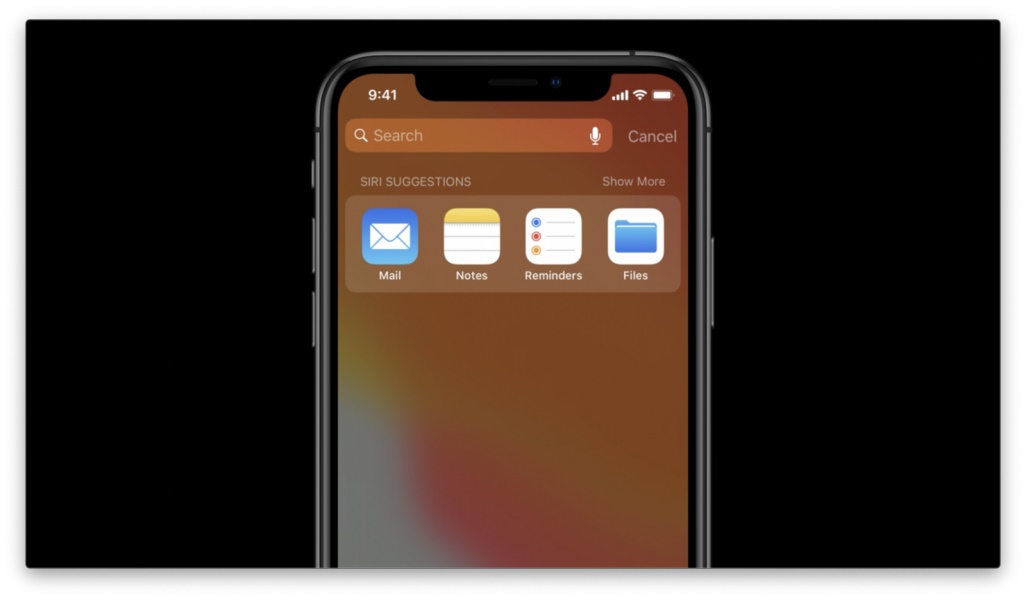
如上图所示,在行车时,我通常会打开「地图」导航,或是打开「音乐」、「播客」听点东西。 而在工作时间,我通常会用到「备忘录」和「提醒事项」等等。
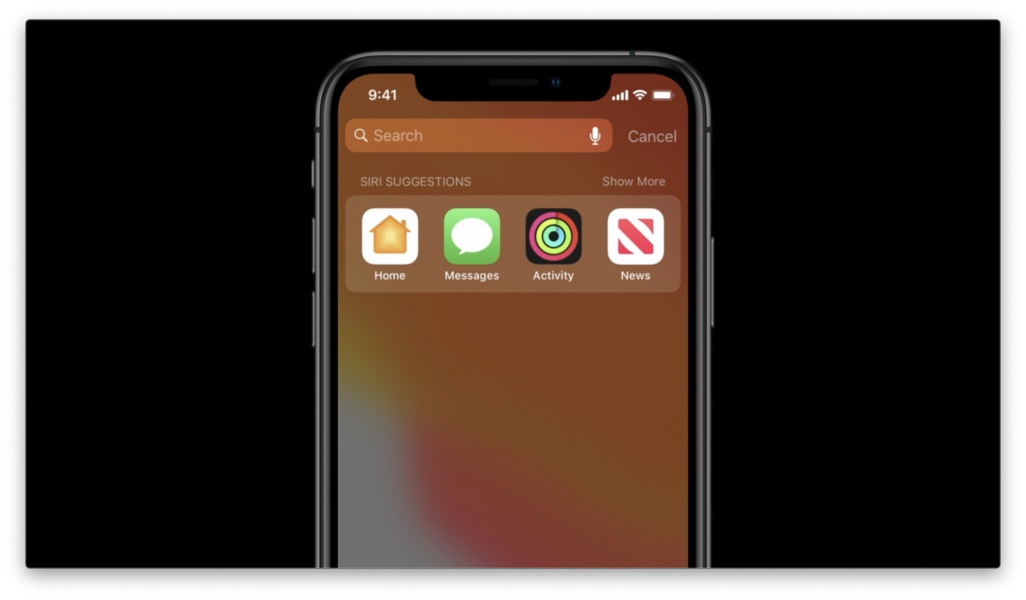
在家里,我通常会用到「信息」和朋友们交流,或是查看「健身记录」和「新闻」等等。
取决于我如何使用我的手机,Siri 会试着判断我在特定场景下的意图,并将我最可能用到的那些主动呈现给我。 设计原则:通过观察人们如何与功能进行互动,来判断他们的习惯与需求意图,进而主动提供相应的个性化体验。 随着时间的推移,Siri 会越来越精准地理解我的意图。除了提供 app 建议,它还会开始尝试为我的各种高频操作提供快捷方式。 譬如在车上时,Siri 会根据我常去的地方或是接下来的会议场所提供导航建议。
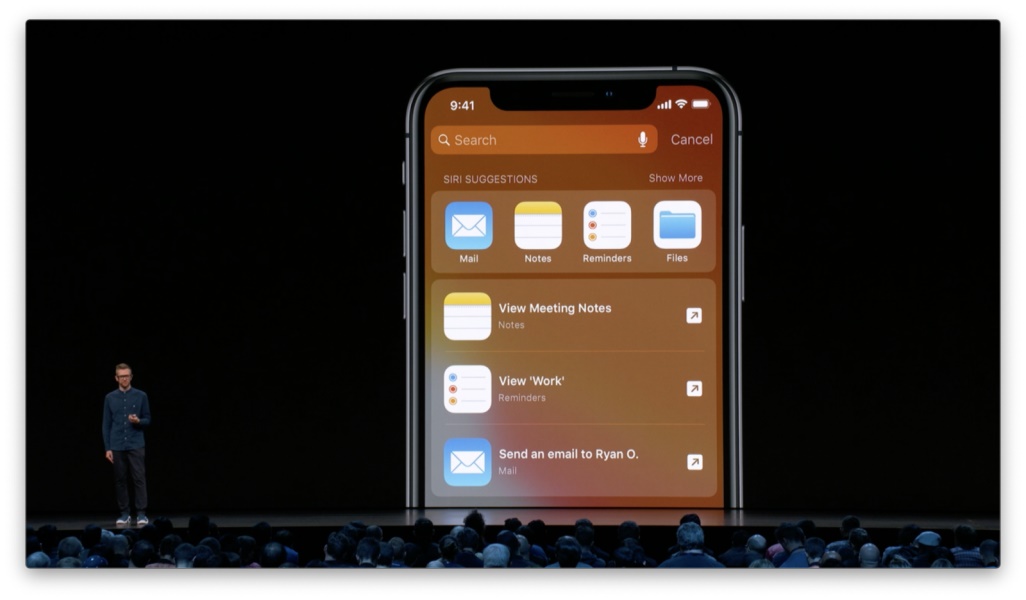
在工作时,它会为我提供工作相关备忘录或提醒事项的快捷方式。
回到家后,快捷方式则变为家居控制或「信息」、「Facetime」。
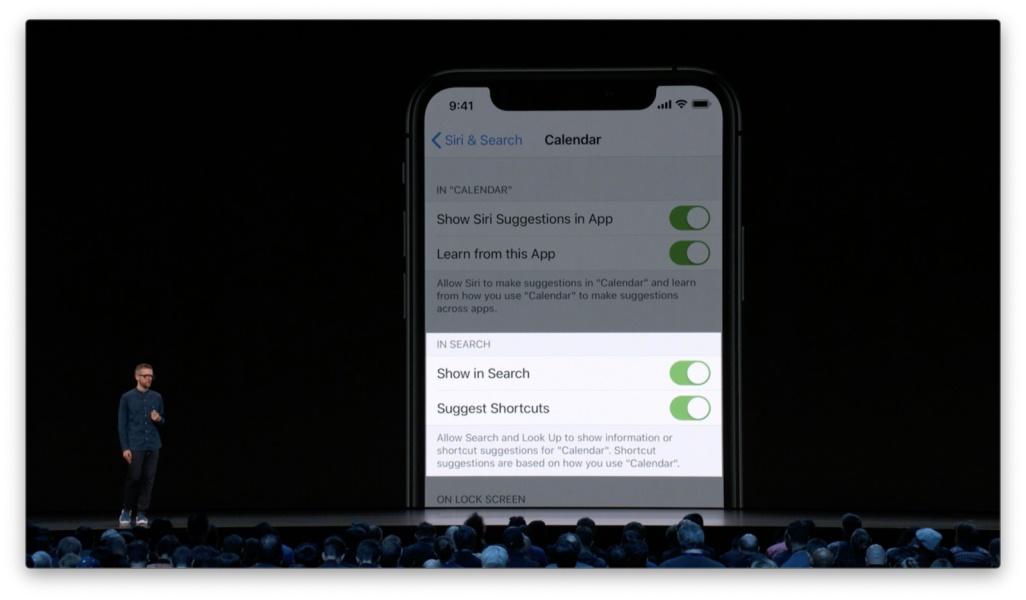
这些快捷方式会在你开始使用新手机或新系统的几天或几周后开始提供。由于 Siri 需要基于隐性反馈来学习你的习惯与意图,因此要达到足够的精确度,势必要花上一定的时间。这不成问题,付出时间成本来提升精确度,比立刻提供不靠谱的建议要好很多。 设计原则:隐性反馈不会带来立竿见影的效果,体验的精确性会随着时间而逐渐提升。 这些个性化建议会在锁屏上出现,其中有可能包含比较敏感的信息。为了尊重隐私,我们会为每个 app 提供相应的设置,允许人们决定是否将相关信息呈现在搜索建议当中。
设计原则:在运用隐性反馈时,要始终考虑到人们的隐私与安全性问题。 除了个性化以外,隐性反馈还可以用于细微之处的体验提升。我们以 iOS 的键盘为例。键盘的每个按键都有其各自的实际点击区域。
通过机器学习,系统可以动态优化这些点击区域,譬如根据你正在输入的单词或是手指的位置来调节点击区域的实际尺寸。
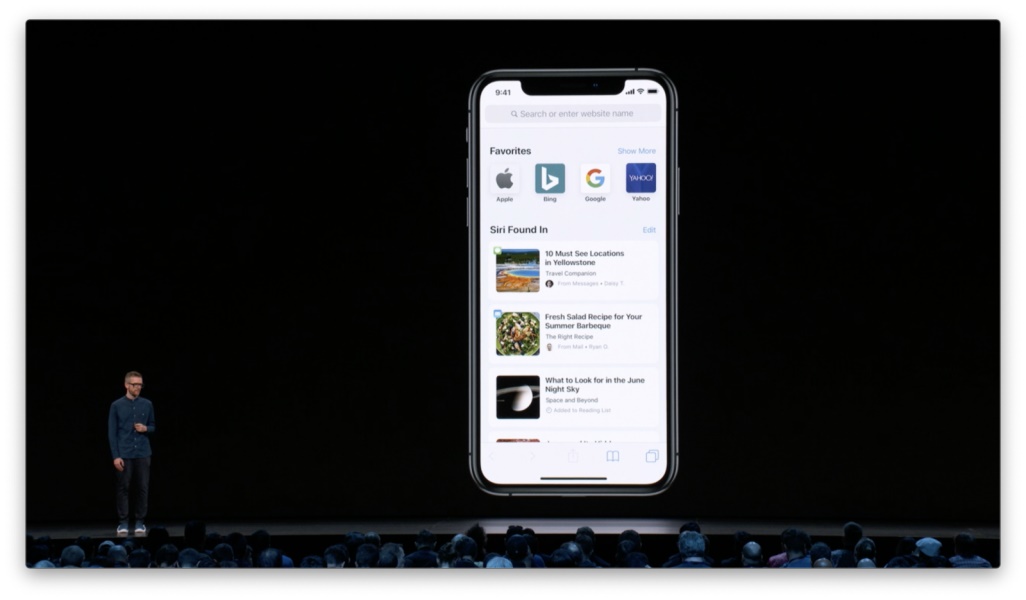
请注意,按键的可视尺寸从不会真正发生变化;但人们会随着时间的推移而感知到键盘正变得越来越精准和个性化。 设计原则:可以通过隐性反馈来逐渐提升交互操作的精准度与舒适度。 再来看 Siri 建议在 Safari 中的运用。Safari 会通过机器学习从信息、邮件、阅读列表、iCloud 标签页等地方收集网页链接,目的是从你的关系链或个人浏览行为当中提取更多你可能感兴趣的网页内容。
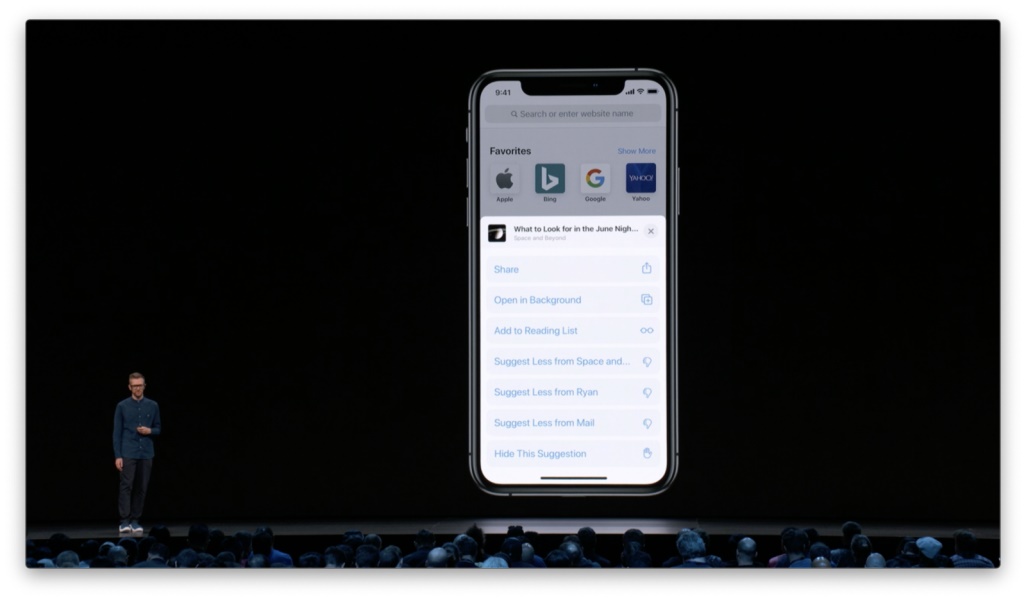
不过偶尔你也会觉得某些建议并不是你想要看到的,譬如一篇你不感兴趣的文章,或是你不够信任的内容出处。如果这些建议都不具备推荐价值,人们就会逐渐对搜索建议甚至是 Safari 失去信任。这是我们必须要避免的状况。 之前我们谈到过如何通过释义信息来解释为什么会推荐特定的内容,但除此之外,我们仍然希望为人们提供手动控制的方式,来标定他们不希望看到的内容。这就是我们接下来要聊的第三类输入类型。 显性反馈显性反馈是指允许用户直接对输出结果进行明确的反馈。
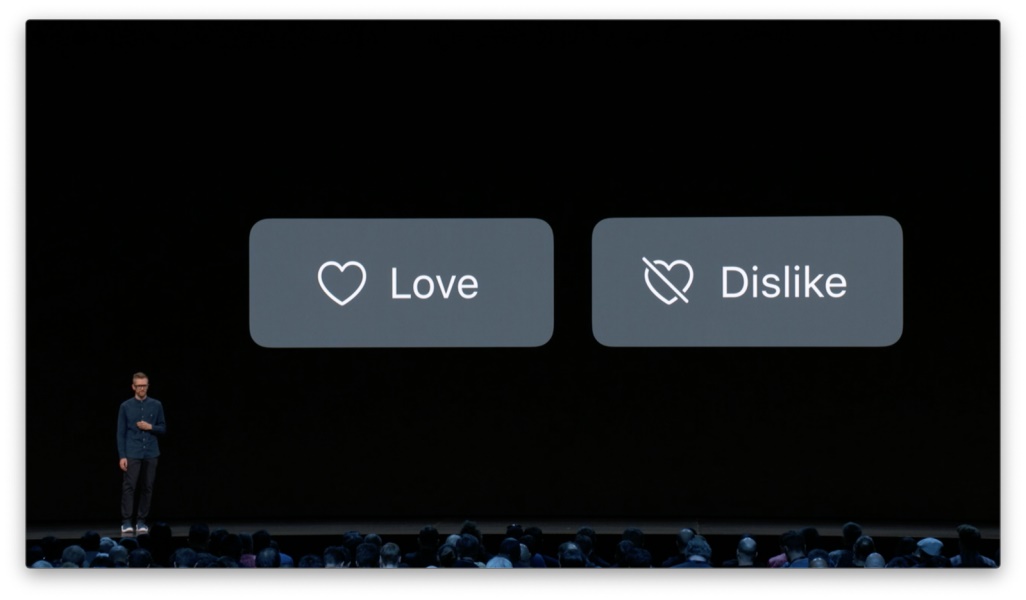
在刚刚 Safari 的例子中,我们可以提供这样的功能,允许用户标定他们不想看到的内容,这样模型便可以从中学习,避免在将来呈现类似的内容。 应该如何设计这样的反馈机制呢?我们时常会见到这样两个操作,「喜欢」和「不喜欢」:
不过即便搭配文字标签,它们会带来的结果依然有些不明。
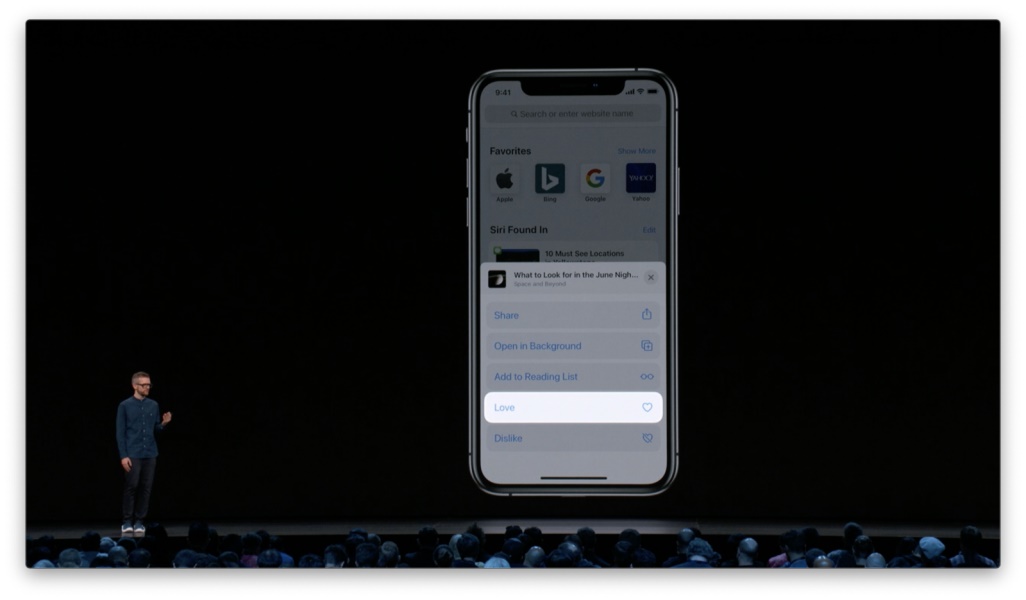
譬如我想对某篇推荐内容进行反馈,于是唤起菜单,看到有个选项叫做「喜欢」。这时我会想,我是不是要对每一篇我喜欢的文章都执行一次这样的操作呢?
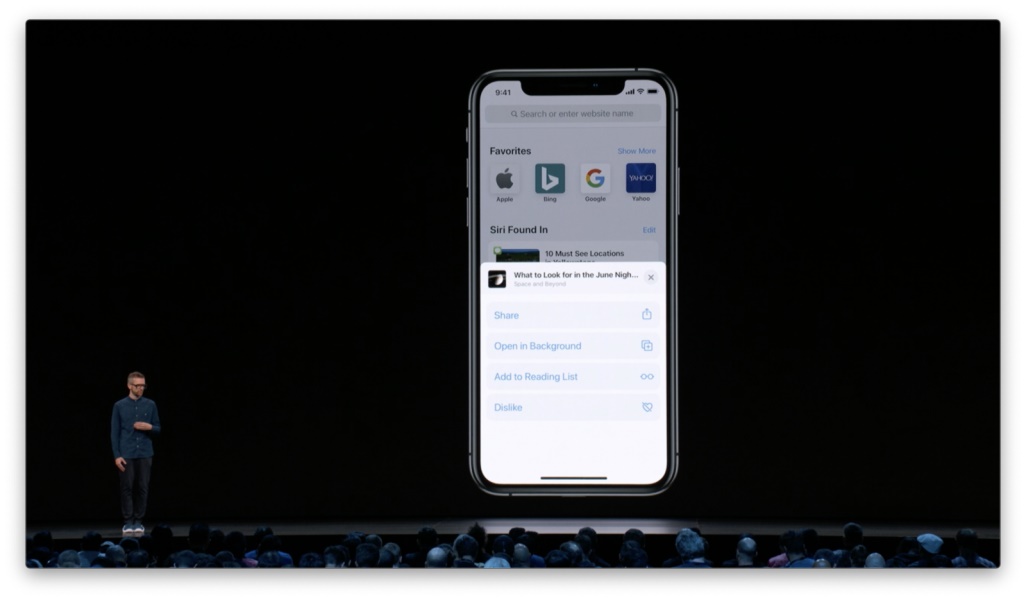
正向的显性反馈会带来额外的交互和认知成本。人们势必会猜测是否需要逐一「喜欢」才能提升推荐的精准度。其实用户对于内容的正向反馈可以更明确地体现在其他行为当中,例如阅读、收藏或分享。 设计原则:尽可能只提供负面反馈方式作为显性反馈。 然而,即便只提供「不喜欢」这一个选项,依然会带来认知上的不明。我不喜欢的是这篇文章,还是作者,还是来源出处,或是分享给我这篇文章的人或 app 呢?我依然会困惑于点击按钮可能造成的结果。
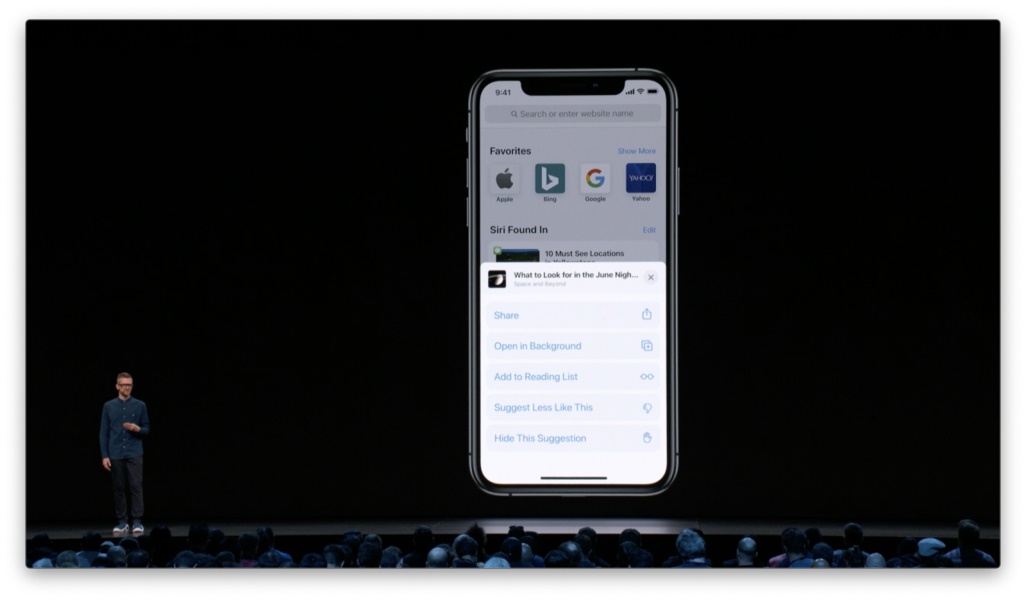
而「减少此类内容的推荐」或「隐藏这条推荐」则更加易于人们对操作结果产生预期。
要想给人们更多的控制权,我们还可以允许他们进行更具体的选择,例如减少特定来源或来自某人的内容推荐。
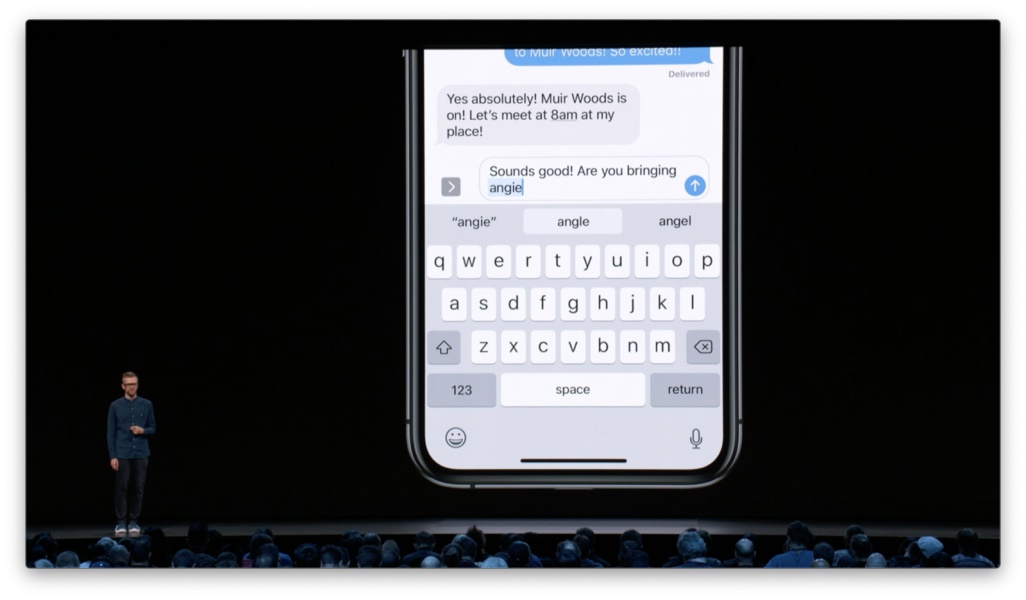
设计原则:在显性反馈中,清晰地描述出操作的含义及结果,并尽可能提供更具体的选项来帮助用户理解和选择。 当然,在我选择了某个负面选项之后,界面应该立刻对我的操作进行响应,移除相应的内容且不再进行推荐。 设计原则:对人们的显性反馈即刻进行响应,并持续保持作用。 显性反馈可以帮助模型减少错误的或是不恰当的输出结果。但对于某些功能来说,显性反馈的方式可能并不适合,甚至是难以实现的。 譬如我在和朋友讨论狗狗安吉时想要输入「Angie」,但在输入「angie」后系统却想将其修正成「angle」。这显然是不合适的。
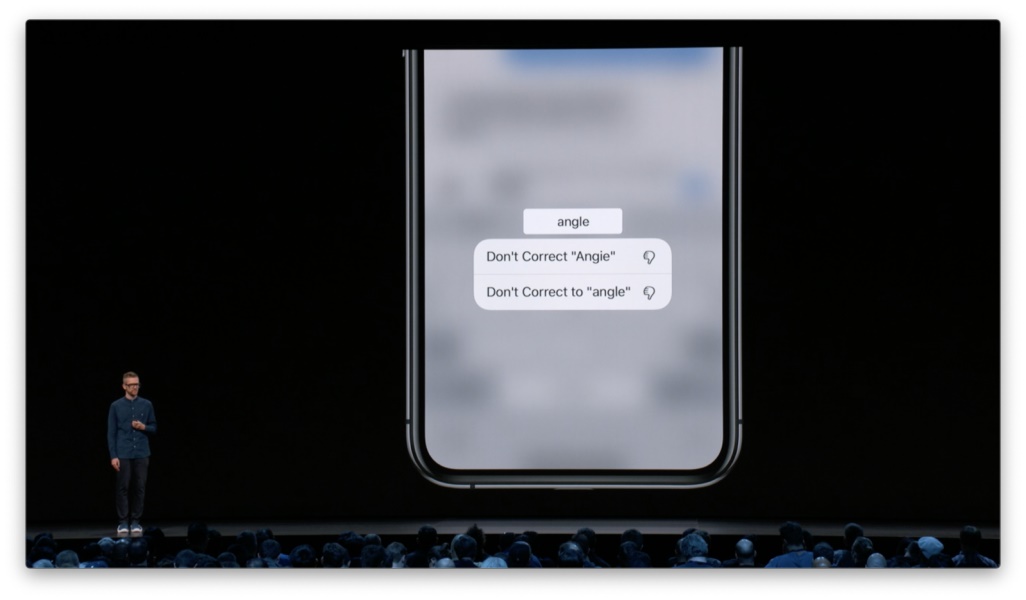
假设我们通过显性反馈的方式为人们提供一个选项菜单。这不仅让人感觉非常异样,而且根本无助于我实现想要的输入。
实际上,我可以选中被系统修正的单词,手动输入正确的「Angie」。系统会学习我的手动修正,并且不会再将我接下来输入的「Angie」更改为其他单词。这就是我们接下来要聊的第四类输入类型。 手动修正手动修正允许人们通过正常的操作方式来自主更正那些错误的输出结果。
何为「正常的操作方式」?在刚刚键盘输入的例子中,我们使用标准的、人人皆知的文本操作方法来重新输入单词,从而更正了系统的错误;期间不涉及任何额外的界面元素,譬如选项菜单等等。这就是「正常的操作方式」。 手动修正可以在不带来额外交互逻辑的情况下对输出结果进行优化。 以「照片」为例。它可以通过机器学习来自动优化照片,例如找到最佳旋转角度和裁切方式。 「照片」提供优化建议的方式非常微妙。你进入照片的编辑模式,选择旋转或裁切工具,照片便会自动进行细微的调整。但它实际上并没有真正进行修改,仅是作为一个简单的操作起点供你选择。如果你觉得自动调整符合心意,直接点击「完成」即可。
如果你不喜欢它的建议,也可以直接通过相关的控件进行手动调整,修正系统的优化方案;系统也会自动退出自动优化模式。
设计原则:
总结这些就是我们希望与各位分享的关于机器学习界面设计的相关模式及设计原则。如你所见,其中覆盖了很多我们长久以来非常熟悉的那些界面元素。
设计方法并非完全新颖,改变了的只是新的技术与使用场景。无论选择怎样的设计模式,都必须确保对人们的尊重。无论释义信息还是显性反馈,都会需要人们付出额外的认知与操作成本,甚至干扰人们的注意力。因此选择设计方法时,必须做到以人为本。
基于机器学习的产品体验设计,需要考虑的远不止界面输出层面。数据,指标,输入,输出,这四个方面的要素共同决定了产品能否为人们提供易于理解、符合直觉的体验。
正如我们在此次分享开头时所说,我们正在或将要打造的产品及体验都无法脱离机器学习而存在。我们看到了诸多案例,包括如何借助机器学习来帮助人们保持注意力,如何提供更优质的推荐内容,如何在恰当的时间呈现最符合场景的信息,如何自动完成常规任务。
机器学习所能做到的远不止这些,我们可以借助它的力量来提升生存的质量,例如通过追踪运动行为来督促我们保持健康,通过计算机视觉及语音控制的运用来帮助盲人「听」到景象,通过侦测心率来判断健康问题等等。当你将技术与你们所秉承的价值结合到一起时,你就可以创造出能够提升人类生存质量的产品体验。
欢迎关注作者的微信公众号:「Beforweb」
手机扫一扫,阅读下载更方便˃ʍ˂ |





















@版权声明
1、本网站文章、帖子等仅代表作者本人的观点,与本站立场无关。
2、转载或引用本网版权所有之内容须注明“转自(或引自)网”字样,并标明本网网址。
3、本站所有图片和资源来源于用户上传和网络,仅用作展示,如有侵权请联系站长!QQ: 13671295。





最新评论







